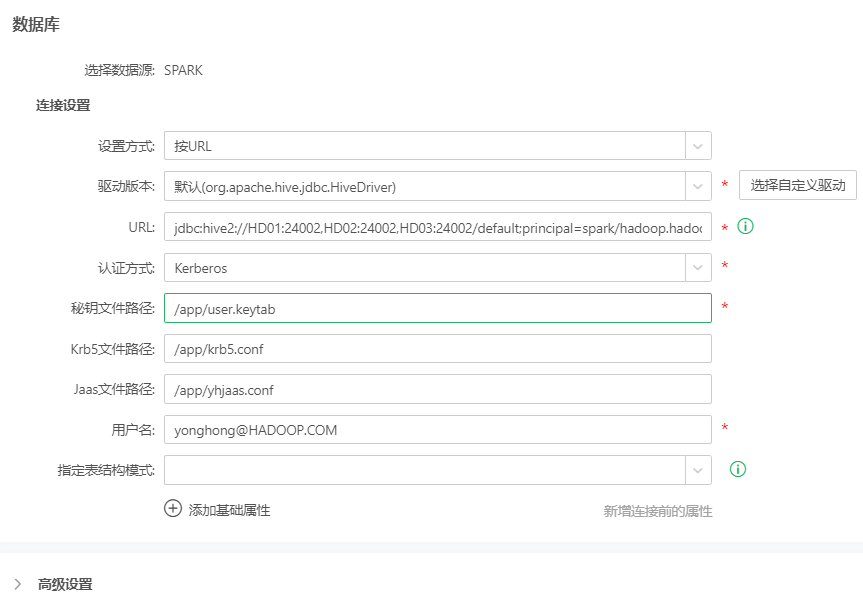
1.驱动
org.apache.hive.jdbc.HiveDriver,受驱动版本限制可能有所不同。驱动来源参考支持的数据源范围。
2.数据库连接URL
加粗字体的信息需要根据客户环境自行配置,各项配置以 ; 隔开
•连接zookeeper:
spark:jdbc:hive2://HD01:24002,HD02:24002,HD03:24002/default;principal=spark/hadoop.hadoop.com@HADOOP.COM;saslQop=auth-conf;serviceDiscoveryMode=zooKeeper;auth=KERBEROS;zooKeeperNamespace=sparkthriftserver
•spark2x:
jdbc:hive2://HD01:24002,HD02:24002,HD03:24002/default;principal=spark2x/hadoop.hadoop.com@HADOOP.COM;saslQop=auth-conf;serviceDiscoveryMode=zooKeeper;auth=KERBEROS;zooKeeperNamespace=sparkthriftserver2x
3.URL各项说明(以Spark为例)
•HD01:24002,HD02:24002,HD03:24002
连接zookeeper
集群各节点的域名或IP,注意是 ip:port,ip:port,ip:port,与spark-defaults.conf中spark.deploy.zookeeper.url 保持一致。
•default 默认数据库。
•principal= spark/hadoop.hadoop.com@HADOOP.COM 连接hive数据库的Kerberos principal,与spark-defaults.conf中spark.beeline.principal的值保持一致。
•saslQop=auth-conf 永洪BI和Spark通信时的加密信息,与hive-site.xml中hive.server2.thrift.sasl.qop的值保持一致。
•serviceDiscoveryMode=zooKeeper 固定项,代表连接是zookeep。
•auth=KERBEROS 固定项,代表使用Kerberos进行用户认证。
•zooKeeperNamespace=sparkthriftserver 与 spark-defaults.conf中spark.thriftserver.zookeeper.namespace的值保持一致。
4.注意事项
•同hive的saslQop
•连接zookeeper时,数据源“Jaas文件路径”项为必填项。
•注意在永洪BI服务器主机的/etc/hosts文件中配置需要的host与ip的信息,可以从数据库集群所在任一主机的/etc/hosts文件中复制。
➢下图为Spark数据库连接示例: