在很多业务场景中,用户需要查看业务指标的实时数据大小,这就对数据展示的时效性提出了更高的要求。vividime Z-Suite支持通过配置特定的推送URL,作为实时获取用户推送的流式数据信息的入口,实现高时效性的数据可视化。
➢说明:
流式数据集为产品高级数据集,需单独购买Y+Vivid Show许可许可。
1.创建流式数据集
点击数据集页面左侧顶部的![]() 图标,进入新建数据集页面。点击流式数据集进入创建页面。
图标,进入新建数据集页面。点击流式数据集进入创建页面。

2.编辑流式数据集
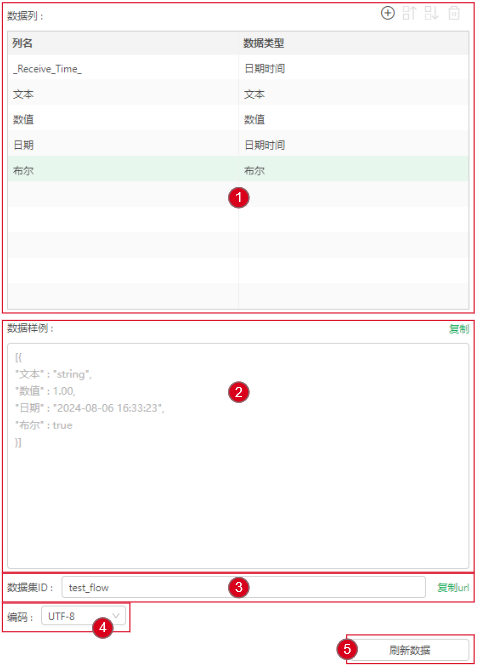
功能说明如下:
功能 |
说明 |
|---|---|
数据列 |
用户需要添加数据列和数据类型,保证列和数据类型和用户推送的数据列相匹配,支持添加/删除/上移/下移,点击列名和数据类型的位置以输入列名和下拉选择数据类型。 默认存在一列时间类型的_Receive_Time_列,不支持修改和删除。 |
数据样例 |
显示每一个数据类型的样例值,以json的形式显示,不包含默认的_Receive_Time_列,不可编辑,支持复制。 |
推送URL |
创建推送的URL,不同结构的流式数据集不能使用同一个推送URL,如果出现冲突,保存时会失败并提示,推送URL支持复制。 |
编码 |
选择编码格式以适配不同推送端的编码,目前支持UTF-8和GBK。 |
刷新数据 |
编辑区做了改动可能导致获取到的数据发生改变时,点击刷新数据可以刷新数据区预览的数据和元数据。 |
➢示例:
通过请求推送数据示例。请求地址为推送URL,请求体中以{"data":[数据样例]}的格式将多行数据进行推送。


流式数据集可以通过过滤筛选出最后X秒的数据。
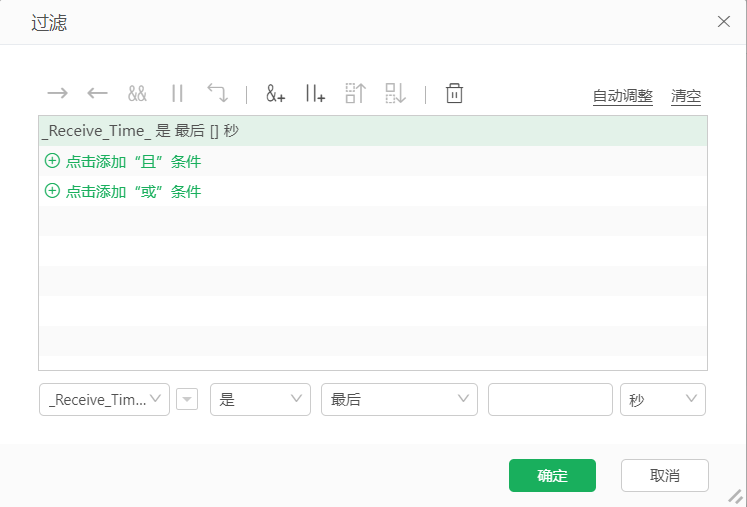
当进行了这个过滤后,在制作报告时勾选【数据推送】功能就可以实时查看所设置的最后X秒的数据。

