node嵌套子标签结构如下所示:
<node>
<description>插件简介信息,帮助用户快速了解插件的使用</description>
<label>节点名</label>
<path>填写你的插件节点放置路径</path>
<type></type>
<hyperparameters>……</hyperparameters>
<used-columns>……</used-columns>
<outputs>……</outputs>
<automl>……</automl>
</node>
子标签与产品页面中信息的对应关系如下图所示。
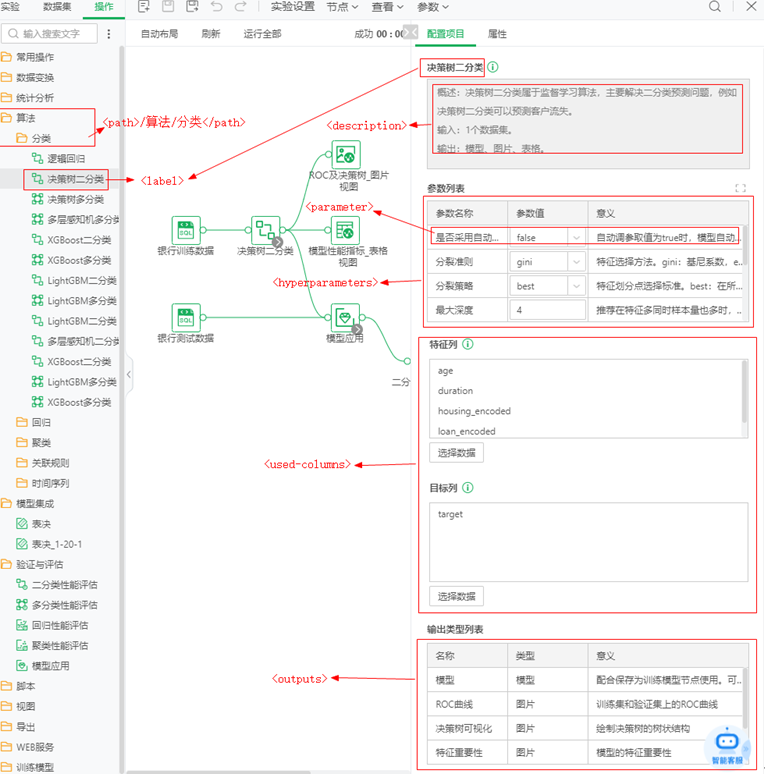
1)<description>
必填项,用于向用户介绍插件,建议包含要素:概述、输入、输出、注意事项
2)<label>
节点名称,只可以是字母、数字、汉字、下划线的组合
3)<path>
节点存放目录,相对路径(相对于产品侧边栏树状结构目录的根目录),可选的目录为在中文环境下有:/数据变换、/统计分析、/算法、/模型集成、/验证与评估,在英文环境下有:/Transform、/StatisticalAnalysis、/Algorithm、/ModelIntegration、/Validate_Score,不允许缺省
4)<type>
最常用的节点type类型如下表第一列所示,开发者在一定要根据自己插件的输出输出需求进行选用,否则在产品中将无法按预期使用,因为这些type值决定了您开发的插件与产品中其他算子节点及插件节点的连线规则。判断一个插件与其他节点能否连线并传输数据的依据是看该插件或者内置节点输入、输出的数据类型是否一致。比如一个节点的输出有数据集,则其能连接的后置节点只能是输入也为数据集的节点。
type备选值 |
用途 |
输入 |
输出 |
source |
用于创建自定义数据集或数据源节点,从外部系统拉取数据。 |
无 |
一个数据集 |
transformer |
用于处理从前一个节点输入的数据集情形,比如缺失值处理、统计词频等等 |
一个数据集 |
一个数据集 |
transformer-with-model |
用于对数据进行规范化处理情形,比如机器学习中的标准化、值映射、编码等 |
一个数据集 |
一个数据集, 一个训练模型 |
bi-classifier |
用于开发机器学习中的二分类算法 |
一个训练用数据集 |
一个训练模型 |
multi-classifier |
用于开发机器学习中的多分类算法 |
一个训练用数据集 |
一个训练模型 |
regression |
用于开发机器学习中的回归算法 |
一个训练用数据集 |
一个训练模型 |
cluster |
用于开发机器学习中的聚类算法 |
一个训练用数据集 |
一个训练模型 |
association |
用于开发机器学习中的关系挖掘算法,比如关联规则 |
一个数据集 |
一个数据集 |
time-series |
用于开发时间序列预测算法 |
一个带有时间列的数据集 |
一个数据集 |
除了上表列出的节点类型值之外,还有一些是用户不常用而主要供永洪自用的type值如数据变换(integration)、模型集成(vote)等。这里不作详细介绍,如果确实有特殊需求,请到永洪官网论坛的互助问答留言咨询,将有人为你解答。
5)<hyperparameters>
必填项,定义插件的参数列表。该标签含有嵌套子标签,详细介绍参考<hyperparameters>及其子标签。
<used-columns>
必填项,定义插件需要使用的字段数据,通常用于定义字段的角色,比如用作模型特征列(自变量)、标签列(因变量)。该标签含有嵌套子标签,详细介绍参考<used-columns>及其子标签。
6)<outputs>
必填项,定义插件能够输出哪些类型的数据,比如图片、表格、数据集等类型的数据。该标签含有嵌套子标签,详细介绍参考<outputs>及其子标签。
7)<automl>
非必填项,当插件是分类、回归、聚类三种类型的并且想让插件支持创建Auto Model实验时,该标签是可用的。该标签含有嵌套子标签,详细介绍参考<automl>及其子标签。