1.背景介绍
海关是依据本国(或地区)的法律、行政法规行使进出口监督管理职权的国家行政机关,是商品进口的重要防线。海关检测主要以人工查货、数据统计的传统方式完成。由于进口货物种类和数量庞大,但人力物力有限,所以查货只能以抽检的形式进行,如果能准确定位高风险货物,将对海关的检测有很大的帮助。
2.数据说明
数据是为实验构造的查验记录信息,且已经进行完全脱敏,共计11960条记录。数据字段描述如下表所示。
字段名称 |
中文名称(单位) |
字段描述 |
数据类型 |
|---|---|---|---|
Duty_paragraph |
税号 |
进口货物对应的税号 |
数值型 |
Label |
临时减免标志 |
进口货物临时减免标志 |
|
Tax_rate1-6 |
税率1-6 |
货物进口时对应的6个税率 |
|
Requirement01-31 |
监管要求01-31 |
货物进口时的31个监管要求 |
|
Score |
总分 |
货物风险评分(正比) |
3.方案介绍
首先,根据项目背景介绍,整个问题是一个预测风险评分的问题,可以将其抽象为一个回归问题,数据集中的总分字段,就是建模采用的目标值。
LightGBM回归是一种高效的梯度提升框架,适用于大规模和包含很多个特征的高维数据集。它采用了基于直方图的算法来加速训练过程,具有较低的内存消耗和更快的训练速度。
4.方案分析
数据预处理:类似缺失值填充、归一化、去重等对数据直接进行处理的操作被称为数据预处理。数据预处理拥有加速模型的训练速度、提高模型训练准确度、防止误差数据影响模型的训练效果、防止空数据影响模型正常训练等优点。
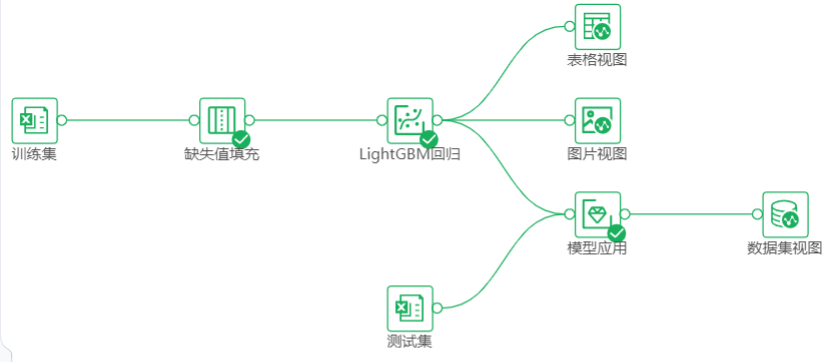
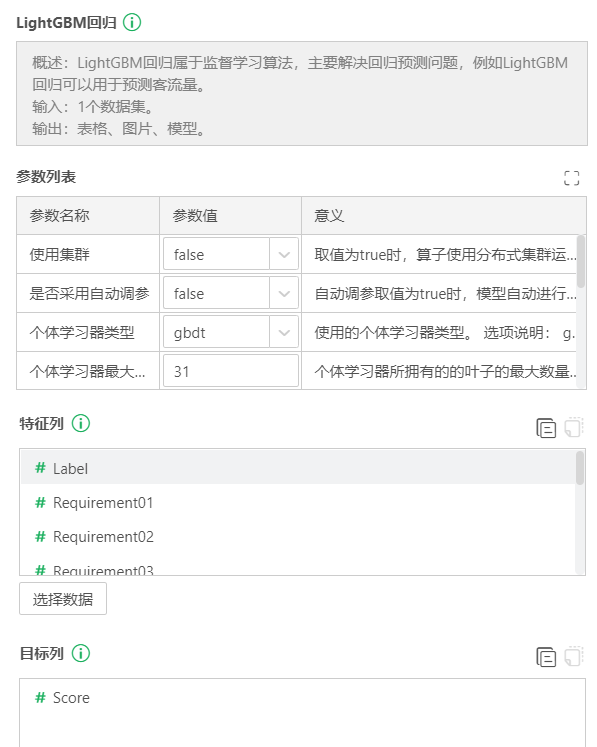
参数配置:按需求填写参数值。
