|
<< Click to Display Table of Contents >> 多分类_决策树分类 |
|
|
<< Click to Display Table of Contents >> 多分类_决策树分类 |
|
决策树分类器,采用决策树算法进行分类模型训练。
用法:
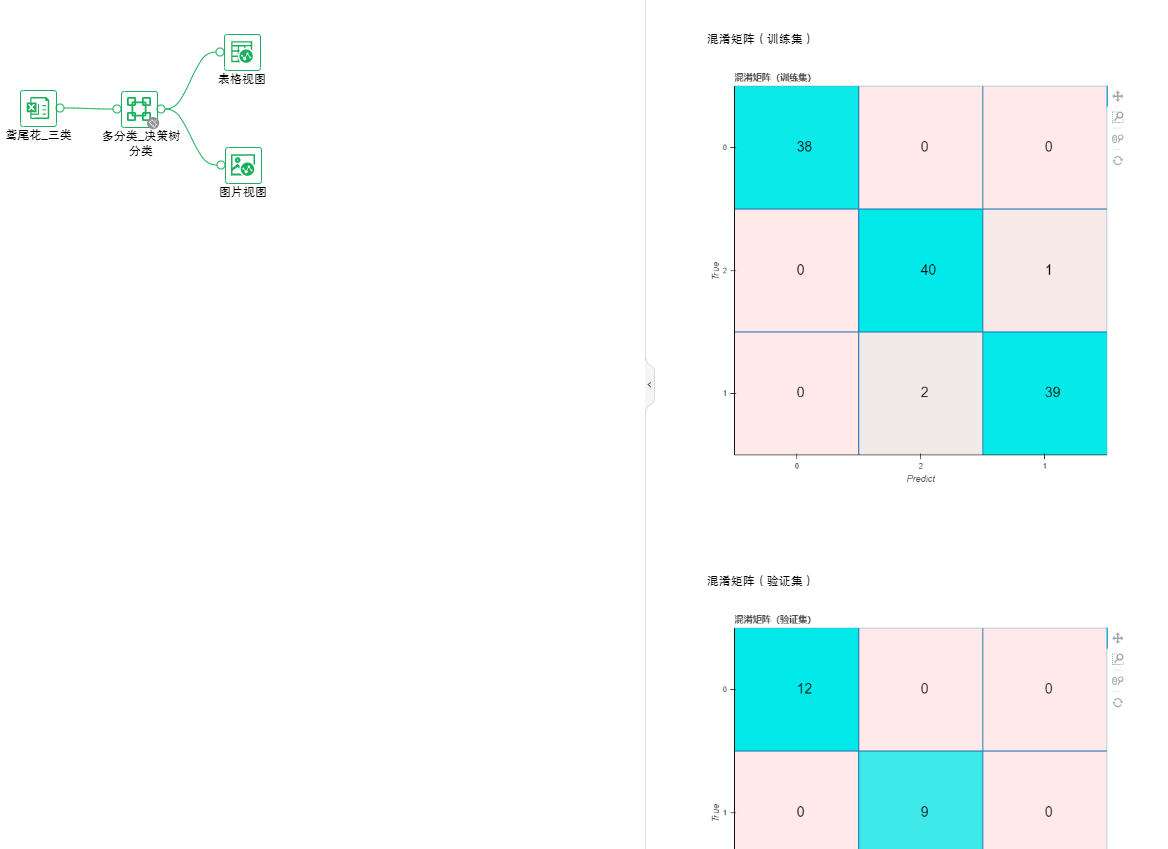
该节点接收数据集节点的输入。设置多分类_决策树分类后,可通过连接表格视图来查看性能指标;连接图片视图来查看混淆矩阵。
注意事项:
【目标列】只能选择一个字段。
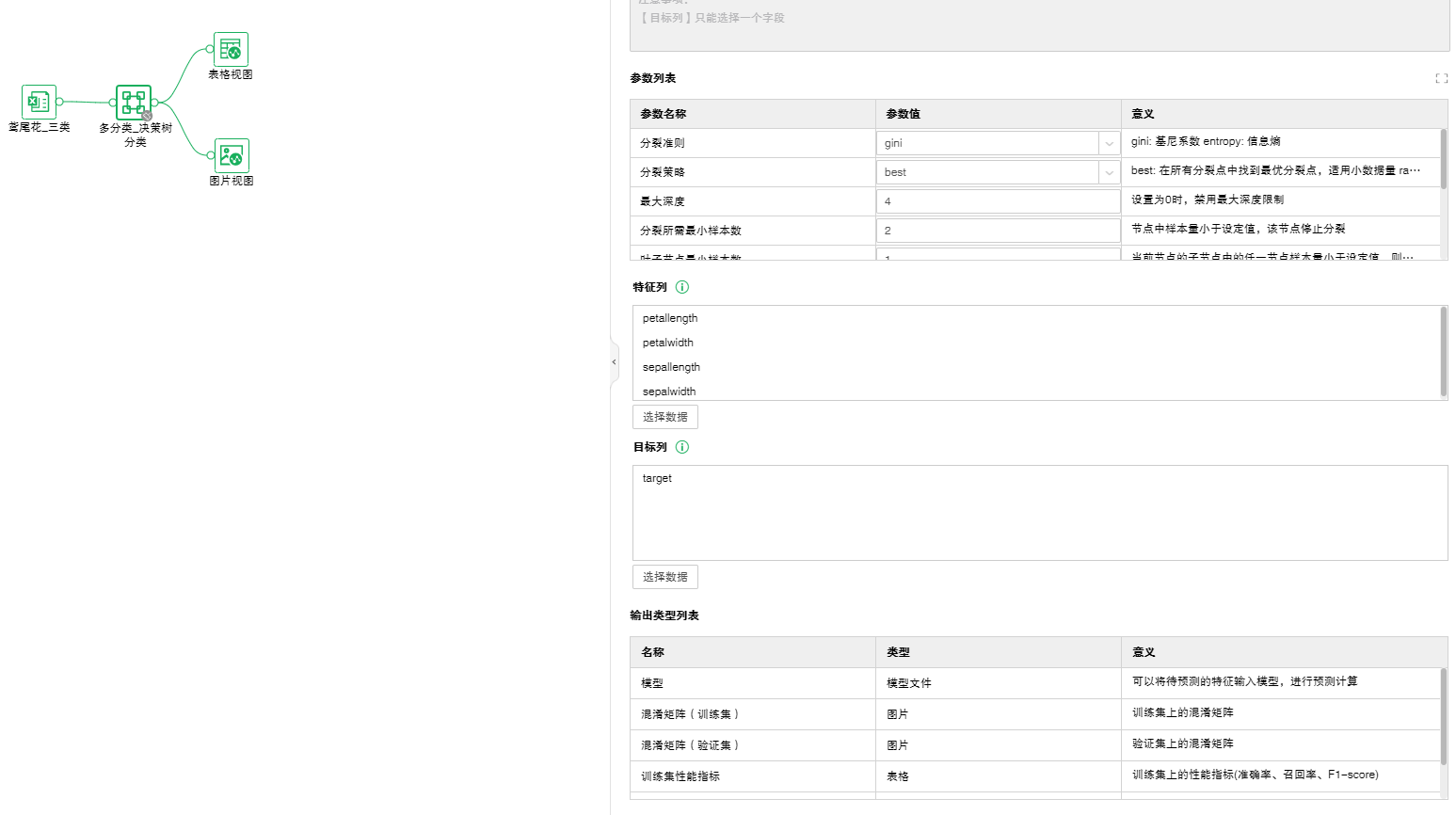
❖多分类_决策树分类节点的配置方法
将多分类_决策树分类节点添加到实验后,可通过右侧的“配置项目”页面,对多分类_决策树分类节点进行设置。
【分类准则】分为两种:gini: 基尼系数;entropy: 信息熵。
【分裂策略】best: 在所有分裂点中找到最优分裂点,适用小数据量;random: 随机在部分分裂点中找到局部最优分裂点,适用大数据量。
【最大深度】设置决策时的最大深度。设置为0时,禁用最大深度限制。
【分裂最小样本数】节点中样本量小于设定值,该节点停止分裂。
【叶子节点最小样本数】当前节点的子节点中的任一节点样本量小于设定值,则所有子节点被剪枝。
【叶子节点最小样本权值和】当前节点的子节点所有样本权重之和小于设定值,则所有子节点被剪枝。
