|
<< Click to Display Table of Contents >> 集市文件系统 |
|
|
<< Click to Display Table of Contents >> 集市文件系统 |
|
❖文件系统
关于 Folder:Folder 是一个文件集。只有 Naming Node 上才有 Folder。
关于 File:File 是某个文件集中的一个文件。 File 有三种形态:
1.Client Node 上的 File: 这时的 File 将被 Client Node 加入云系统中。
2.Naming Node 上的 File: 这时的 File 是元数据。这个元数据也在内存中保存了哪些 Map/Reduce Node 上存储有该 File 的信息。
3.Map/Reduce Node 上的 File: 这时的 File 是元数据,但也保存着指向物理文件的指针。
•文件集
只有 Naming Node 上才存储有 Folder, Folder 完全是元数据,由一个或者多个 File 组成。
•Folder 的名称可以包含 '/'
为什么要这样呢?这是因为 Folder 的每一个 File 的全名就是 Folder_Name/File_Name,在存储物理文件的时候,如果 Folder_Name 可以包含 '/',那么可以形成下例所示的全名:sales/product/file_1,其中 sales/product 是 Folder_Name。这样一来,存储物理文件就不限于两级目录而可以是多级目录。在操作系统中,如果同一目录下的文件太多,访问效率将大大降低。我们的文件系统支持多级目录机制,主要就是想避免这一问题。
➢例如
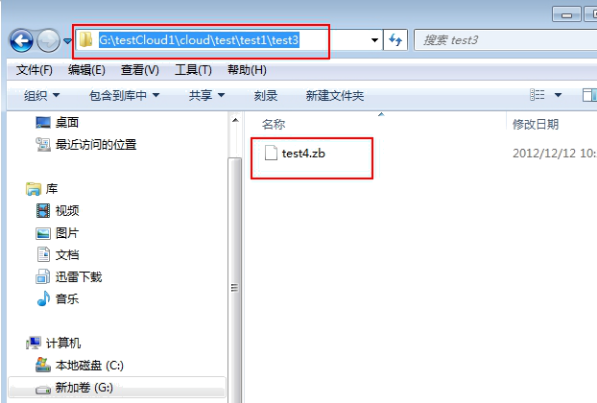
在任务计划中执行云任务时设定云文件夹的名称为 test/test1/test3,云文件的名称为 test4,如下图所示。

此任务执行完后,将在指定的路径中 ( 在 root/abc@123 中指定的 dc.fs.physical.path=G\:/bihome/ cloud,详细介绍如何搭建本地数据集市系统 ) 生成云文件夹以及云文件。
•文件
Naming Node 上的 File。作为元数据, Naming Node 上的 File 存储在 Folder 中,由于 Map/Reduce Node 不断发送心跳报告, Naming Node 将能接收到某个 File 的物理文件在哪些 Map/Reduce Node 上存储。
Map/Reduce Node 上的 File。 Map/Reduce Node 上的 File,是一个元数据文件,并保存着指向本机上的物理文件的指针。 Map/Reduce Node 定期地向 Naming Node 发送心跳报告,以告诉 Naming Node该 Node 可用,并给出存储于本 Node 上的 File 信息。
•GMeta 介绍
Naming Node 上的 File 有一个 GMeta,记载本文件的一些摘要信息。
1.File 上的 GMeta 存储的摘要信息可以由用户自定义。例如,用户可以定义这个文件存储数据的日期2012-6-30。另外,系统会自动加上文件名作为其中的一项摘要信息:_FILE_NAME_。
2. Folder 存储于 Naming Node 上,也有一个 GMeta 记载文件夹的一些摘要信息。
同理, Folder 上的 GMeta 存储的摘要信息也可以由用户自定义。系统自动会加上两个方面的内容:
Folder 所对应的 Data Grid 的 Columns ;以及任意子 File 上的 GMeta 上存储了哪些可用的摘要信息,同样以 Columns 的形式保存。
•GMeta 的功用
GMeta 上存储的摘要信息,在数据集市系统中发挥着重要的作用。
➢例如:
当用户创建一个数据集市数据集的时候,需要知道有哪些 Columns 可以使用。这个信息可以从 Folder 的 GMeta 中得到,因为 Folder 的 GMeta 存储着这些信息。
当用户创建一个数据集市数据集时,他 / 她可能不想基于 Folder 下面所有的 File 来运行查询。因为很多时候这样去运行数据集没有必要,却非常消耗资源。这时,数据集市数据集可以定义 File Filter 来限制需要访问的 File。这个 File Filter 将基于 Naming Node 的 File 上的 GMeta 来运行,直接找出 Query 需要访问的那些 Files,这样能很大地提升数据集的运行性能,并减少资源消耗。
