|
<< Click to Display Table of Contents >> 数据变换 |
|
|
<< Click to Display Table of Contents >> 数据变换 |
|
❖数据变换
数据变换包含采样、数据分区、标准化。
•采样
采样是一种选择数据对象子集进行分析的常用方法。在统计学中,采样长期用于数据的实现调查和最终的数据分析。在数据挖掘中,采样也非常有用。然而,在统计学和数据挖掘中,采样的动机并不相同。统计学使用采样是因为得到感兴趣的整个数据集的费用太高、太费时间,而数据挖掘使用采样是因为处理所有的数据的费用太高,太费时间。在某些情况 下,使用采样的算法可以压缩数据量,以便可以使用更好但开销较大的数据挖掘算法。
拖拽一个数据集和一个采样节点到编辑区,连接数据集和采样节点。选中采样节点设置及展示区包含四个页面:配置项目、元数据、过滤数据、探索数据。
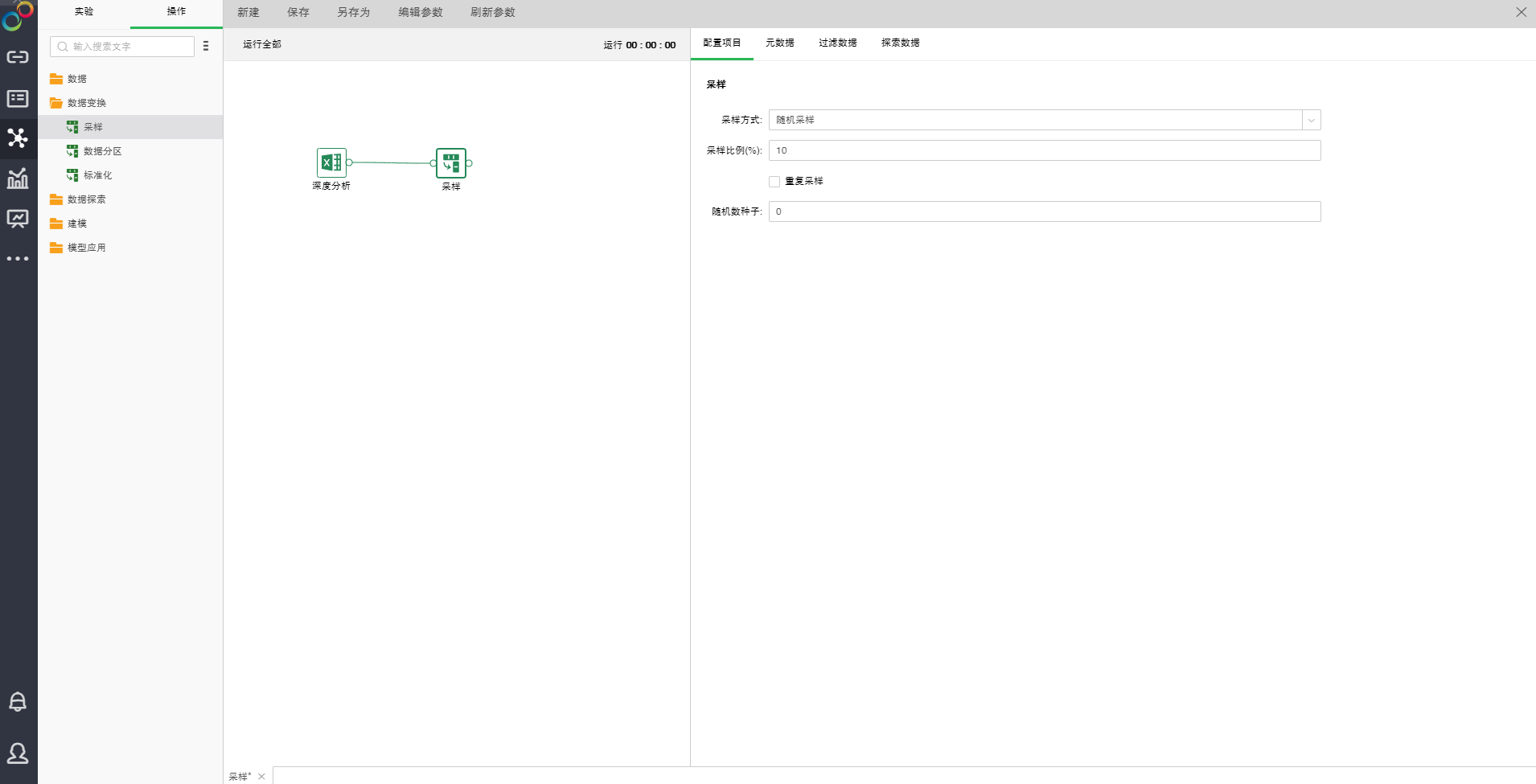
o配置项目
采样方式有三种:随机采样、按序采样、分层采样。
随机采样:
随机采样是按照随机的原则,即保证总体中每一个对象都有已知的、非零的概率被选入作为研究的对象,从数据集节点里抽取采样比例的样本行数,保证样本的代表性。

【采样比例】抽取样本的比例。
【重复采样】当不选中时,每个选中项立即从构成总体的所有对象集中删除。当选中时,对象被选中时不从总体中删除。当重复采样时,相同的对象可能被多次抽出。默认未选中。
【随机数种子】生成随机数的种子。默认值是0。
按序采样:
按序采样是取数据集的前N行作为结果集。
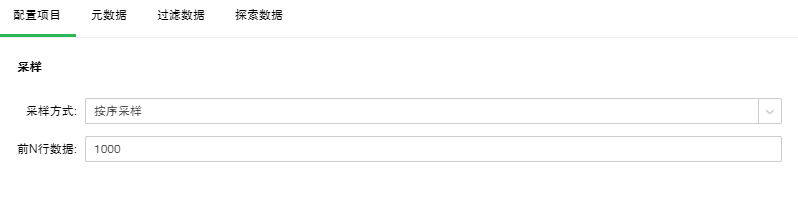
