首先,在左侧导航栏选择深度分析,进入深度分析模块。根据页面提示信息点击左侧顶部的![]() 图标,进入实验页面。在页面的右侧可以看到新建Auto Model模型图标。
图标,进入实验页面。在页面的右侧可以看到新建Auto Model模型图标。
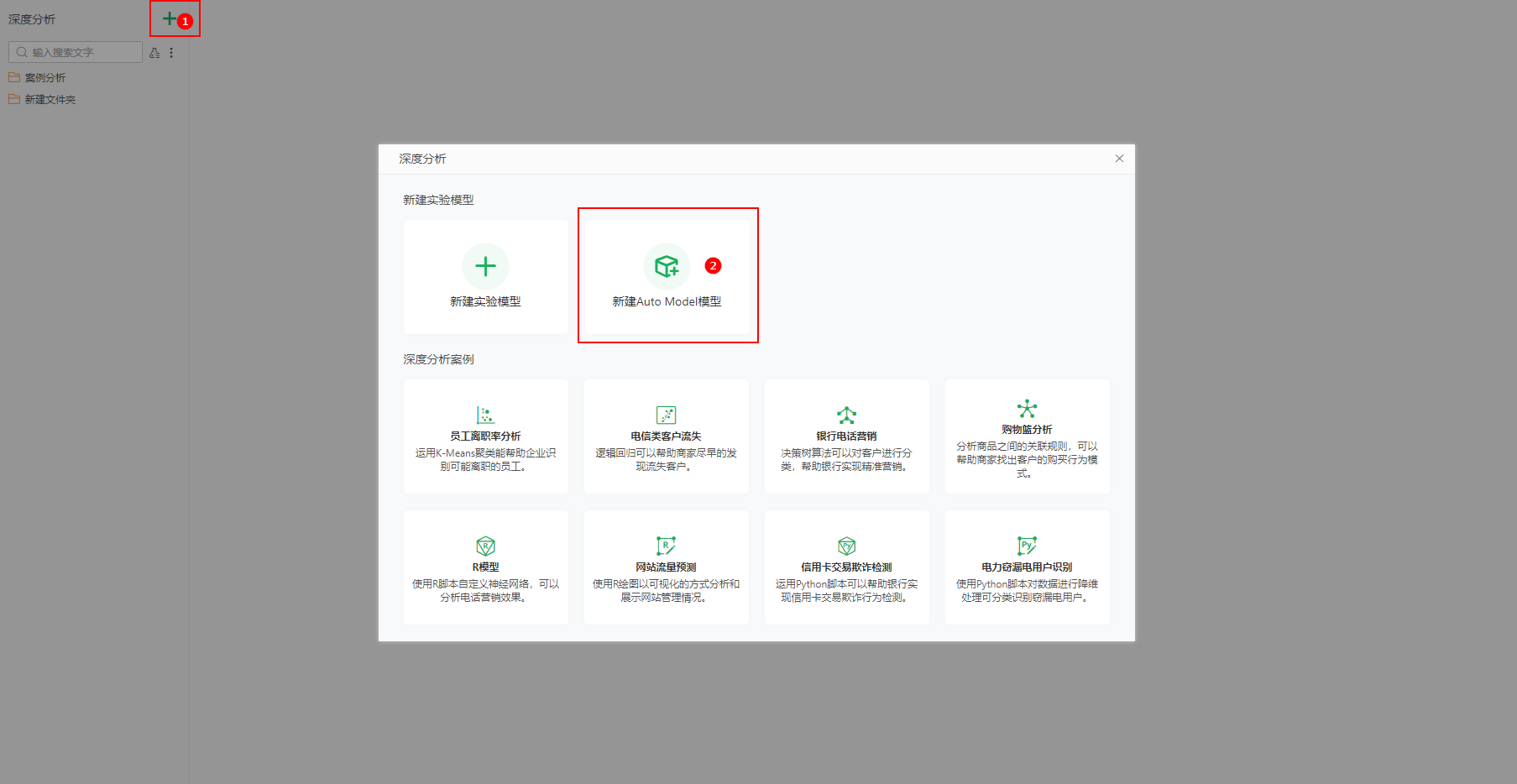
点击图标,进入创建Auto Model模型界面,可以看到创建过程共分为六步。
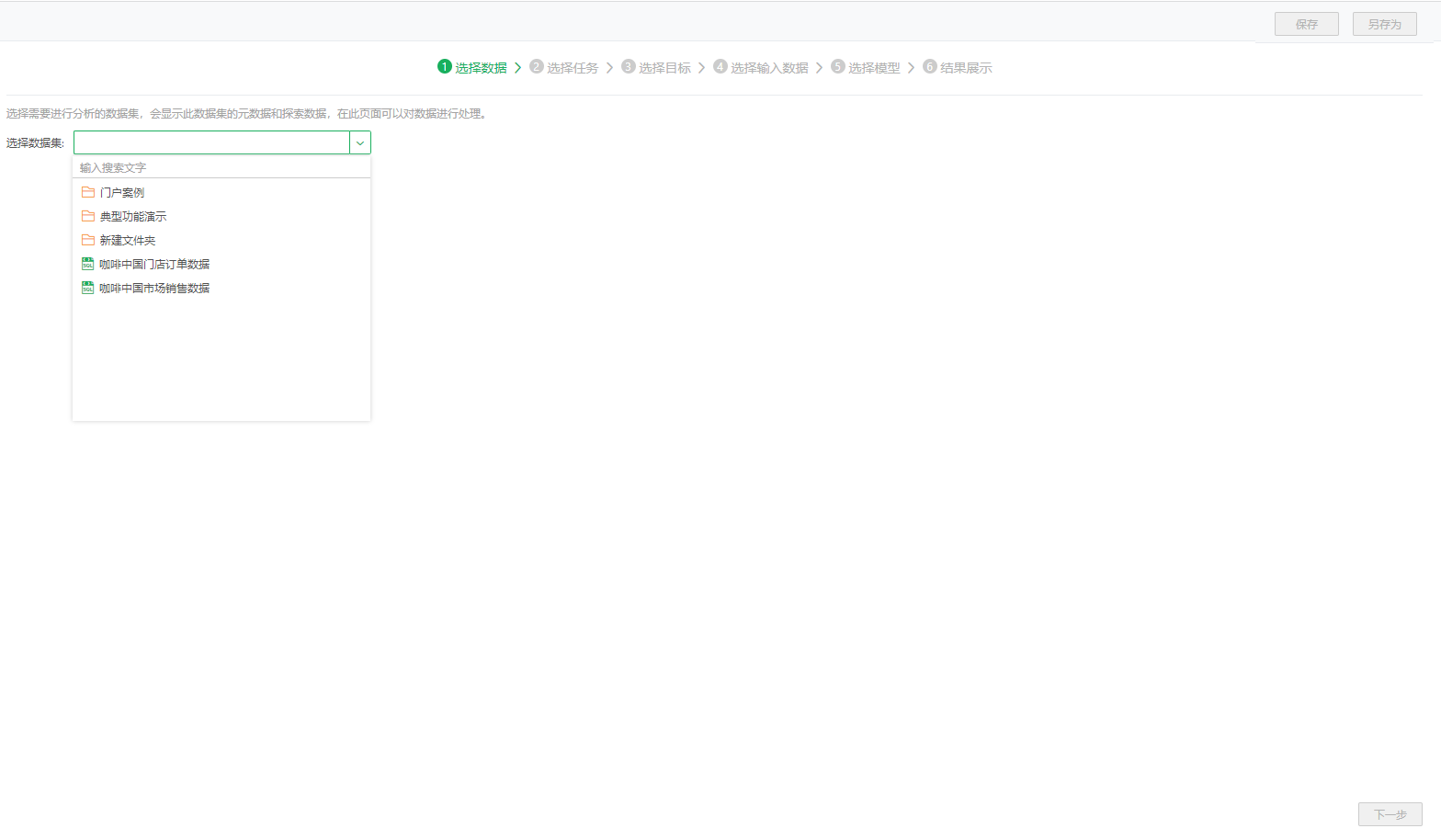
1)第一步,选择数据集。
