|
<< Click to Display Table of Contents >> Map Side Join |
|
|
<< Click to Display Table of Contents >> Map Side Join |
|
在分布式系统中,当有星形数据(一个大表,若干个小表)需要 join 的时候,可以将小表的数据复制到每个 Map 节点,执行 Map Side Join, 而无须到 Reduce 节点进行连接操作,从而提升表连接的效率。
Hadoop 中使用 DistributedCache 来实现 Map side join。它可以将小文件分发到各个节点上,在连接的时候将小文件导入到内存中使用。Spark 在 Hadoop 的基础上,使用 Broadcast 来实现 Map side join。Broadcast 文件分发的效率要明显好于 DistributedCache,因为它采用更优化的文件广播算法,包括 P2P 算法等。
在 MPP 集市中,我们可以定义维度表,即 join 操作中的小表。在用户导入维度表的时候,将维度表分发到每个节点上,如下图所示:

当新加节点时,也需要将现有的维度表分发到该节点上。
当执行数据集市数据集时,可以进行 Map Side Join 的条件是:
(1)组合数据集,自服务数据集或者是 Yonghong 的 SQL 数据集。
(2)Join 操作中,必须符合星型数据,且小表是维度表(要求 Join 操作中,所有表中有且只有一个表是非维度表)
Naming 节点部署 Map Task 的时候,优先将任务分配给本地已有维度表的节点,并将需要的维度表信息发送到相应的 Map 节点。如果该 Map 节点没有对应的维度表信息,则请求 Naming 节点获取维度表,存在本地。
其中组合数据集和自服务数据集使用联接操作符(内部联接,左侧联接,右侧联接,外部联接)实现 Join, 组合数据集如下图所示 :
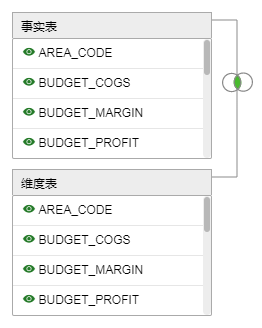
Yonghong 的 SQL 数据集实现 MapSideJoin 需要创建 Yonghong 的 SQL 数据集,在数据集中输入如下 SQL 语句可以实现事实表和维度表的 join,如下图所示: