|
<< Click to Display Table of Contents >> K-Means聚类 |
|
|
<< Click to Display Table of Contents >> K-Means聚类 |
|
❖员工离职率分析
企业通过构建K-Means聚类分析模型,对员工进行分类,尽早识别可能离职的员工。针对性采取相关措施,降低员工离职给公司带来的损失。
•数据准备及相关分析
拖拽数集据节点“HR”到编辑区,添加相关分析节点去连接数据集节点。
配置相关性分析节点,相关系数选择Pearson,在相关列中,添加入职年限,员工水平,完成项目数,平均每月工作时长,是否失误,是否离职,最近5年是否升职,满意度。
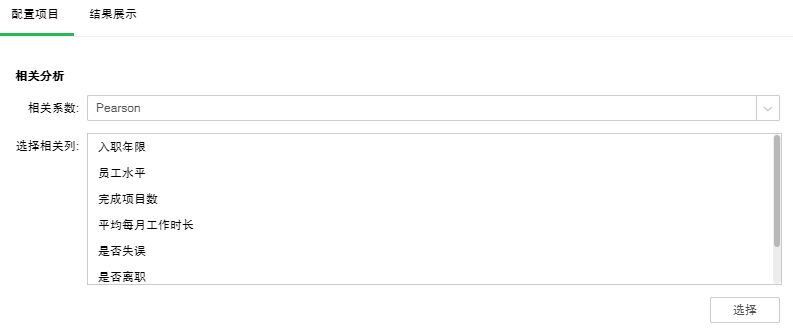
点击结果展示,是否离职与员工满意度的相关系数为-0.388,员工水平与完成的项目数的相关系数为0.349,完成项目数和平均每月工作时长相关系数为0.417,都在低相关的范围内。
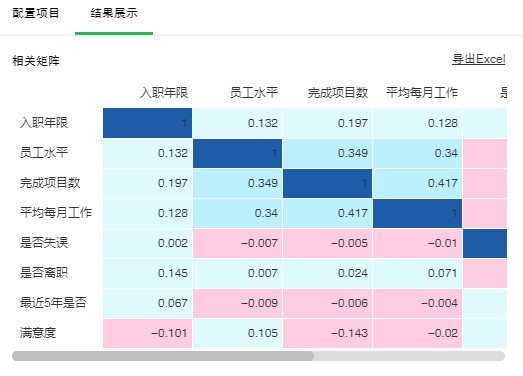