点击下拉框,在下拉列表中选择需要进行分析的数据集,包含的数据集与数据集列表中一致。(如第一次学习使用功能,也可以使用产品自带的案例数据集,这里我们选择咖啡中国市场销售数据。)
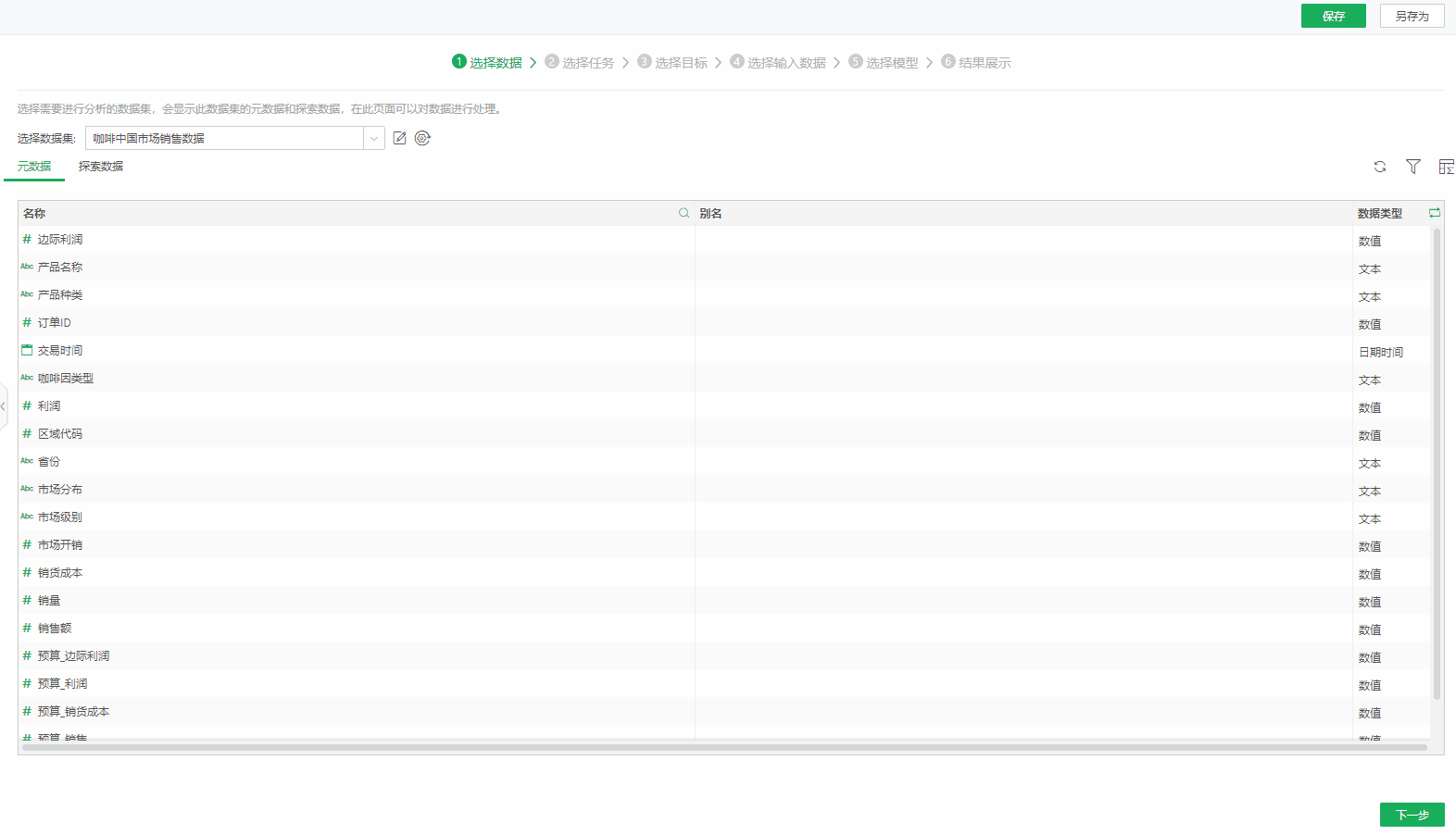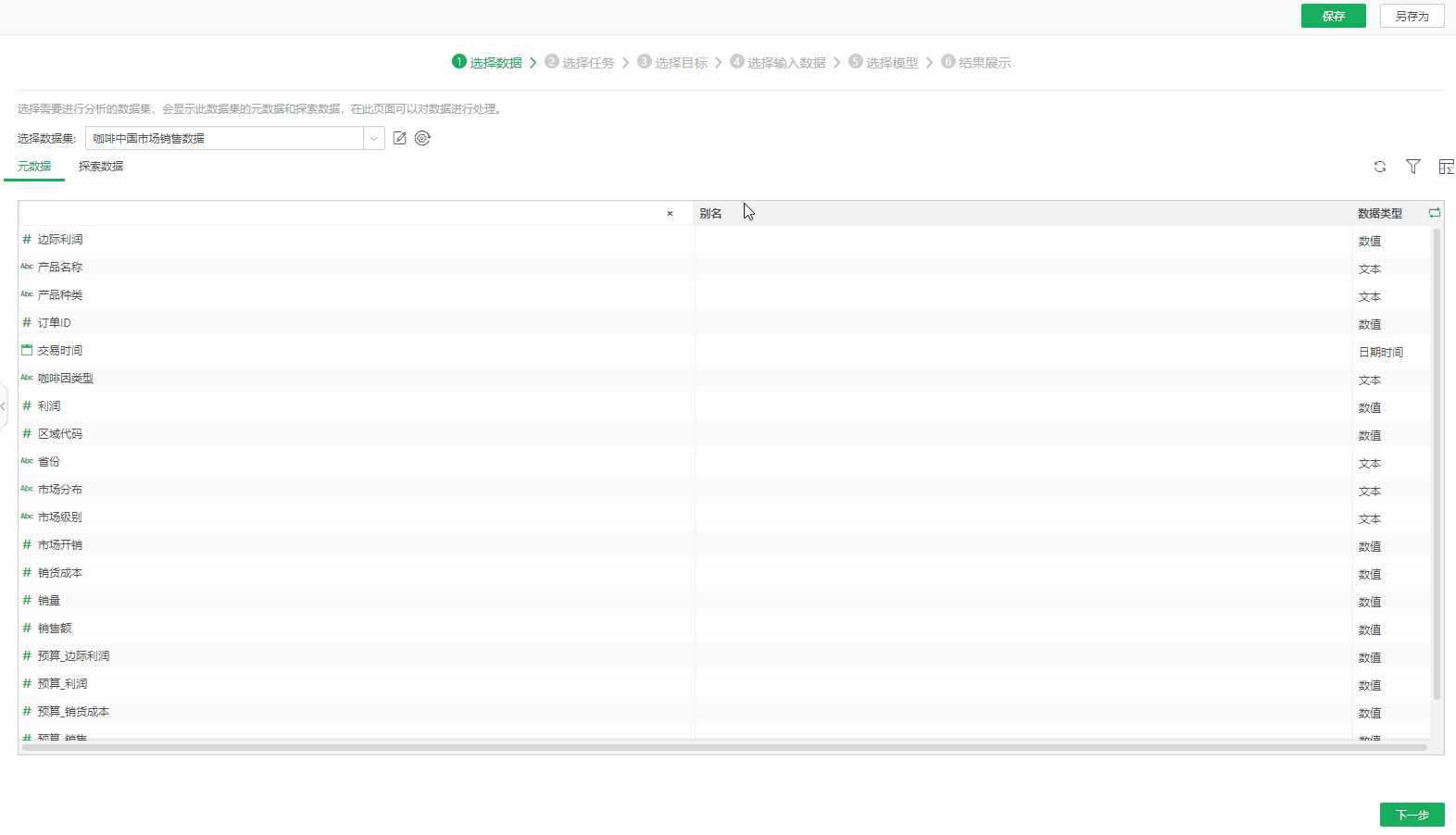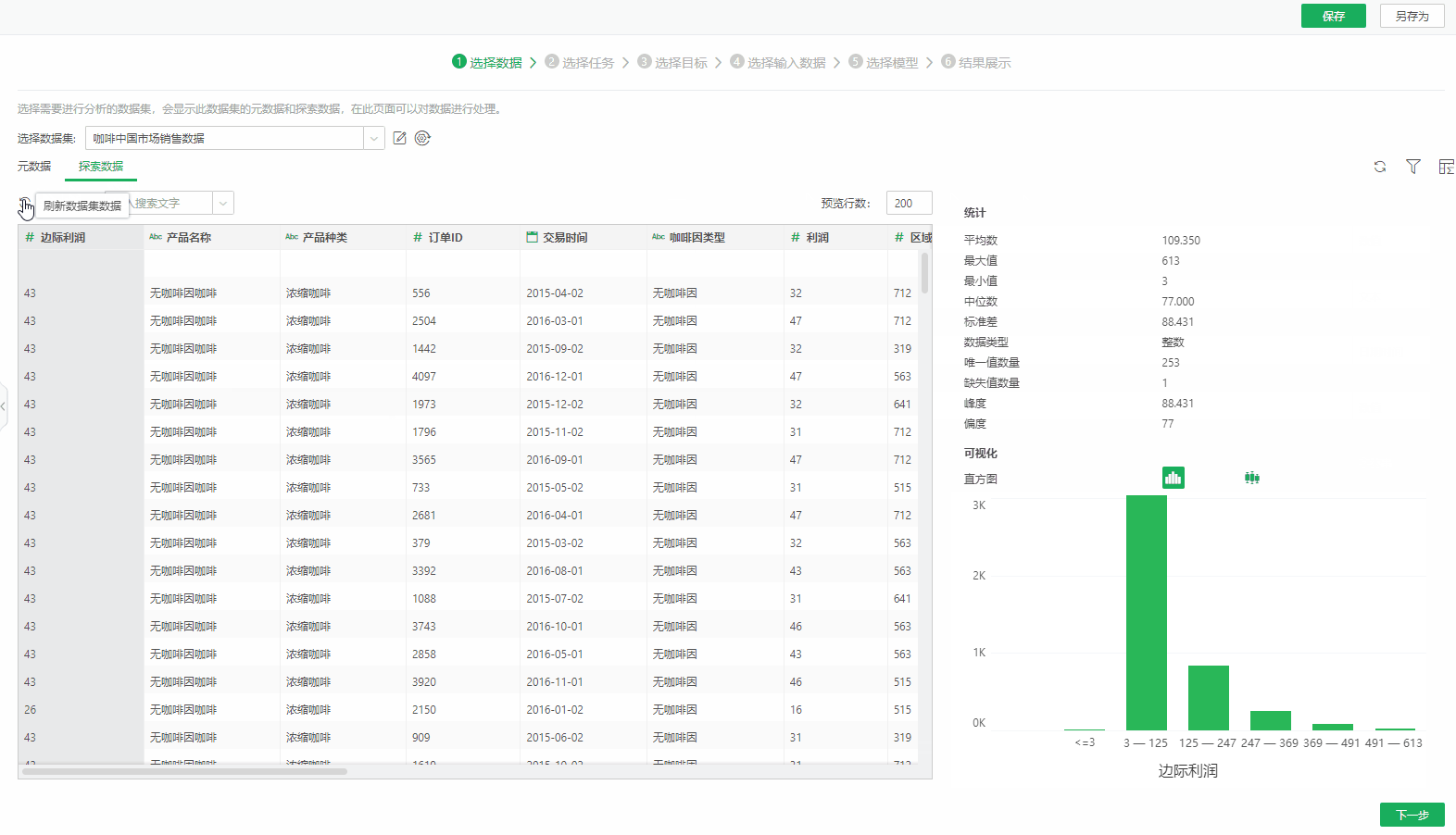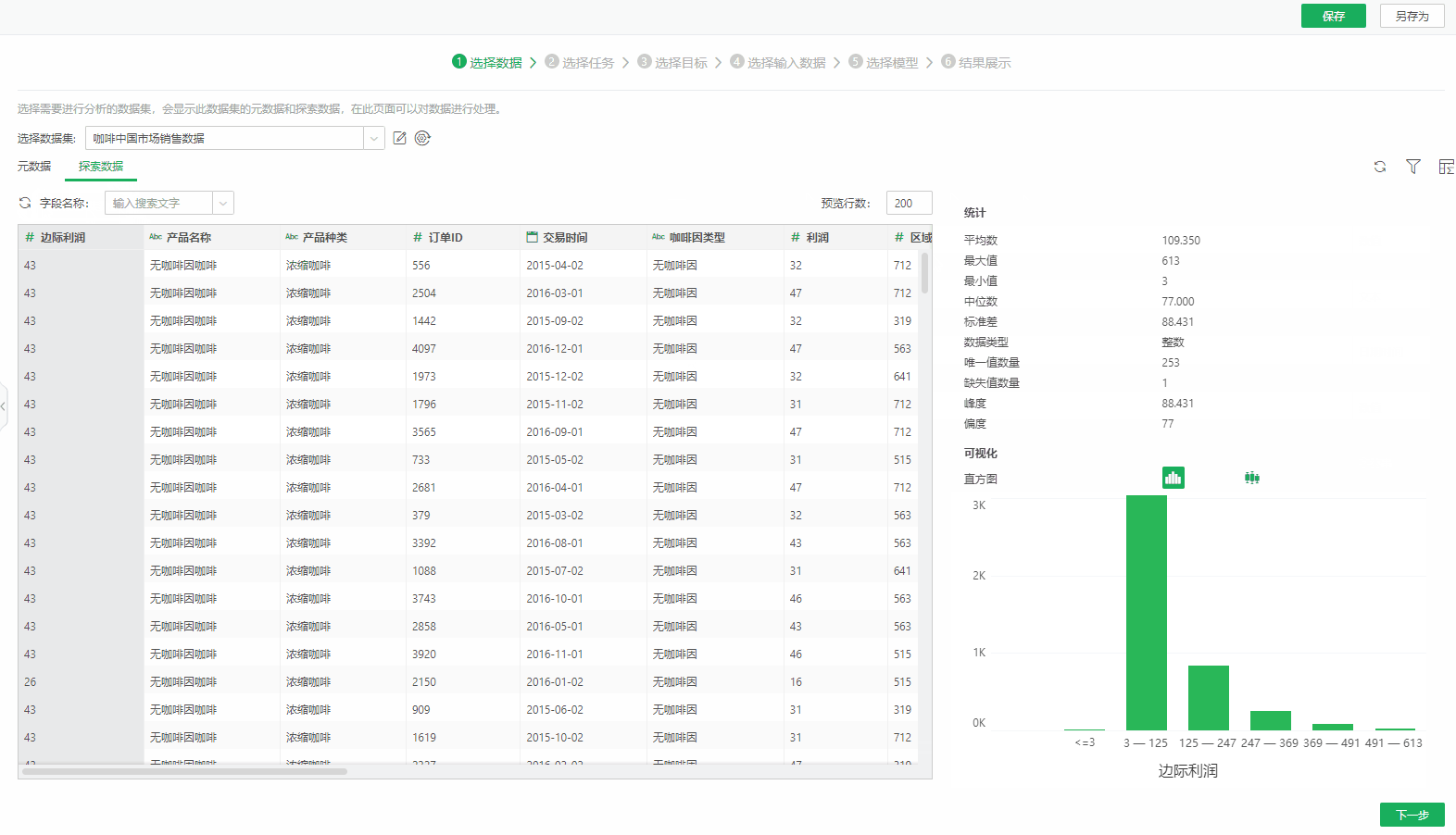
