1.概述
自循环列就是根据设置自动分出层级关系的列,每个数据集只能创建一个自循环列。一般来说拥有层级关系的 ID 有两种存储方式:ID 长度不一致,ID 长度一致。在本产品中规定,如果想保持 ID 长度一致就必须用 0 补位。
2.应用场景
一个公司部门之间都存在层级关系,每个部门都会有唯一的部门 ID 对应,比如说总公司(ID 为 1),技术部(ID 为 11,该层级的第一位为第一层的 ID 值),技术工程师(ID 为 111,该层级的第一位为第一层级的值,第二位为第二层级的值),技术部是总公司下面的分属部门,技术工程师是技术部的下属部门,具体到岗位的ID存储为数据集如图:
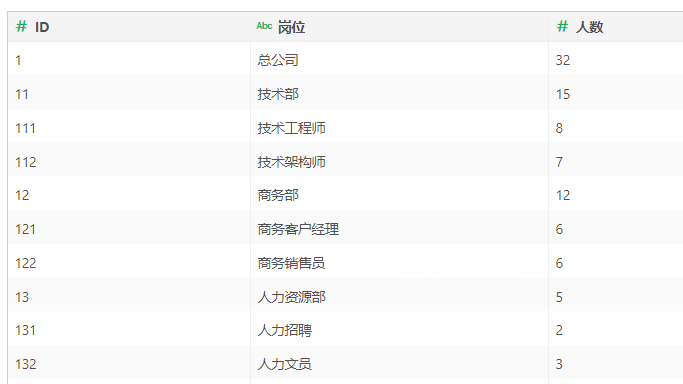
数据库存储部门信息的时候,都是将所有部门 ID 放在一个数据列中,并没有将总部作为一个数据列,技术部作为一个数据列,那么在进行数据分析的时候,如果要显示各个部门的层级关系,并按照层级关系分组显示数据,就没法直接添加维度来实现分组效果。这时候可以采用“自循环列”节点将图示数据集分组以展示层级关系:
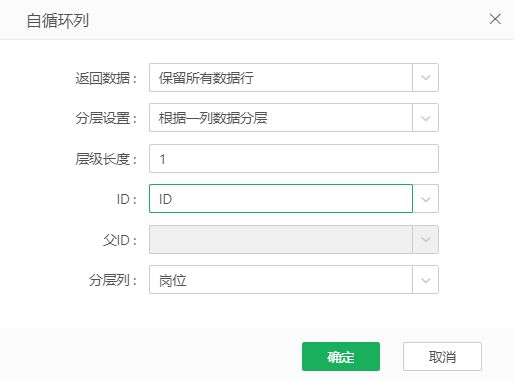
1) 将上述数据集拖入自服务画布作为输入节点,在输入节点后面连接一个自循环列节点,在自循环列编辑菜单中,根据一列数据分层,层级长度为1,设置如下图:
功能说明如下:
功能 |
说明 |
|---|---|
返回数据 |
选择返回数据是: •仅保留最内层数据行 •保留所有数据行 |
分层设置 |
选择分层列数:根据一列数据分层或者根据两列数据分层。根据两列数据分层时,通过给出每个行对应的ID的父节点ID来实现对层级的划分。 |
层级长度 |
ID中多少位代表一个层级。 |
ID/父ID |
父 ID 是 ID 的上一级 ID ;这里只显示度量列。当选择根据一列分层时,就根据层级长度和 ID 对应的列分层;当选择根据两列分层时,就根据 ID 和父 ID 分层。 |
分层列 |
被分层的列 |
2)采用根据一列数据分层时:
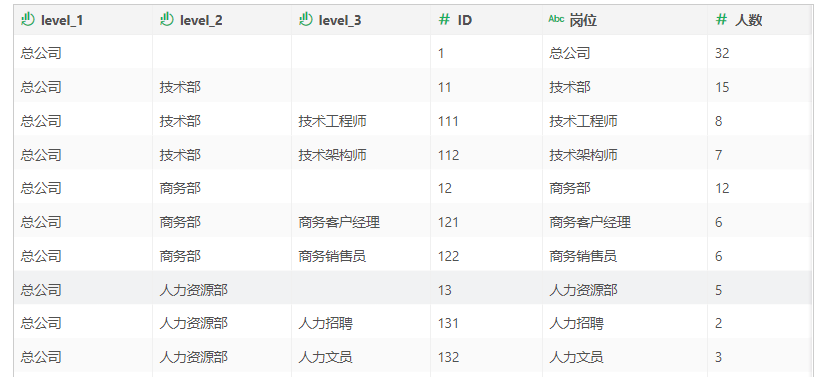
•当保留所有数据行时,输出的数据集扔包括部门中的父节点行,当需要同时展示各部门汇总数据时可以选择这种返回方式:
•当仅保留最内层数据行时,仅展示具体岗位的各部门层级结构,而父节点的部门不再单独展示一行,当只关注各岗位的分组和数据时可以选择这种返回方式:
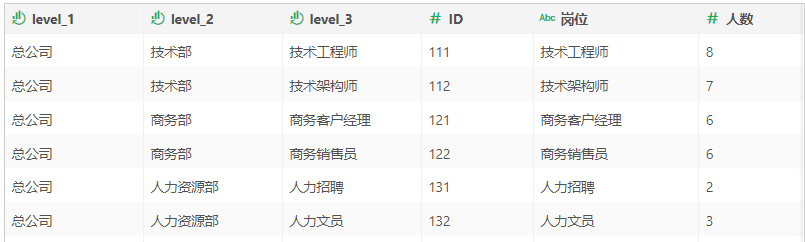
3)当原本数据如下图,已经通过父指标编码列标识出来了每个单项的父项编码时,可以采用两列数据分层。
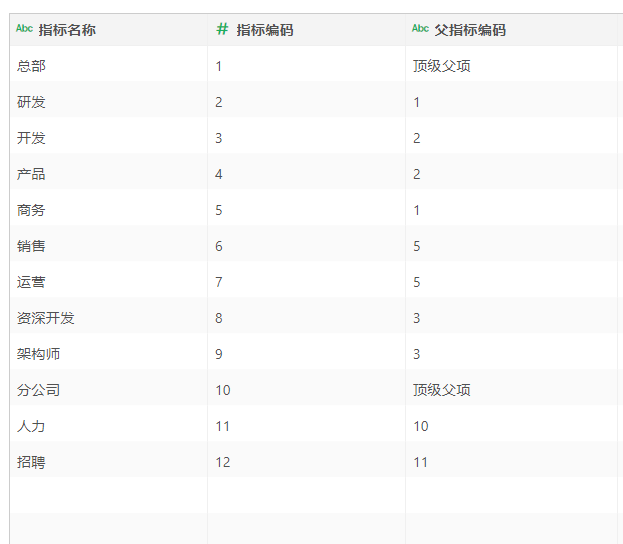
分层结果如图。