由于 Folder 上以 Columns 的形式保存了子 File 上的 GMeta 上存储了哪些可用的摘要信息,在定义 File Filter 的 GUI 上,数据集市系统返回这些可用的 Columns 给用户来定义 File Filter。
•集市数据迁移
为了方便集市数据的备份和迁移,减少meta文件和物理文件不一致的情况,从7.5版本开始Naming Node以及Map Node上的meta存储方式发生了变化。原先所有集市文件夹的meta信息都会存储在qry_naming.m文件里,现在拆分存储,系统会为每个GSFolder创建一个同名文件夹来记录该GSFolder的meta信息,该同名文件夹和qry_naming.m文件处于同级目录。对于集市文件的meta信息,原先是单个Map Node上的所有meta信息都存储在qry_sub.m文件里,现在是直接将meta信息存储在集市文件本身。进行数据迁移或备份时,只需要迁移数据本身与该GSFolder对应的单个meta文件即可。
➢说明:对应的meta信息在分散存储的同时,仍然会存入qry_naming.m、qry_sub.m中。
➢注意:迁移集市数据到新的环境后,数据本身、单个meta文件所处的相对路径应该和迁移前保持一致。比如:迁移前meta文件所处的相对路径为bihome/cloud/咖啡销售统计/东部市场,迁移后所处的相对路径应该还是bihome/cloud/咖啡销售统计/东部市场。
•状态
不管是 Folder, Naming Node 上的 File,还是 Map/Reduce Node 上的 File,都有一个状态标注其可用还是不可用。
Folder 的 Active: 如果 Folder 不是 Active 的,那么基于这个 Folder 的 Query 将无法运行,也不会检查这个 Folder 是否需要自动修正,或者进行自动修正。
Naming Node 上 File 的 Active: 如果 File 不是 Active 的,那么基于其 Folder 的 Query 运行时将看不见这个 File,系统也不会检查这个 File 是否需要自动修正,或者进行自动修正。
Map/Reduce Node 上 File 的 Active: 如果 File 不是 Active 的,那么心跳时这个 File 将不可见。
❖自动管理
在 Naming Node 上,有一个专职医生 Doctor 对整个云系统进行自动管理。
有这样一些错误将进行纠正:
不匹配的 File。例如,某个 Map Node 心跳报告中包含一个 File,这个 File 的版本号已经过期,那么 Doctor 将让这个 Map Node 删除掉这个不匹配的文件。或者这个 Map Node 所对应的 Folder 已经不复存在,那么 Doctor 也会让这个 Map Node 删除掉这个没有作用的文件。备份过量的 File。例如, Naming Node 上的某个 File 备份数为 3,但系统定义的合理备份数为 2,那么 Doctor 将选择多于的备份删除。其删除算法将首先选择那些负担比较重的 Map/Reduce Node。
备份不足的 File。例如, Naming Node 上的某个 File 备份数为 2,但系统定义的合理备份数为 3,那么Doctor 将选择一个负担较轻的 Map/Reduce Node 来备份该 File。
❖手工管理
数据集市系统提供了一些 API 管理命令。
AddFolderTask:这个 Task 将新加入一个 Folder,或者追加新 File 到已经存在的 Folder 中。
RemoveFolderTask:这个 Task 能删除某个 Folder。
RemoveGSFileTask:这个 Task 能删除某个 File。
QueryTask:这个 Task 能 Query< 读写 > 某个 Host 上的某个 Node 一些信息。目前支持以下子功能:
Naming Node: active,查询数据集市系统是否可用。
Naming Node: activateFolder <folder>,让某个 Folder 可用。
Naming Node: deactivateFolder <folder>,让某个 Folder 不可用。
Naming Node: activateFile <file>,让某个 File 可用。
Naming Node: deactivateFile <file>,让某个 File 不可用。
Naming Node:existsFolder <folder>,查询某个 Folder 是否存在。
Naming Node:folders,查询存在的 Folders, Folder 之间用符号 "_sep_" 隔离。