选择数据集后,会显示数据集的元数据和探索数据。可以查看和编辑数据集数据,如刷新、添加过滤、显示总行数。在元数据选项卡页面,可以搜索字段名称、切换数据类型查看、数据集,查看列来源。在探索数据选项卡页面,可以刷新数据集数据、搜索字段、排序字段、查看字段统计数据、可视化图等,方便用户了解和治理数据。
2)第二步,选择任务。
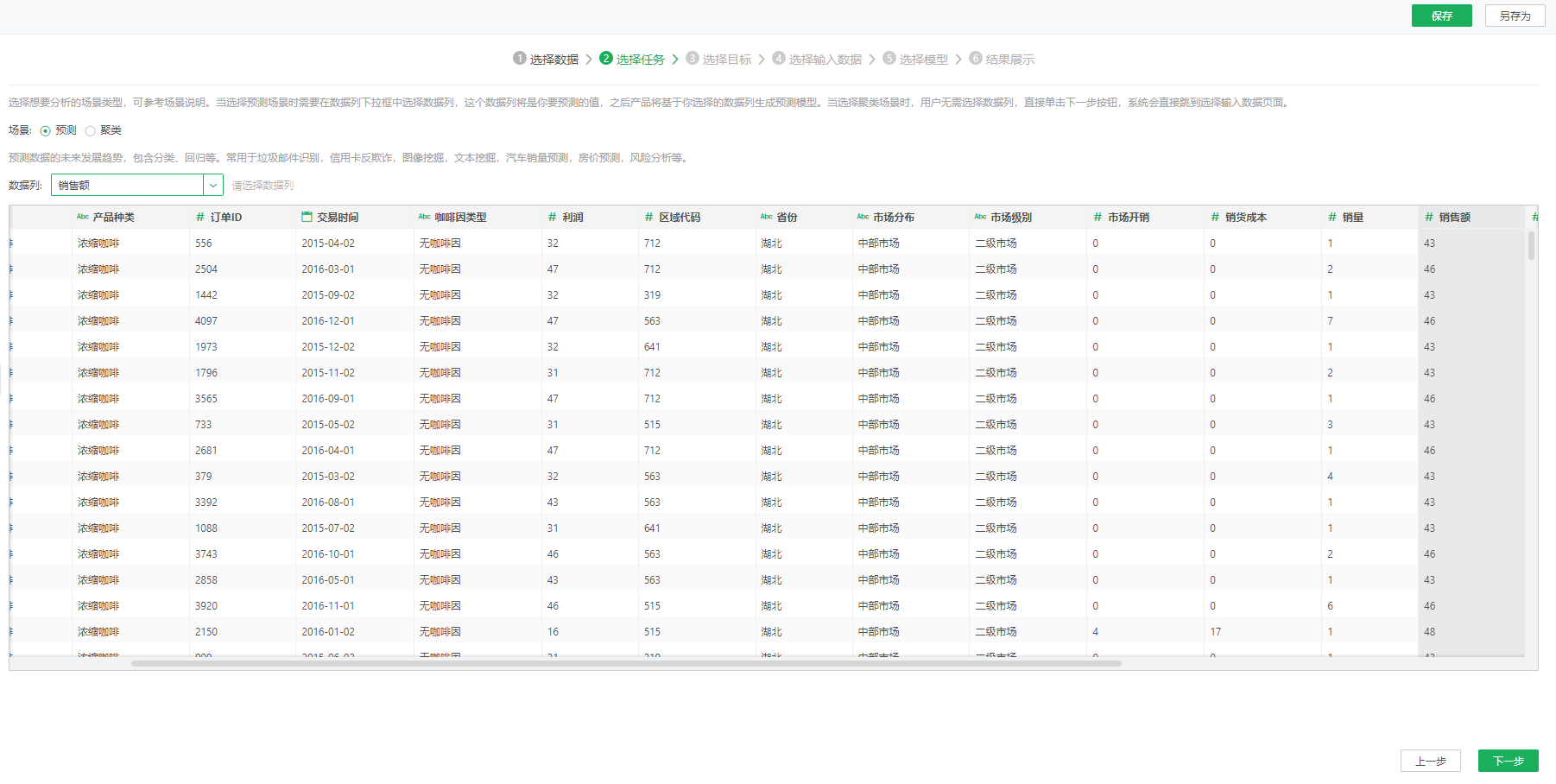
完成数据选择后,点击下一步,进入选择任务页面。选择任务包括选择场景和选择数据列,其中场景分为两个:预测和聚类。