|
<< Click to Display Table of Contents >> K-Means聚类 |
  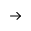
|
|
<< Click to Display Table of Contents >> K-Means聚类 |
|
K-Means是聚类算法中的一种,其中K表示类别数,Means表示均值。顾名思义K-Means是一种通过均值对数据点进行聚类的算法。K-Means算法通过预先设定的K值及每个类别的初始质心对相似的数据点进行划分,并通过划分后的均值迭代优化获得最优的聚类结果。
为了提升K-Means聚类的计算效率,产品支持分布式系统计算K-Means。当输入节点数据集是“数据集市数据集”时就是分布式计算的。
拖拽一个数据集和一个K-Means聚类节点到编辑区,连接数据集和K-Means聚类节点。

❖K-Means聚类模型的配置
添加K-Means聚类模型到实验后,可通过右侧的“配置项目”页面,对模型进行设置。
【训练模式】包含质心数、质心数范围。
【质心数】质心的个数。
【质心数范围】质心个数的范围。
【初始化质心】初始化质心的方法包括:随机距离、Kmeans++。随机距离是所有质心都是随机选取的。Kmean++是第一个质心是随机选取,其它质心按距离选取,距离其它质心越远被选中的概率越大。
【随机数种子】生成随机数的种子。默认值是0。
【距离计算方法】包括两张方法:欧式距离、余弦距离。欧式距离是两个数据点的实际距离。余弦距离是用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小的度量。
【最大迭代次数】迭代计算的最大次数,最终算出稳定的质心数。默认值100。
【缺失值填充】用自变量列平均值填充此列的空值。默认是填充的。
【标准化】对自变量标准化,默认标准化方式是Z-Score标准化。
【自变量】从选择列对话框中选出需要作为自变量的字段。
❖运行实验模型
当用户完成模型的配置后,点击K-Means聚类节点,右键菜单中选择“运行”,即可运行该模型,开始运行后,编辑区右上方开始计算运行时间。你也可以直接点击编辑区上方的“运行全部”来运行你所设置的实验模型。
运行成功后,会弹框输出模型结果,点击收缩图标,查看节点状态,显示节点成功,如下图所示。

如果运行失败,节点会提示失败,鼠标悬浮在节点上可查看失败原因,如下图所示。

❖查看模型结果
K-Means聚类模型运行成功后,会弹框输出模型结果,自动切换到“结果展示”页面,查看实验模型的结果,再次运行时则不会自动切换,可以手工切换至结果展示页面。
质心数为6,样本个数150,K-Means聚类展示结果如下:

•簇分布图
簇内的样本个数占总样本个数的比例。
•质心趋势图
各个质心在自变量上的变化趋势。
•聚类数据展现结果
根据前两个列绘制的聚类之后的散点图。
【预览行数】图表默认展示65535行数据,可修改此值改变预览行数。
•k均值聚类质心
质心在自变量上的取值。
•簇成员
样本分别属于哪个簇,距离质心的距离。
【预览行数】默认预览行数是1000,可修改预览行数。
【簇】分类编号。
【距离】不同距离计算方法计算出的每条样本到最近质心的距离值。
❖保存为训练模型
K-Means聚类模型运行成功后,可通过K-Means聚类节点连接“保存为训练模型”节点,运行保存。只有将模型保存为训练模型,才可以在制作报告模块进行可视化的应用。在左侧训练模型的目录下,可以查看K-Means聚类训练模型。
以“案例分析/员工离职”为例,选中K-Means聚类节点,节点的配置项目如下图:
配置项目,在弹出的保存为训练模型的对话框中,可选择路径,名字默认是节点名称也可修改名字,点击确定后将模型保存到资源树上的训练模型文件夹下。
打开保存好的训练模型“K-Means聚类”,展示信息包含三部分:标题,基础属性,模型训练汇总。标题为训练模型的名称;基础属性是配置项目里所有属性的值;模型训练汇总部分显示实验节点的来源,算法,类别,时间因素。具体展示如下:
|
❖保存为数据集
10万以内的数据支持保存为内嵌数据集,超过10万不允许保存为内嵌数据集。保存的数据集可以在创建数据集模块中查看。点击此处可查看“保存为数据集”的示例。
➢ 例如:K-Means聚类节点保存为数据集后,元数据如下:
预览后数据如下:
|
❖导出到数据库
将节点数据导入所选数据库指定的表中。点击此处查看“导出到数据库”的过程。
以实验“案例分析/客户流失”为例,选中节点连接导出到数据库节点,如下图所示:
1.模型节点:导出到数据库的节点路径和名称。 2.数据源:用户根据需求选择已存在的数据源。目前支持的数据库类型为 "Mysql", "Oracle", "SQLServer", "DB2", "PostgreSQL", "Derby"。 3.数据库:所选数据源的默认数据库。支持的数据库为"Mysql","SQLServer"。 4.表结构模式:所选数据源的表结构模式。支持的数据库为 "PostgreSQL","SQLServer","DB2" ,"Oracle","Derby"。 5.表名:指定数据库的表名,数据集结果会插入到该表中。 6.追加:当用户勾选追加时,表中原先的数据仍然存在,数据集的结果直接插入表中。当用户不勾选追加时,会先删除表中已存在的数据,然后再插入数据集结果到表中。 |
❖保存为PMML文件
当模型节点训练完成后会生成与之对应的PMML文件,用户可通过K-Means聚类连接“保存为PMML文件”,将生成的PMML文件导出到本地,进而用于其他的平台使用。
说明:只有欧式距离的K-Means聚类模型支持PMML导出功能。
❖K-Means聚类节点重命名
在K-Means聚类节点的右键菜单中,选择“重命名”,可以对节点进行重命名。
❖删除K-Means聚类节点
在K-Means聚类节点的右键菜单中,选择“删除”或者点击键盘 delete 键进行删除,能够删除节点以及节点的输入、输出连线。
❖刷新K-Means聚类节点
在K-Means聚类节点的右键菜单中,选择“刷新”,可以更新同步数据或者参数信息。