➢相关系数的大小说明:|r|>0.95 存在显著性相关;|r|≥0.8 高度相关;0.5≤|r|<0.8 中度相关;0.3≤|r|<0.5 低度相关;|r|<0.3 关系极弱,认为不相关。
•K-Means聚类
o配置项目
添加K-Means聚类节点,连接数据集节点;配置参数,选择质心数,设置为3,初始化质心选择随机距离,随机数种子设置为0,距离计算方法选择欧式距离。默认选择缺失值填充,不选择标准化;添加满意度和员工水平作为自变量。

o运行
配置完参数后,K-Means聚类节点处于未运行状态。
在K-Means聚类节点右键选择运行,运行成功后,节点展示如下:
o结果展示
点击结果展示,通过结果我们可以看到,按照满意度和员工水平员工明显分为3类,分类情况如下图:
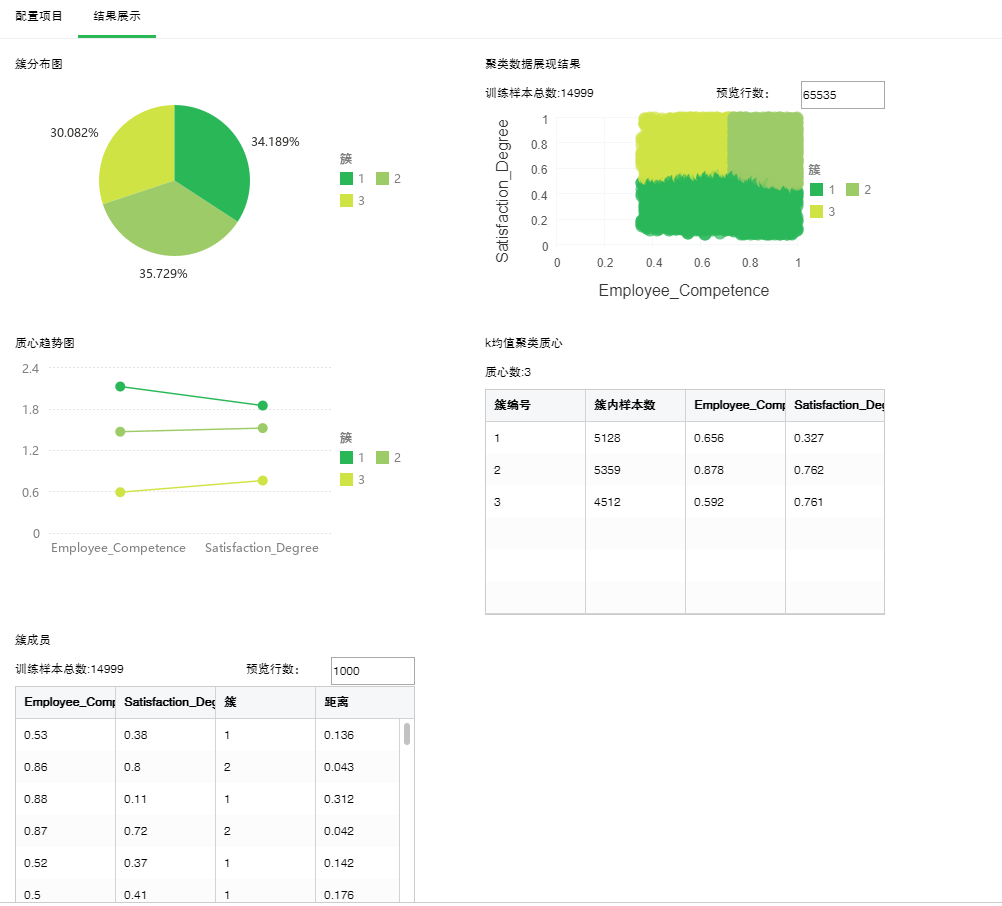
通过k均值聚类质心表格可以看出3个质心的具体值和每个簇内的样本总数;通过簇成员表格可以看出每个簇内样本的细节数据和计算出的距离质心的距离。
•模型应用
o模型在仪表盘中的应用
选择K-Means聚类节点,保存为训练模型,保存的模型可以应用在制作报告仪表盘的组件绑定的数据集上。