预测场景主要应用于预测数据的未来发展趋势,包含分类、回归算法,常用于垃圾邮件识别、信用卡反欺诈等,产品中提供的案例分析-信用卡交易欺诈检测就是其典型应用场景。聚类场景是将对象的集合分成由类似的对象组成的多个类,常用于员工离职分析、营销策略、用户画像等,可以参考产品中提供的案例分析-员工离职。在这步,用户可以根据需要选择场景,当选择预测场景时需要选择数据列,这个数据列将是你要预测的值,之后产品将基于你选择的数据列生成预测模型。这里我们选择预测场景并选择“销售额”数据列,选择的数据列会高亮显示。
➢说明:
如果是选择聚类场景,则不需要选择数据列。
3)第三步,选择目标。
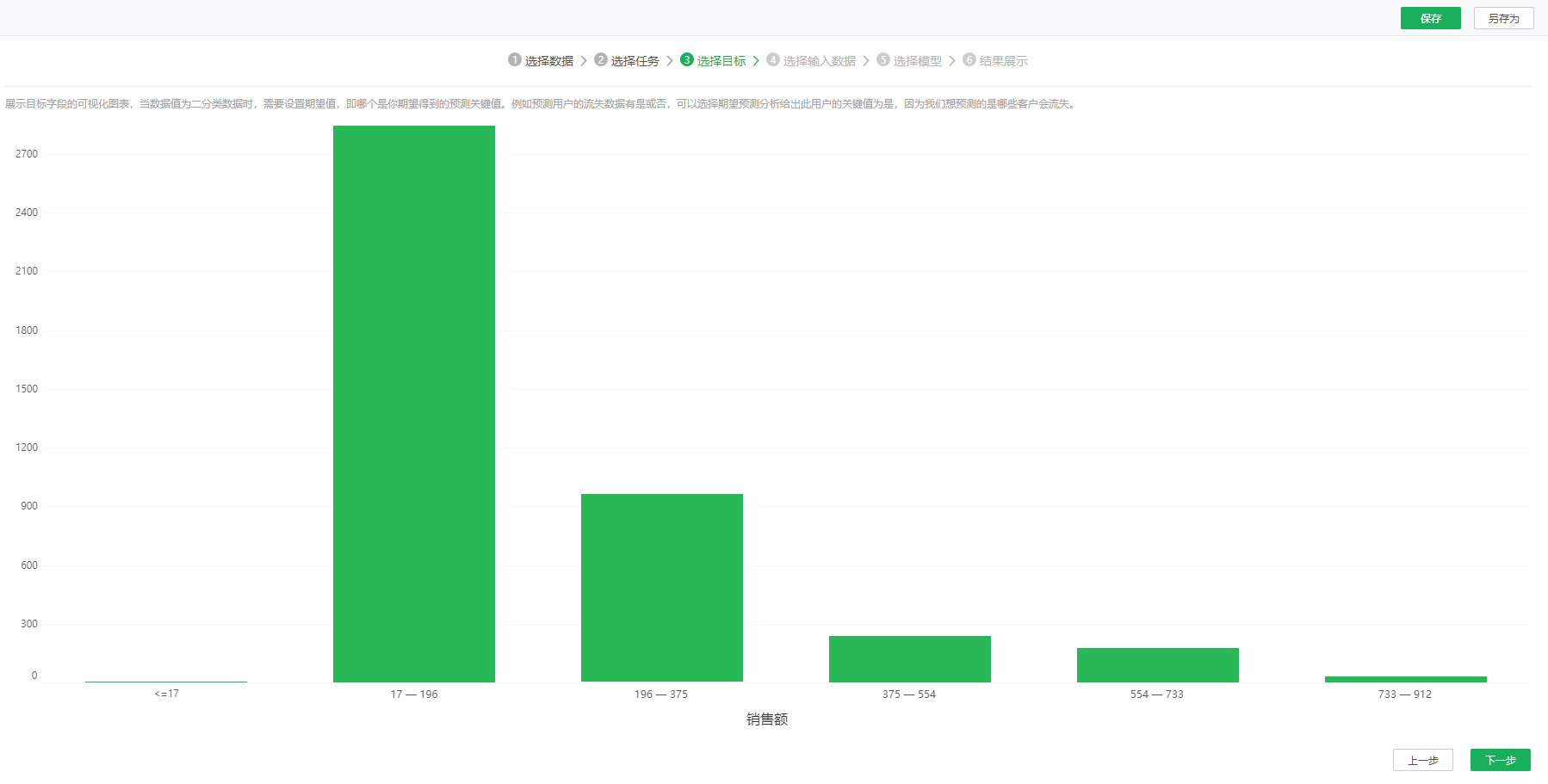
点击下一步,进入到选择目标页面,用户可以预览目标字段,按选择的数据类型展示可视化图表,当有两个数值时,可以选择期望值,否则置灰不可用。
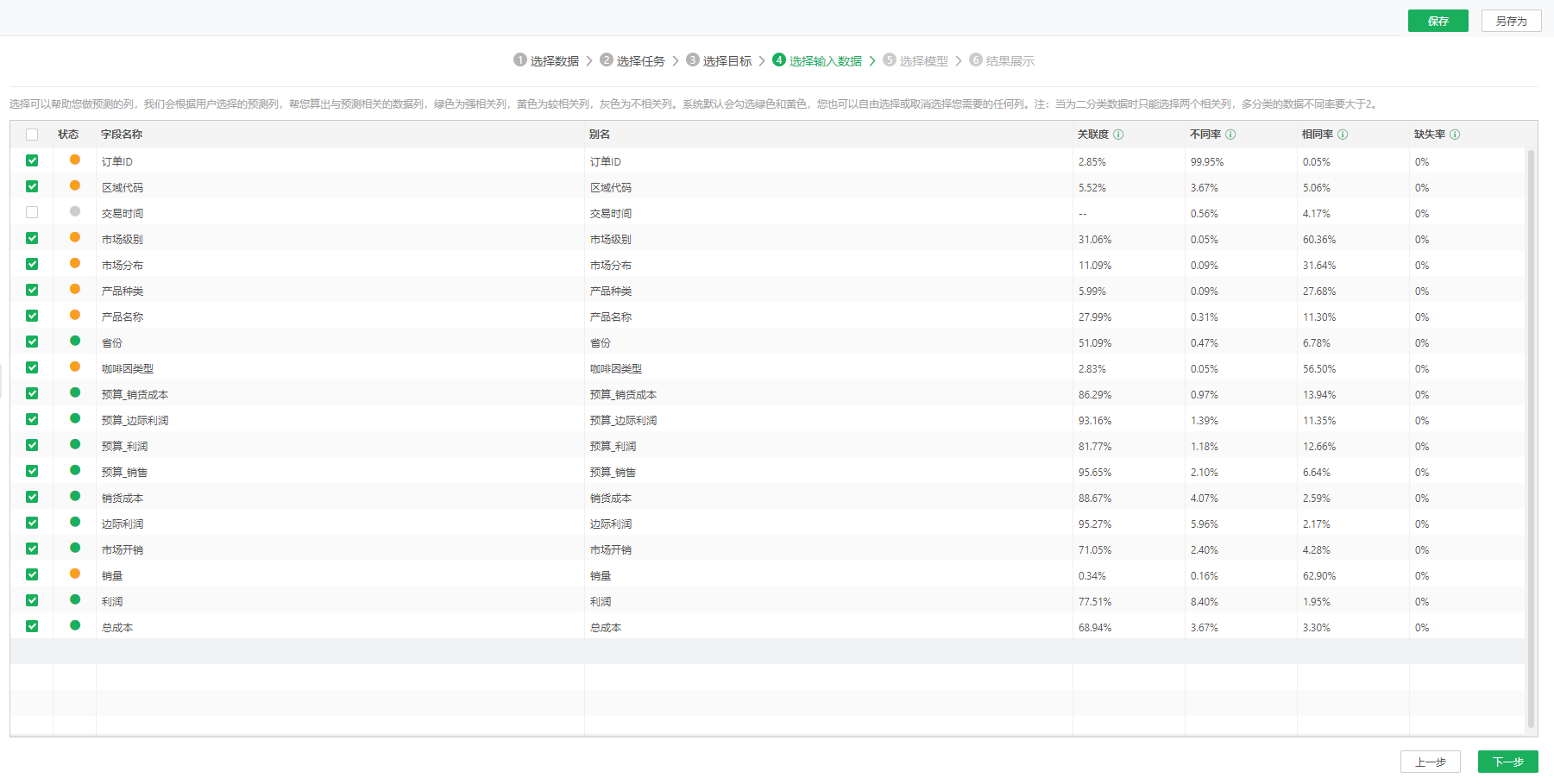
4)第四步,选择输入数据。
点击下一步,进入到选择输入数据页面,可以看到每个字段都有一个状态标识。