字段选择:如前所述,有监督算法需要指定自变量字段和因变量字段。点击特征列和目标列下方的选择数据按钮。再弹出的字段列表中选择相应的字段。
5.结果说明
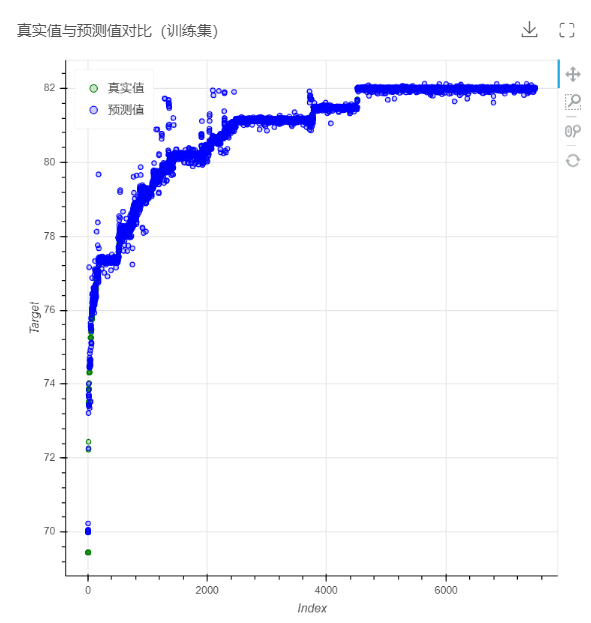
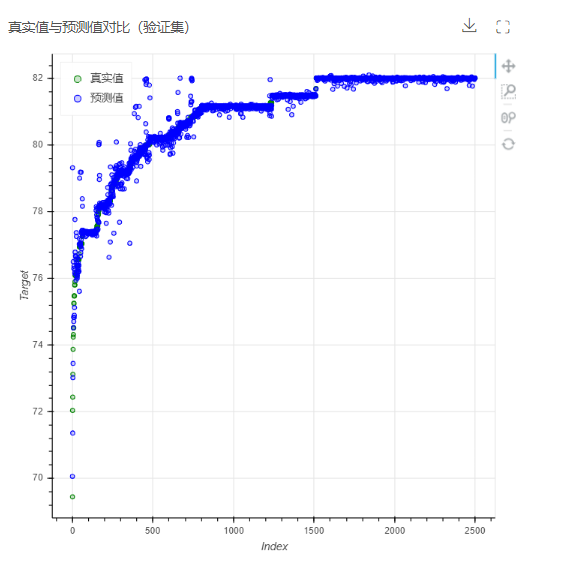
当前项目的工作流,LightGBM回归算子将输出模型性能指标、真实值与预测值对比图。
1.模型性能指标:训练集和验证集上的性能指标:MSE、RMSE、MAE、EVS、R2、Adjusted R2。其中MSE、RMSE、MAE是不同计算方式下的误差指标,越接近0越好;EVS、R2和Adjusted R2取值都属于[0,1]中,且数值越大越好。具体指标值如下图所示。

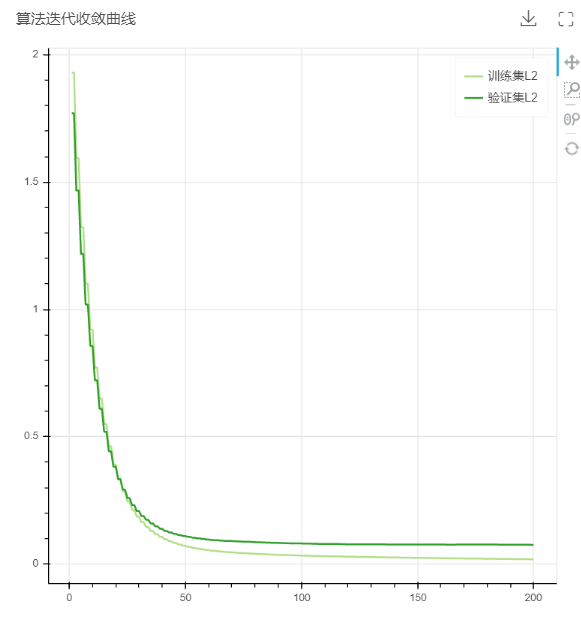
2.算法迭代收敛曲线:用于直观地观察模型训练过程中收敛的情况。在这类图中,模型刚开始训练时往往会拥有较高的损失值,而随着模型训练次数增多,模型性能越好,使得模型的损失值越来越低。曲线递减代表模型仍在训练,没有明显的上升、下降趋势,如在某个值附近波动代表模型训练遇到瓶颈(要么代表模型训练成功可以投入使用,要么代表模型参数仍需要优化调整),曲线递增则代表学习率等参数设定不合理,需要针对性地调整。
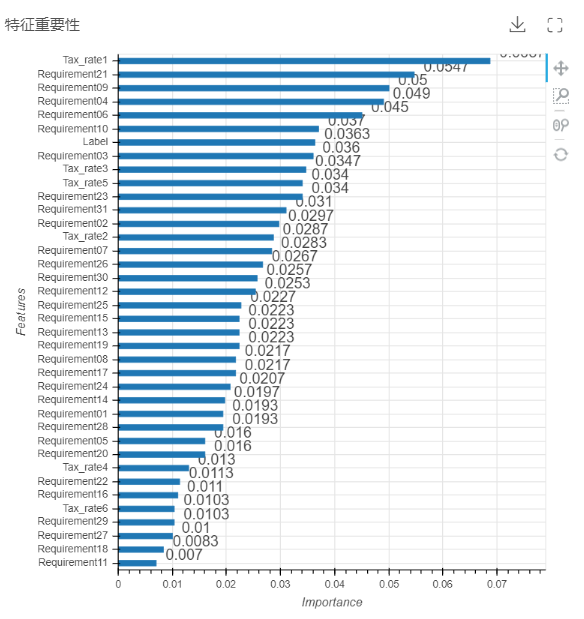
3.特征重要性直方图:特征重要性展现了每个自变量(特征)对于模型的影响大小,并对它们进行降序排列,使得研究者能够直观便捷的了解每个特征在模型中发挥作用的大小。
4.平行坐标图:平行坐标图是一种通用的可视化方法,能够用于探索高维或多元数据的分布情况。颜色的深浅代表了数据分布情况,颜色越深代表该区间上的数据分布越多。
5.真实值与预测值对比图:用于直观地观察真实值与预测值的分布情况。