1.概述
K-Means是聚类算法中的一种,其中K表示类别数,Means表示均值。顾名思义K-Means是一种通过均值对数据点进行聚类的算法。K-Means算法通过预先设定的K值及每个类别的初始质心对相似的数据点进行划分,并通过划分后的均值迭代优化获得最优的聚类结果。
为了提升K-Means聚类的计算效率,产品支持分布式系统计算K-Means。当输入节点数据集是“数据集市数据集”时就是分布式计算的。
2.配置参数
拖拽一个数据集和一个K-Means聚类节点到画布,连接数据集和K-Means聚类节点。
添加K-Means聚类模型到实验后,可通过右侧的“配置项目”页面,对模型进行设置。
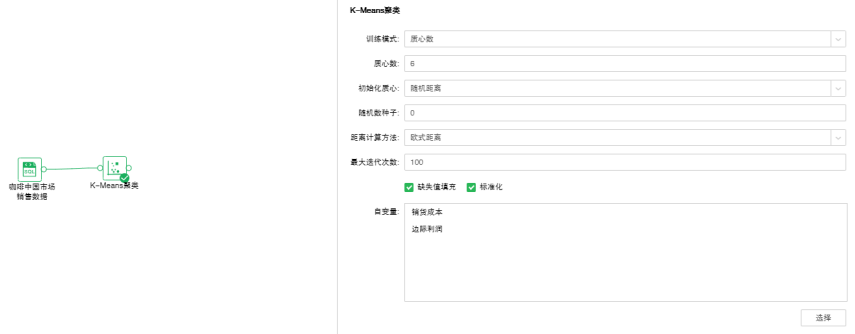
【训练模式】包含质心数、质心数范围。
【质心数】质心的个数。
【质心数范围】质心个数的范围。
【初始化质心】初始化质心的方法包括:随机距离、Kmeans++。随机距离是所有质心都是随机选取的。Kmean++是第一个质心是随机选取,其它质心按距离选取,距离其它质心越远被选中的概率越大。
【随机数种子】生成随机数的种子。默认值是0。
【距离计算方法】包括两种方法:欧式距离、余弦距离。欧式距离是两个数据点的实际距离。余弦距离是用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小的度量。
【最大迭代次数】迭代计算的最大次数,最终算出稳定的质心数。默认值100。
【缺失值填充】用自变量列平均值填充此列的空值。默认是填充的。
【标准化】对自变量标准化,默认标准化方式是Z-Score标准化。
【自变量】从选择列对话框中选出需要作为自变量的字段。
3.查看模型结果
K-Means聚类模型运行成功后,会自动切换到“结果展示”页面,查看实验模型的结果,再次运行时则不会自动切换,可以手工切换至结果展示页面。
质心数为6,样本个数150,K-Means聚类展示结果如下:
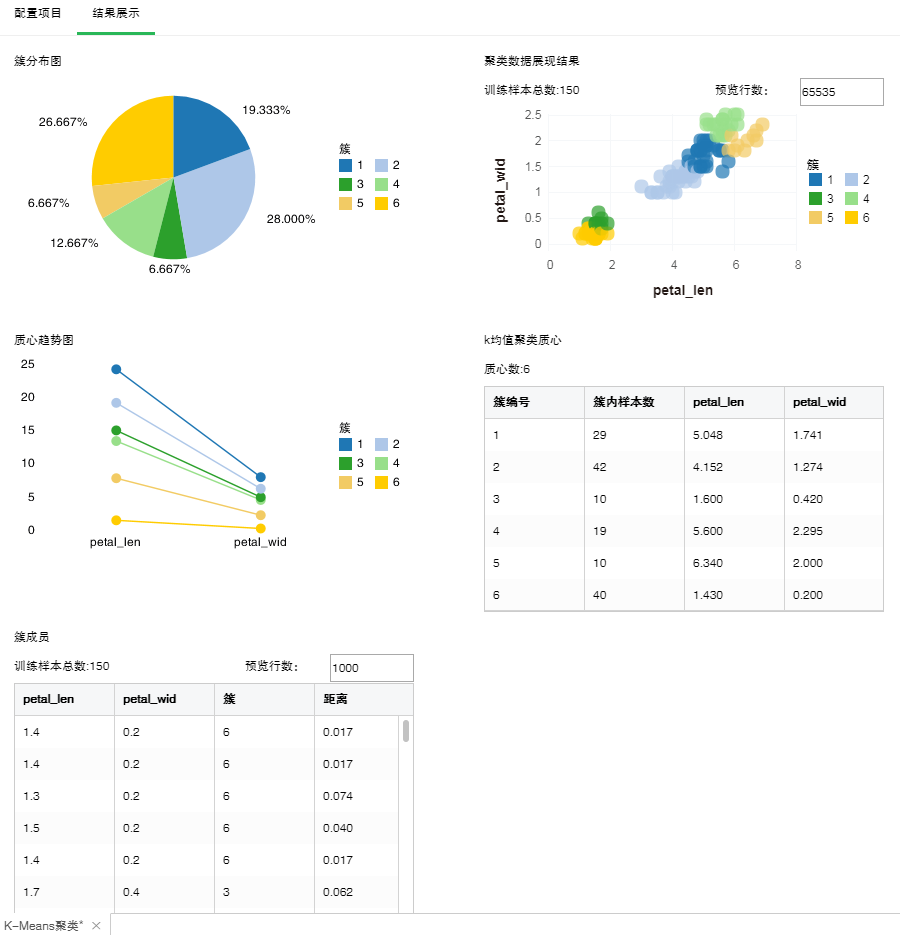
•簇分布图
簇内的样本个数占总样本个数的比例。
•质心趋势图
各个质心在自变量上的变化趋势。
•聚类数据展现结果
根据前两个列绘制的聚类之后的散点图。
【预览行数】图表默认展示65535行数据,可修改此值改变预览行数。
•k均值聚类质心
质心在自变量上的取值。
•簇成员
样本分别属于哪个簇,距离质心的距离。
【预览行数】默认预览行数是1000,可修改预览行数。
【簇】分类编号。
【距离】不同距离计算方法计算出的每条样本到最近质心的距离值。