【最大特征数】auto: 最大特征数=sqrt(特征总数) sqrt: 最大特征数=sqrt(特征总数) log2: 最大特征数=log2(特征总数) None: 最大特征数=特征总数
【随机种子】设置为0时,禁用随机种子。
【最大叶子节点】限制整棵树的叶子节点总数,设置为0时,禁用最大叶子节点数。
【最小不纯度降低值】当前节点分裂后的不纯度降低值小于设定值,则所有子节点被剪枝。
【类别权重】balanced: 自动平衡样本;None: 不进行样本平衡。
【训练集占比】通常训练集在整个数据集的占比为0.8,剩下的作为验证集。
【特征列】选择前置节点的特征列,可以为多列。
【目标列】选择前置节点的目标列,只能为1列,有分类属性的数据。
多分类_决策树分类节点右键菜单
❖多分类_决策树分类节点运行
运行节点,将数据传递给DM-Engine进行计算,得到输出结果。
❖多分类_决策树分类节点重置
已经运行过的节点进行重置,删除返回的结果,节点状态更改为未运行。
❖多分类_决策树分类节点重命名
在多分类_决策树分类节点的右键菜单中,选择“重命名”,可以对节点进行重命名。
❖删除多分类_决策树分类节点
在多分类_决策树分类节点的右键菜单中,选择“删除”或者点击键盘 delete 键进行删除,能够删除节点以及节点的输入、输出连线。
❖刷新多分类_决策树分类节点
在多分类_决策树分类节点的右键菜单中,选择“刷新”,可以更新同步数据或者参数信息。