1. 在制作报告处选择数据集新建报表,右键选择应用训练模型。在数据集树上右键选择应用训练模型:
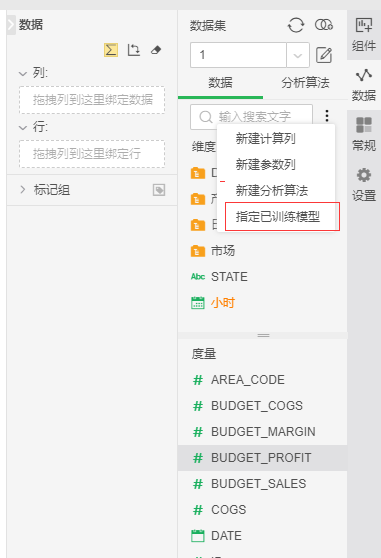
2. 打开应用训练模型对话框,此对话框内只显示可应用在此绑定的数据集上的模型。
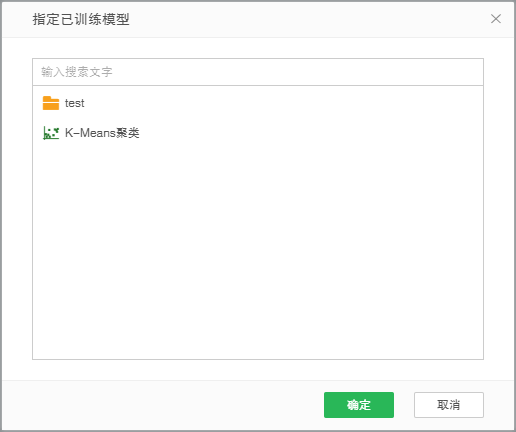
3. 选择保存的训练模型“K-Means聚类“,点击确定,会新生成2列,簇和距离。簇:聚类分类的结果;距离:该点和质心的距离。
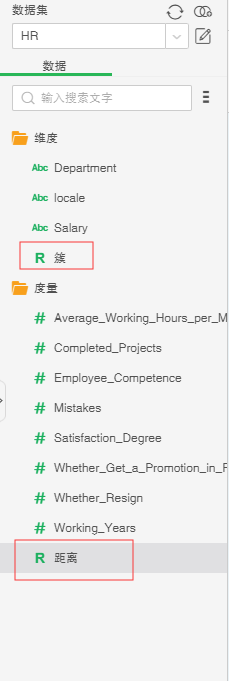
4. 基于应用模型的结果,新建表达式,将这三类重新命名如下:
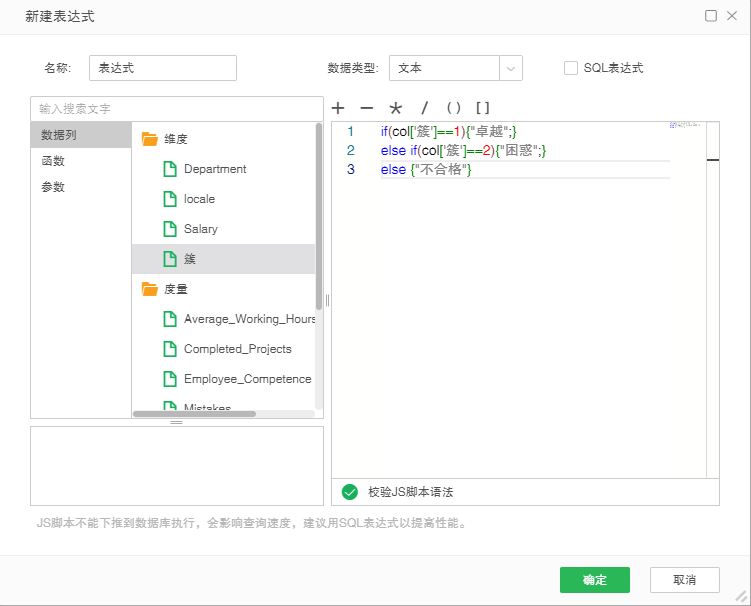
5. 将数据如下绑定到图表组件上,选择线图。
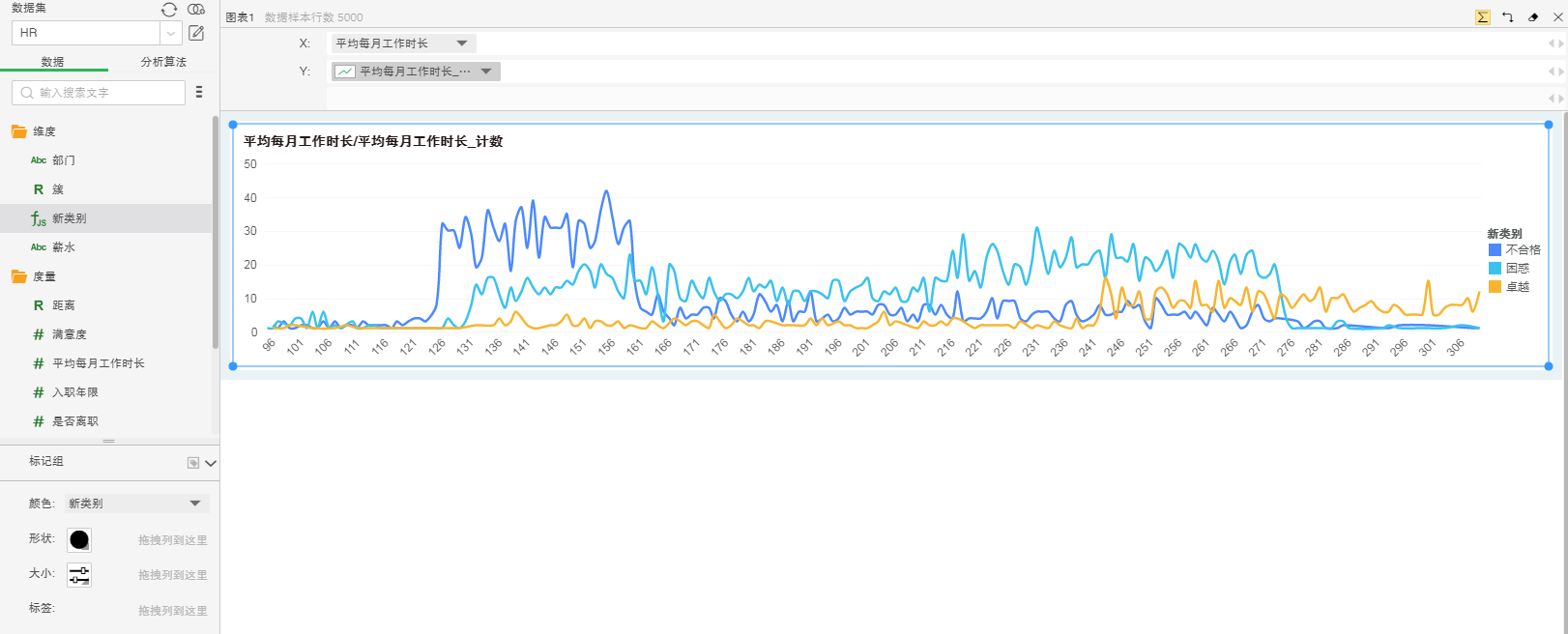
6. 在行轴的字段上设置动态计算器:汇总百分比;去掉标记上的点,修改大小得出以下结果图;从上图可以看出,不合格者每月工作时长集中于左侧(偏低),困惑者工作时长最长,卓越者次之。

o评分
具体用法请参考深度分析实验及应用的逻辑回归章节。