|
<< Click to Display Table of Contents >> 关联规则 |
|
|
<< Click to Display Table of Contents >> 关联规则 |
|
关联规则(Association Rules)是无监督的机器学习方法,从数据背后发现事物之间可能存在的关联或者联系,用于知识发现,而非预测。这种事物之间的关联或者联系就叫规则。
拖拽一个数据集和一个关联规则节点到编辑区,连接数据集和关联规则节点。
关联规则包含两种算法:一种为分布式的FG-Growth,另一种为非分布式的Apriori。
•Apriori:
Apriori算法是一种最有影响的挖掘布尔关联规则频繁项集的算法,通过对数据的关联性进行了分析和挖掘,挖掘出的这些信息在决策制定过程中具有重要的参考价值。运用Apriori算法时,绑定的数据集不能是集市数据集。
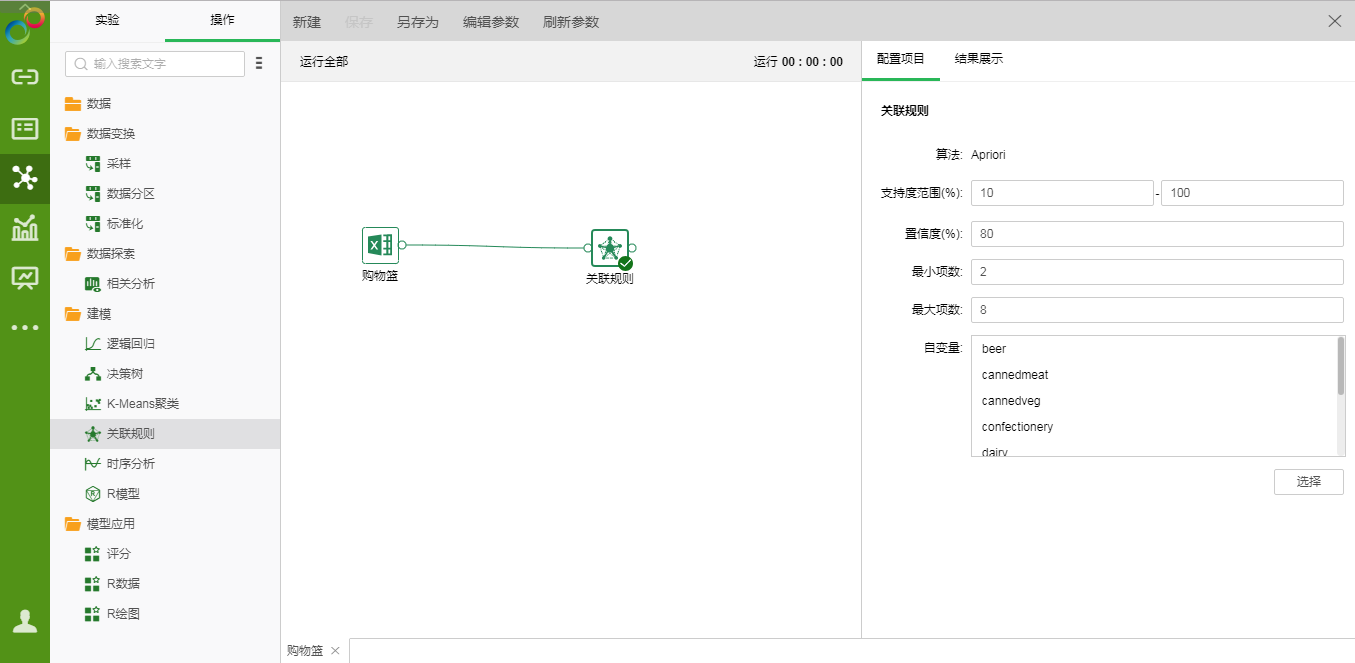
❖Apriori算法的配置
添加关联规则模型到实验后,可通过右侧的“配置项目”页面,对模型进行设置。
【支持度范围(%)】模型所生成的规则的支持度级别的百分比值范围。如果不在此范围内规则将被废弃。
【置信度(%)】模型所生成的规则的置信度级别的最小百分比值。如果模型所生成的规则的置信度级别小于此数量,那么该规则将被废弃。
【最小项数】模型所生成的规则的最小项数,小于此值将被废弃。
【最大项数】模型所生成的规则的最大项数,大于此值将被废弃。
【自变量】从选择列对话框中选出需要作为自变量的字段。
❖运行Apriori算法实验模型
当用户完成模型的配置后,点击关联规则节点,右键菜单中选择“运行”,即可运行该模型,开始运行后,编辑区右上方开始计算运行时间。你也可以直接点击编辑区上方的“运行全部”来运行你所设置的实验模型。
运行成功后,会弹框输出模型结果,点击收缩图标,查看节点状态,显示节点成功,如下图所示。