绿色为强相关列,黄色为较相关列,灰色为不相关列。系统会默认选择绿色和黄色,灰色一般不选择,因为与预测的数据关系不大。列表中会显示每个字段的关联度、不同率、相同率和缺省率,用户也可以参考这些值选择针对目标列需要输入的数据,建议选择关联度高的数据。如果缺省率太高,说明没有数据的行太多,不建议选择。对于小白用户,可以使用默认选择。
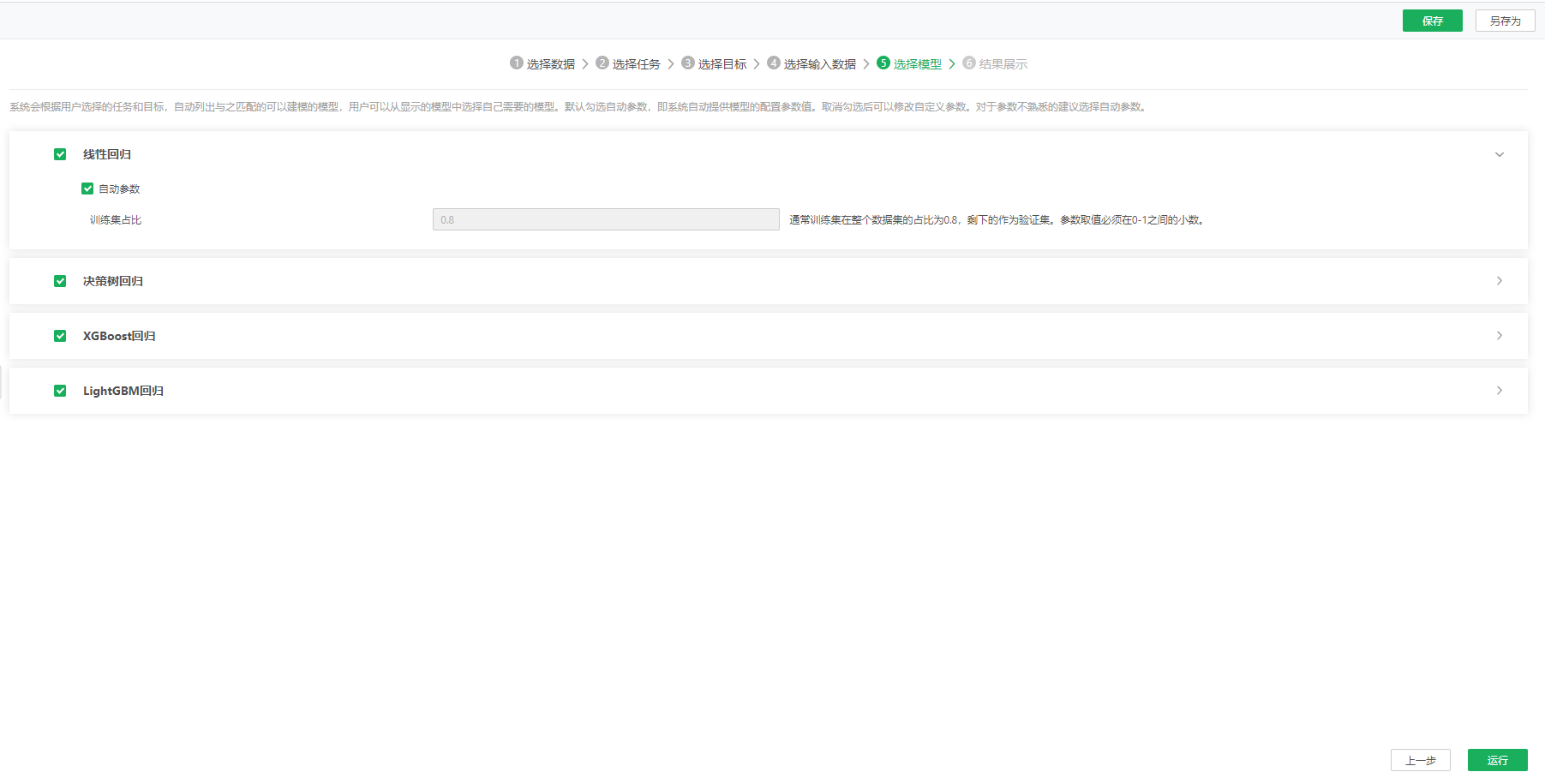
5)第五步,选择模型。
点击下一步,进入到选择模型页面,产品会根据用户的选择,列出与目标和任务匹配的模型。