|
<< Click to Display Table of Contents >> 数据集市 |
|
|
<< Click to Display Table of Contents >> 数据集市 |
|
工业革命之后,书籍等以文字为载体的知识大约每十年翻一番; 1970 年以后,知识大约每三年就翻一番;如今,全球信息总量每两年就翻一番; 2010 年互联网的数据量,比之前所有年份的总和还要多。
现在,人类每天产生数以 PB 的数据。在互联网、电子商务、生产制造、交通和物流、金融和保险、医疗卫生、地理信息、政府机构等行业,每天都在创造着大量的数据。大数据正在成为从工业经济向知识经济转变的重要特征,已经成为新时代最关键的生产要素和产品形态。
Google、 Yahoo、 Facebook 等公司正成为这场变革的推动力量,同时新企业也层出不穷。在商业智能(BI)领域, AsterData、 Greenplum、 Vertica 等公司刚刚卓然而生,便被传统 IT 巨头 EMC、 IBM、 HP 等公司各自收入囊中。经过对这些新生公司的大数据技术进行消化和整合之后,传统 IT 巨头们迅速推出了各自的大数据产品和服务。
数据库时代之后,随着可用数据的持续积累,各行业的领军企业逐步开始了数据价值的发现之旅,这一阶段的商业智能系统,一般是以数据仓库 +OLAP 为主。一般地,传统数据仓库能够存储大数据,但并不提供针对大数据的分析和统计功能,因此,在开发 OLAP 这种数据应用时,需要用户预先提出的分析及统计的需求,再预先计算好这些主观的分析及统计的结果,才能确保 OLAP 系统的实时交互能力。然而,数据仓库 +OLAP 这一组合有着其先天的缺陷,在终端用户眼中也许是一个微小的变化,却可能需要很长的响应周期。行业内企业整体经营管理水平的持续提高,竞争态势不断加剧,这对每个企业尤其是领军企业带来了巨大的挑战。
要很好地应对这种挑战,保持行业优势地位,企业对商业智能系统的提出了更高的要求。永洪认为直接导入细节数据的这一数据建模技术,将数据和应用之间的关系从紧耦合改造成松耦合,让大多数分析应用不引起数据层的任何改变;而基于 MPP 架构的商业智能系统,能够直接对细节数据进行高性能分析。这样一来,用户可以快速开发出数据应用,并随即进行实时分析。建设随需应变的发现型、自服务商业智能系统。
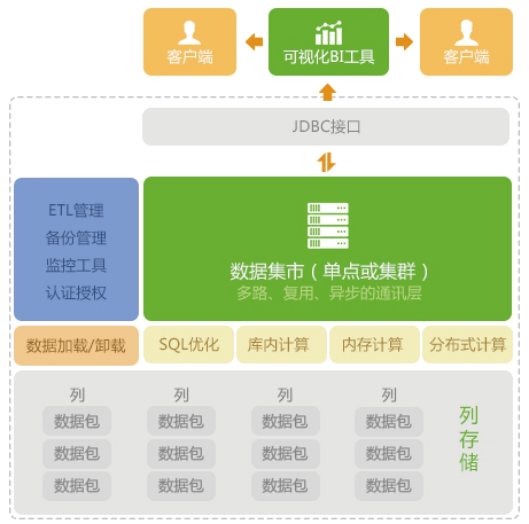
永洪 Z-Data Mart 是基于自有技术研发的一款数据存储、数据处理的数据集市产品。针对客户需要处理需求数据的量级不同, IT 系统架构的不同和存储系统的不同,提供了两种解决方案供客户选择一种本地模式,一种是 MPP 模式。当需要处理的数据量级别处于 TB 级以下,或者采用普通存储结构,或者单机已经足够满足性能需求,我们建议用户选择我们的本地模式。当面对异构数据库存储系统,需要处理的数量级别在 TB 级和 PB 级及以上,或者 IT 系统和存储系统采用分布式,或者需要 MPP 模式才能满足性能需求,基于分布式架构的并行处理模式更适合客户的需求。
她完全摒弃了向上升级 (Scale-Up),全面支持横向扩展 (Scale-Out)。
•跨粒度计算 (In-Database Computing)
Z-Suite 支持各种常见的汇总,还支持几乎全部的专业统计函数。得益于跨粒度计算技术, Z-Suite 数据分析引擎将寻找出最优化的计算方案,继而把所有开销较大的、昂贵的计算都移动到数据存储的地方直接计算,我们称之为库内计算 (In-Database)。这一技术大大减少了数据移动,降低了通讯负担,保证了高性能数据分析。
•并行计算 (MPP Computing)
Z-Suite 是基于 MPP 架构的商业智能平台,她能够把计算分布到多个计算节点,再在指定节点将计算结果汇总输出。 Z-Suite 能够充分利用各种计算和存储资源,不管是服务器还是普通的 PC,她对网络条件也没有严苛的要求。作为横向扩展的大数据平台, Z-Suite 能够充分发挥各个节点的计算能力,轻松实现针对 TB/PB 级数据分析的秒级响应。
•列存储 (Column-Based)
Z-Suite 是列存储的。基于列存储的数据集市,不读取无关数据,能降低读写开销,同时提高 I/O 的效率,从而大大提高查询性能。另外,列存储能够更好地压缩数据,一般压缩比在 5 -1 0 倍之间,这样一来,数据占有空间降低到传统存储的 1/5 到 1/10 。良好的数据压缩技术,节省了存储设备和内存的开销,却大大了提升计算性能。
•内存计算
得益于列存储技术和并行计算技术, Z-Suite 能够大大压缩数据,并同时利用多个节点的计算能力和内存容量。一般地,内存访问速度比磁盘访问速度要快几百倍甚至上千倍。通过内存计算, CPU 直接从内存而非磁盘上读取数据并对数据进行计算。内存计算是对传统数据处理方式的一种加速,是实现大数据分析的关键应用技术。