实现效果参考下图。

➢注意:
•报告最多只能绑定10个不同的流式数据集进行实时数据推送。
•流式数据集最多存储接收时间 60 分钟以内的数据,超过接受时间的自动进行清理。
•单C时,可以直接使用流式数据集;多C时,需要配置 Redis 才可以使用。
•不支持抽取到数据集市与导出到数据库。
•单个数据集支持的最大列数为50列,最大行数为200000行。
支持的版本:11.0.1及以后
在流式数据集中创建好数据结构后,点击数据集中的设置出现弹窗,可以设置从kafka拉取数据。
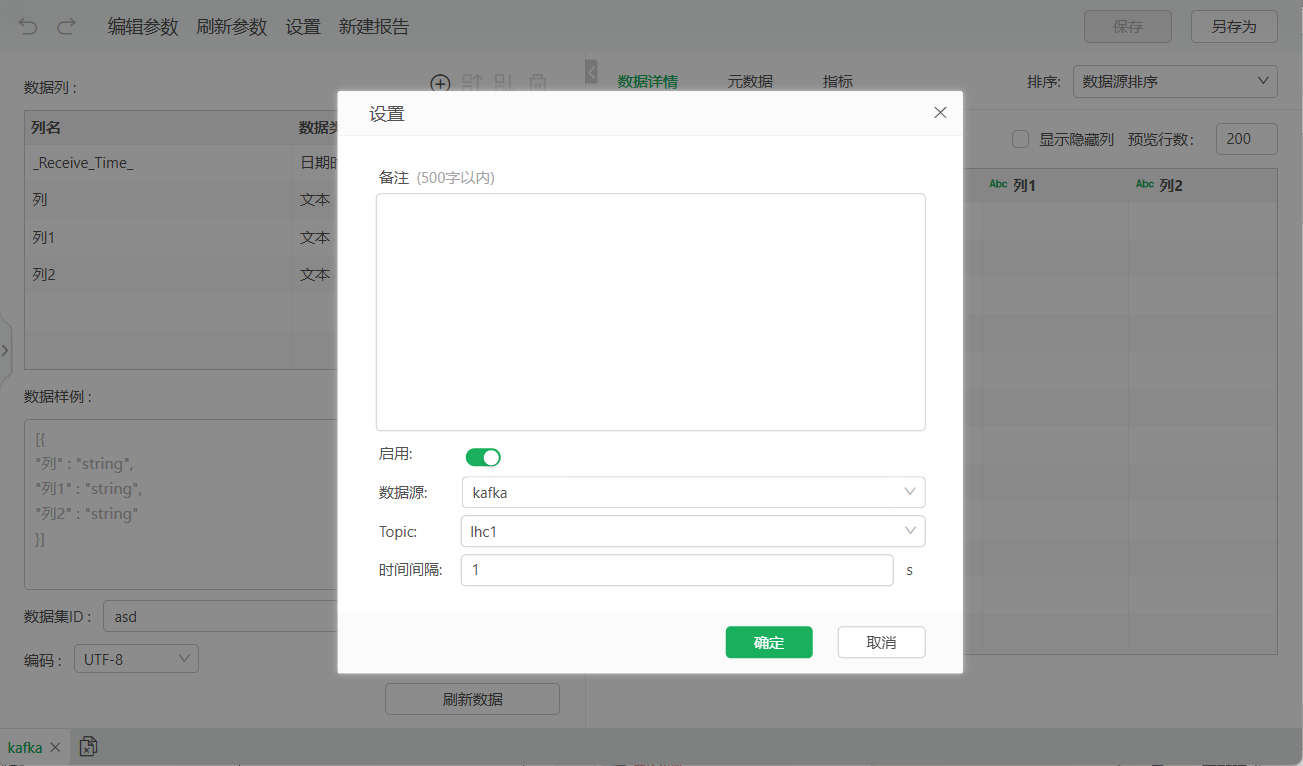
功能说明如下:
功能 |
说明 |
|---|---|
启用 |
启用从kafka拉取数据的任务 |
数据源 |
选择拉取数据的kafka来源。 |
Topic |
选择拉取数据的kafka主题。 |
时间间隔 |
设置kafka拉取数据的任务的时间间隔,允许填写小于60的正整数。 |
设置好后将自动通过间隔时间执行调度任务,拉取对应kafka数据源主题中的数据,要求kafka中的数据格式符合{"data":[数据样例]}的情况下才能够将数据读取到流式数据集中。