【前N行数据】按序采样抽取样本的前多少行。默认值是1000。
分层采样:
分层采样是从预先指定的组(即选择的列的不同值)开始抽样。每组按采样比例抽取。

【选择列】分层列,以它的不同值作为组按采样比例抽取样本行数。
其它参数请参看随机采样。
o元数据
请参考数据节点里的介绍。
o过滤数据
请参考数据节点里的介绍。
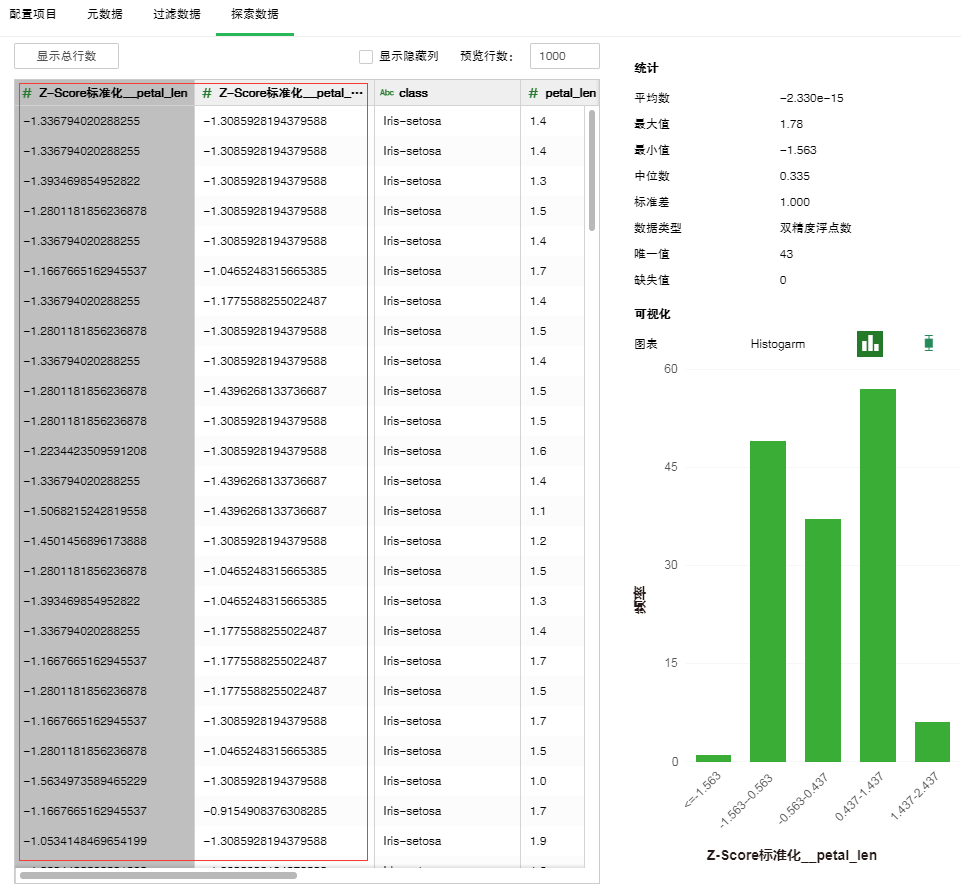
o探索数据
采样节点的全部数据是抽取的样本个数,其它详细信息请参考数据节点里的介绍。
•数据分区
一般做预测分析时,会将数据分为两大部分。一部分是训练数据,用于构建模型,一部分是测试数据,用于检验模型。数据分区就是把数据集节点的数据分为验证集和训练集。
拖拽一个数据集和一个数据分区节点到编辑区,连接数据集和数据分区节点。选中数据分区节点设置及展示区包含四个页面:配置项目、元数据、过滤数据、探索数据。