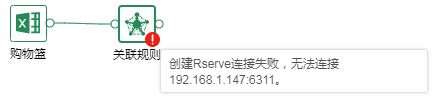
如果运行失败,节点会提示失败,鼠标悬浮在节点上可查看失败原因,如下图所示。
❖查看Apriori算法模型结果
关联规则模型运行成功后,会弹框输出模型结果,自动切换到“结果展示”页面,查看实验模型的结果,再次运行时则不会自动切换,可以手工切换至结果展示页面。
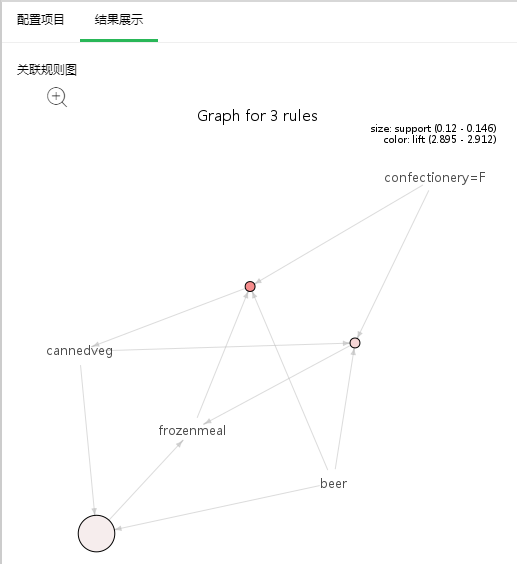
•关联规则图
各项的关联关系图,每个圆圈代表一条规则,指向圆圈的是左项,圆圈指向的是右项;圆圈大小代表支持度大小,圆圈越大支持度越大,圆圈颜色代表提升度,颜色越深提升度越大。
点击放大按钮,可放大图片以更清晰的查看图片。
•关联规则
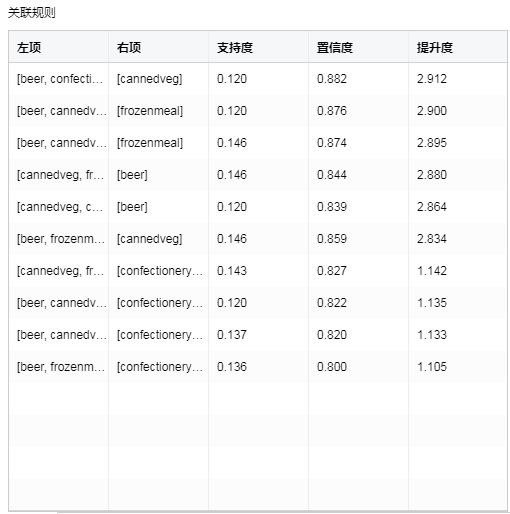
【左项】规则的先导项集。
【右项】规则的结论项集。
【支持度】项集出现的次数除以总的记录数。
【置信度】项集{X,Y}同时出现的次数占项集{X}出现次数的比例。
【提升度】度量项集{X}和项集{Y}的独立性。数值越大模型越好。
•FG-Growth:
•FP-Growth算法基于Apriori构建,但采用了高级的数据结构减少扫描次数,大大加快了算法速度。FP-Growth算法只需要对数据库进行两次扫描,而Apriori算法对于每个潜在的频繁项集都会扫描数据集判定给定模式是否频繁,因此FP-Growth算法的速度要比Apriori算法快。运用FG-Growth算法时,绑定的数据集需要是集市数据集,且绑定列的数据需由逗号进行分隔。
❖FG-Growth算法的配置
添加关联规则模型到实验后,可通过右侧的“配置项目”页面,对模型进行设置。
【最小支持度(%)】最小支持度用来度量一个集合在原始数据中出现的频率。如果不在此范围内规则将被废弃。
【K值】模型所生成的项目展示的行数。
【最小项数】控制频繁项集的最小长度,小于此值将被废弃。
【最大项数】控制频繁项集的的最大长度,大于此值将被废弃。
【自变量】从选择列对话框中选出需要作为自变量的字段。
❖运行FG-Growth算法的实验模型
当用户完成模型的配置后,点击关联规则节点,右键菜单中选择“运行”,即可运行该模型,开始运行后,编辑区右上方开始计算运行时间。你也可以直接点击编辑区上方的“运行全部”来运行你所设置的实验模型。
运行成功后,会弹框输出模型结果,点击收缩图标,查看节点状态,显示节点成功,如下图所示。

如果运行失败,节点会提示失败,鼠标悬浮在节点上可查看失败原因,如下图所示。

❖查看FG-Growth算法模型结果
关联规则模型运行成功后,可通过右侧的“结果展示”页面,查看实验模型的结果。
•关联规则
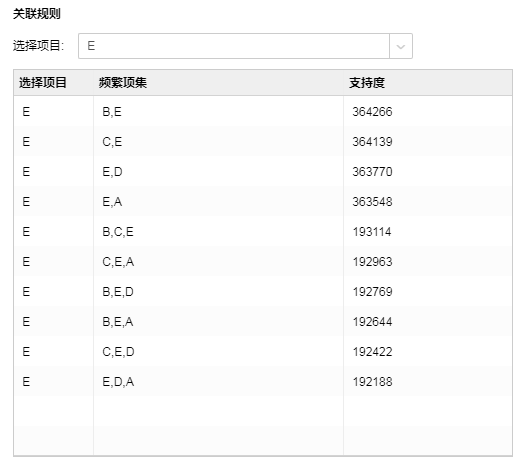
【选择项目】数据库中的字段所包含的其中一个产品名称。
【频繁项集】某个项集的支持度大于设定阈值,即称这个项集为频繁项集。
【支持度】项集在总项集中出现的次数。
❖关联规则节点重命名
在关联规则节点的右键菜单中,选择“重命名”,可以对节点进行重命名。
❖删除关联规则节点
在关联规则节点的右键菜单中,选择“删除”或者点击键盘 delete 键进行删除,能够删除节点以及节点的输入、输出连线。
❖刷新关联规则节点
在关联规则节点的右键菜单中,选择“刷新”,可以更新同步数据或者参数信息。