每个模型有两种设置参数的方法,一种是自动参数,即产品为模型自动匹配参数,另一种是自定义参数,用户根据需要设置模型的参数。对于参数不熟悉的建议选择自动参数。
➢注意:
选择模型较多时运行时间也会长。
6)第六步,结果展示。
点击运行,进入到结果展示页面,可以查看模型运行的结果并保存。默认显示比较页面,展示所有模型的对比数据,包括对比图和表格,表格包括运行时间、执行状态和指标对比,指标会根据模型的不同而变化。如果你不知道选择哪个模型,通过对比指标值,可以帮助你选择一个最优的模型,这也是自动建模的优势之一。选择右上角的保存,可以将整个Auto Model创建流程保存到实验列表。
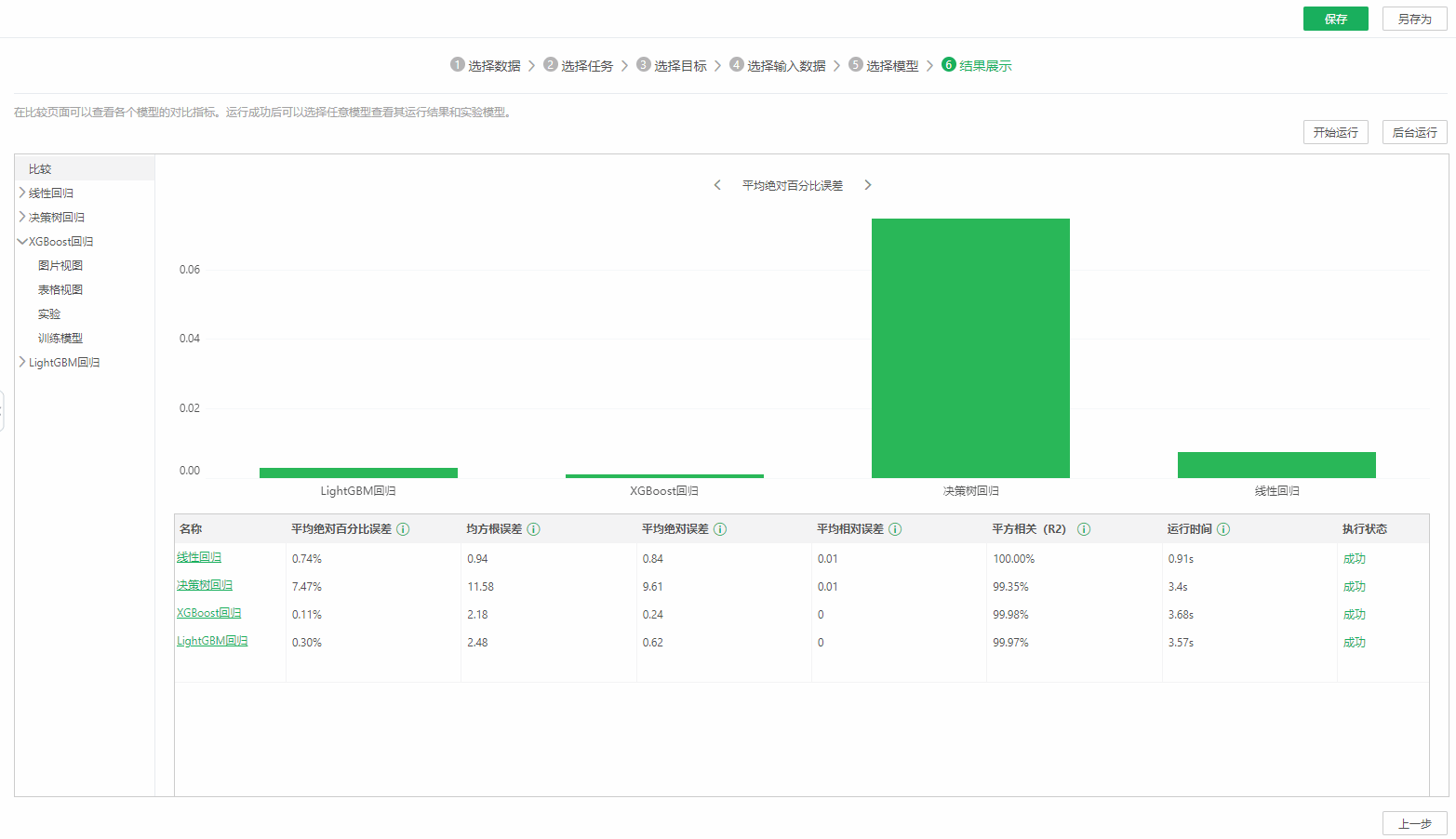
选择任一模型,还可以查看此模型的实验结果,包括表格视图、图片视图、文本视图、数据集视图、实验和训练模型,视图会根据实验不同显示不同。选择实验,产品自动构建了实验模型,点击保存实验,可以将当前模型单独保存到实验列表中,之后在实验列表中直接打开查看并使用。
➢注意:
每一步操作页面都可以返回上一步重新设置,不过当运行实验后再返回上一步,实验需要重新运行。