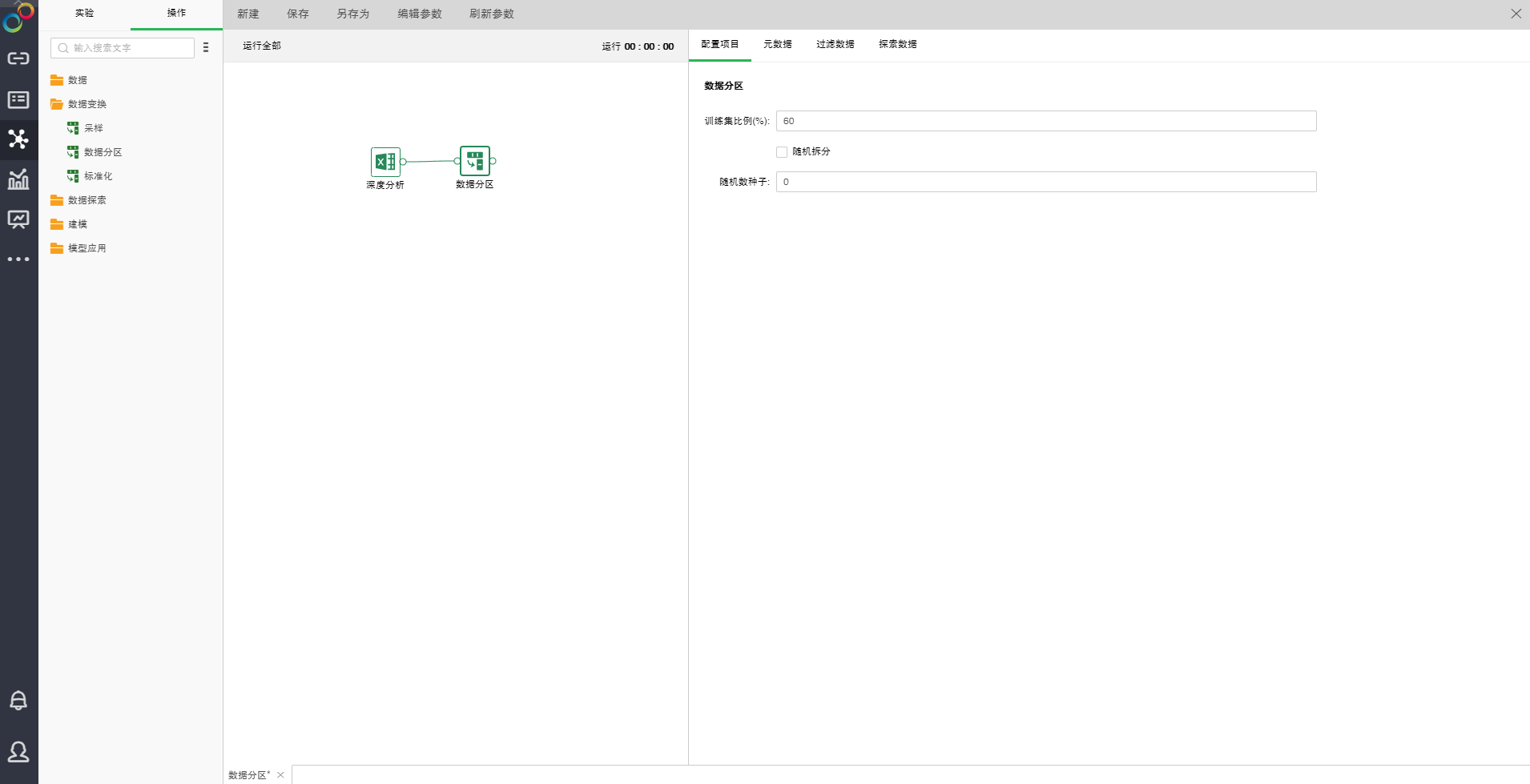
o配置项目
【训练集比例(%)】训练集占总样本数的比例,默认值是60。
【随机拆分】当不选中时按顺序抽取训练集。当选中时随机抽取训练集。默认未选中。
【随机数种子】生成随机数的种子。默认值是0。
o元数据
请参考数据节点里的介绍。
o过滤数据
请参考数据节点里的介绍。
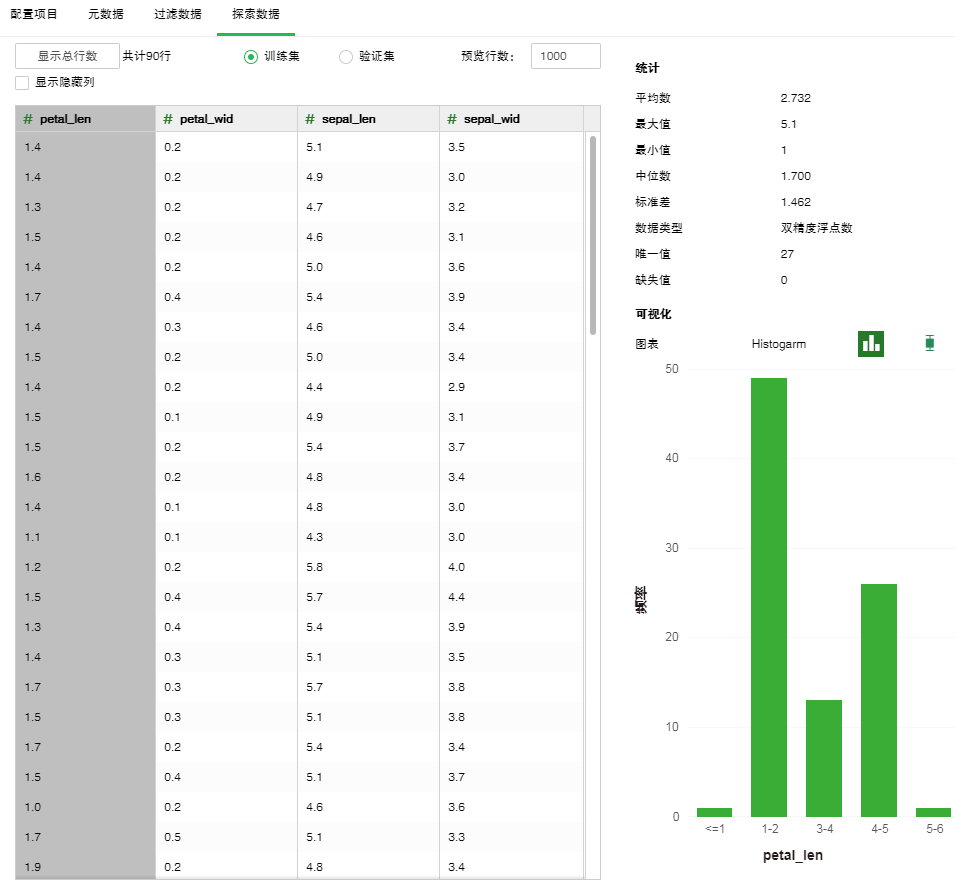
o探索数据
数据分区的探索数据中,可查看训练集和验证集的数据特征。其它详细信息请参考数据节点里的介绍。
•标准化
数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间。在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。
