1.概述
1.1 应用场景
K-Means聚类主要解决聚类预测问题,适用于数据科学和机器学习领域,例如客户分类:根据客户的消费行为对客户进行聚类,以便更好地了解不同类型的客户需求。市场细分:根据客户的购买行为对市场进行聚类,以便更有效地进行营销活动。案例可以参考员工离职分析。
1.2 功能介绍
K-Means聚类属于无监督学习,支持两种初始化方法,包括k-means++和random。
输入:1个数据集,量纲不一致情况下,输入数据需要标准化处理。
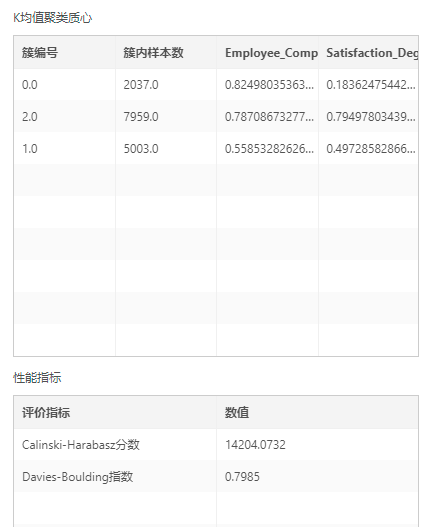
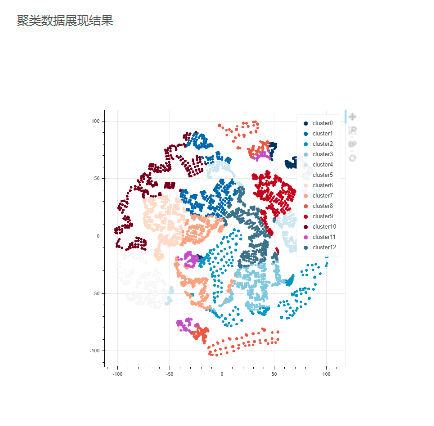
输出:K-Means模型,聚类中心、模型聚类结果评价指标(Calinski-Harabasz分数、Davies-Boulding指数),聚类数据展现结果散点图。
➢注意:
聚类模型输入数据需要筛选变量的共线性问题,可以使用统计分析中的相关性分析节点处理。
2.配置方法
2.1拖入节点
将K-Means聚类节点添加到实验后,可通过右侧的“配置项目”页面,对K-Means聚类节点进行设置。
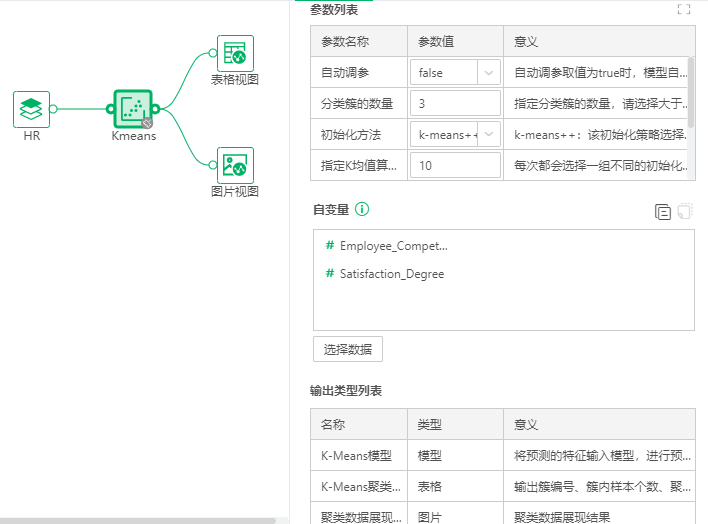
2.2参数列表
【使用集群】选择true时,算子使用分布式集群运行,选择false时单机运行,默认为false。集群运行需要在集群环境下才能生效。
【自动调参】自动调参取值为true时,模型自动进行超参数优化,取值为false时,需要手动调参。
【分类簇的数量】指定分类簇的数量,请选择大于1的整数。
【初始化方法】初始化聚类中心的方法。
•k-means++:该初始化策略选择的初始均值向量相互之间都距离较远,它的效果较好。
•random:从数据集中随机选择n个样本作为初始均值向量或者提供一个数组,数组的形状为(n_clusters,n_features),该数组作为初始均值向量。
【指定K均值算法运行次数】每次都会选择一组不同的初始化均值向量,最终算法会选择最佳的分类簇来作为最终的结果。请选择大于1的整数。
【迭代次数】指定了单轮kmeans算法的迭代次数。请选择大于1的整数。
【随机种子】固定随机种子用于保证模型训练的结果可复现。请选择大于1的整数。
【预先计算距离】该参数指定是否提前计算好样本之间的距离。true :提前计算。false:不提前计算。
【算法】指定采用的算法。auto:自动选择算法。full:使用经典的EM风格的算法,用于稀疏数据。elkan:用于密集数据,不支持稀疏数据。
2.3选择变量
自变量:选择需要计算的特征字段。至少选择一个字段。
➢说明:不支持文本类型。
选择数据页面操作见节点 >选择数据。
3.查看结果
可通过连接多视图节点查看结果或连接表格视图来查看输出聚类类别、聚类类别个数、聚类中心和模型聚类结果评价指标(Calinski-Harabasz分数、Davies-Boulding指数),连接图片视图来查看聚类数据展现结果。也可连接保存为训练模型节点,将模型保存为操作节点后再次使用。