拖拽一个数据集和一个标准化节点到编辑区,连接数据集和标准化节点。选中标准化节点设置及展示区包含四个页面:配置项目、元数据、过滤数据、探索数据。
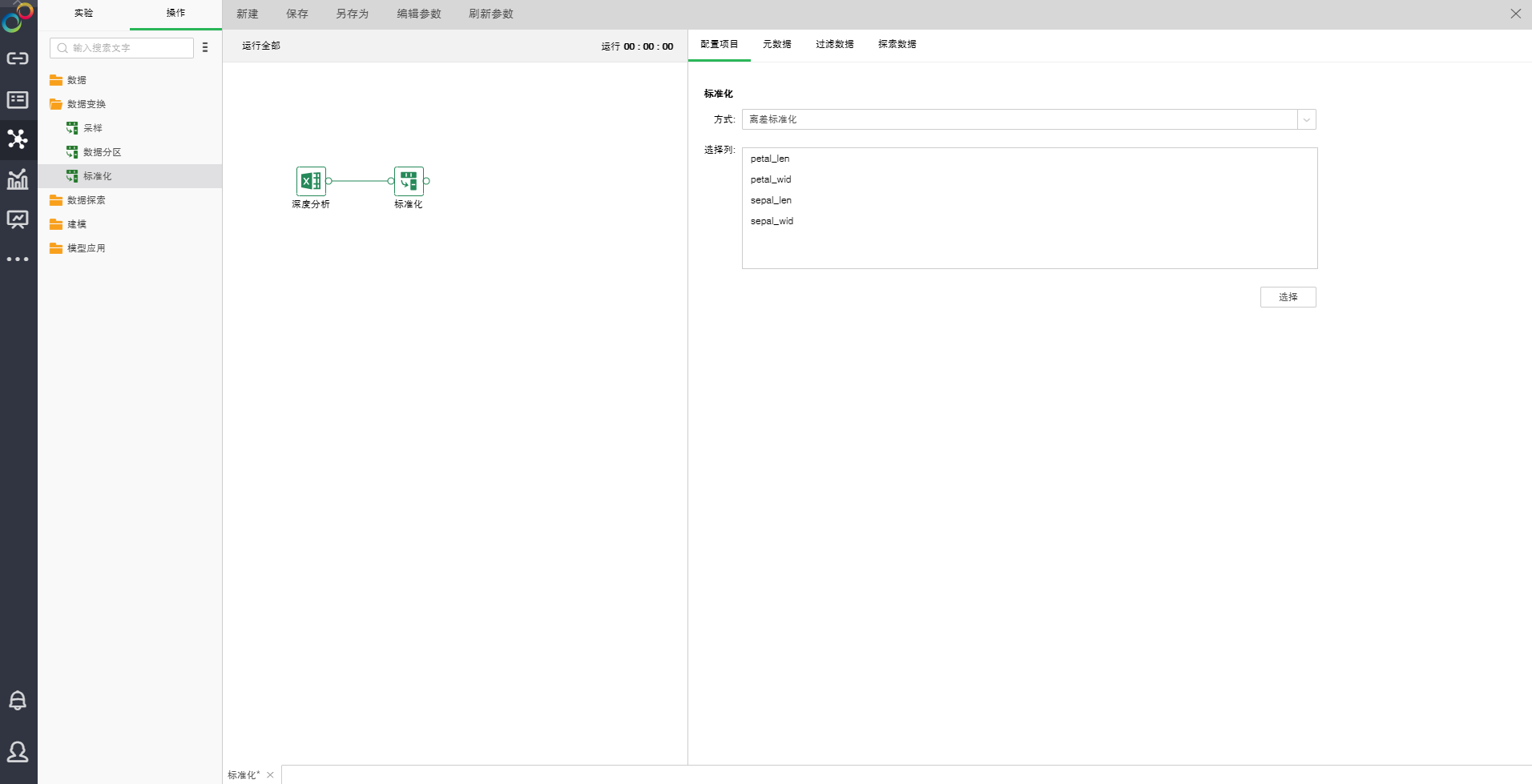
o配置项目
【方式】标准化方式有两种:离差标准化,Z-Score 标准化。离差标准化是对原始数据的线性变换,使结果落到[0,1]区间。Z-Score标准化处理的数据符合标准正态分布,即均值为0,标准差为1。
【选择列】需要被标准化的数据类型的列。
o元数据
请参考数据节点里的介绍。
o过滤数据
请参考数据节点里的介绍。
o探索数据
数据预览区增加显示标准化后的列。其它详细信息请参考数据节点里的介绍。