|
<< Click to Display Table of Contents >> 其它性能提升 |
|
|
<< Click to Display Table of Contents >> 其它性能提升 |
|
❖表达式运算执行效率提升
目前,关于表达式的处理部分,一部分表达式使用产品自带的处理引擎,一部分表达式使用 js 引擎(jsEngine)来处理。一个表达式 , 既有系统支持的表达式 , 又有系统不支持的表达式 , 则还是会用 js 引擎(jsEngine)解析。
在处理大数据量的集市数据时,由 jsEngine 处理的表达式效率要比产品自身支持的表达式的效率低,因此为了提高表达式的处理效率,7.0 版本对产品自身支持的表达式范围进行了扩展,主要新增了对以下几个表达式的支持:
函数 |
说明 |
|---|---|
Right |
截取字符串右边特定长度, 如果字符串长度不够以字符 串长度为准 |
Left |
截取字符串左边特定长度, 如果子字符串长度不够以字 符串长度为准 |
Trim |
去掉字符串两边的空格 |
Upper |
把字符串字符都转化成大写 |
Lower |
把字符串字符都转化成小写 |
Weekdayname |
获取星期中的序号, 比如默认星期天是1 |
Year |
返回日期的年份 |
Month |
返回日期的月份 |
parseDate |
把字符串解析成日期 |
FormatDate |
把日期格式化成字符串 |
❖Local Reduce优化
MPP数据集市在数据节点(Map节点)可提前进行局部的Reduce计算,即Local Reduce。
在一些计算场景中,有自助分析类的报表,这类报表依赖的数据集一般比较大,而且绑定维度不固定,结果集可能会比较大。当结果集较大时,reduce节点的处理内存很容易成为瓶颈,无法满足计算处理需要,因此对Local Reduce进行了优化,当计算满足Local Reduce的时候,在Map节点等待一定时间来尽可能多的进行Local Reduce计算,充分利用集市计算资源,达到提升集市计算处理速度的目标。
目前Local Reduce主要从这几个方面判定Map结果是否需要进行Local Reduce运算:
•汇总计算且Map计算的结果集小于500000;
•当前local reduce的压缩比率小于0.33;
•在map完成时已经有local reduce的执行,且满足上面两条。
❖多Reduce 节点参与聚合计算
多Reduce节点参与聚合计算,将结果返回client节点进行结果集合并。不仅可以提高计算的并行度,缓解Reduce节点内存占用的压力,还可以实现流式处理效果,及时将单个Reduce计算结果返回给后续计算使用。
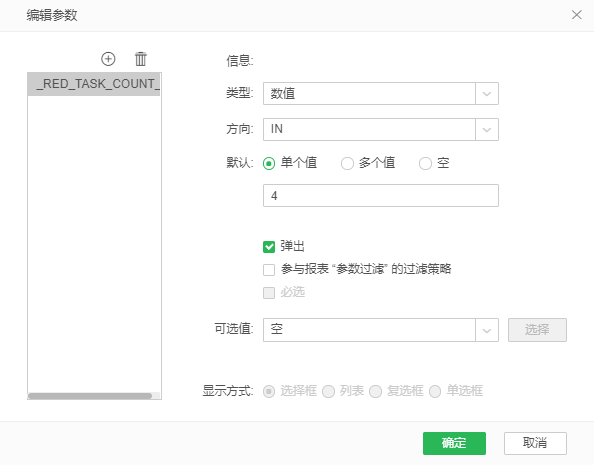
注意:默认情况下,仍然是单Reduce节点参与聚合计算。如需多Reduce节点参与,可在数据集或制作报告模块添加参数_RED_TASK_COUNT_(默认值为1)。该参数值代表有几个Reduce节点参与计算。前提是,用户具有足够的Reduce节点。
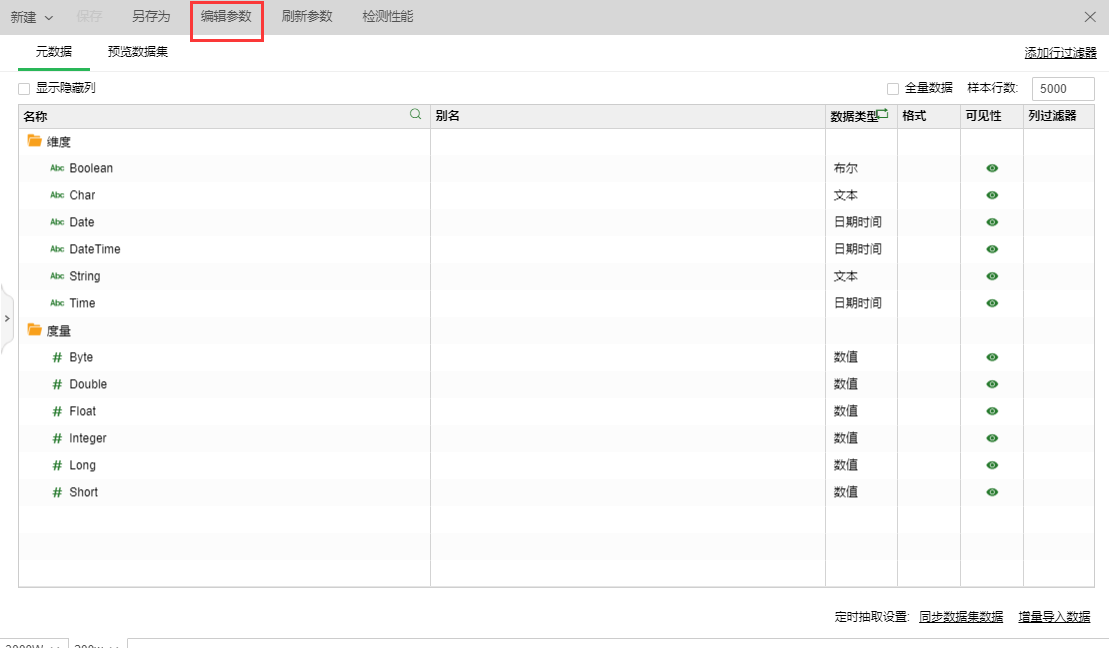
1.多Reduce的开关通过参数控制,在创建数据集界面或制作报告界面,点击编辑参数,如下图所示
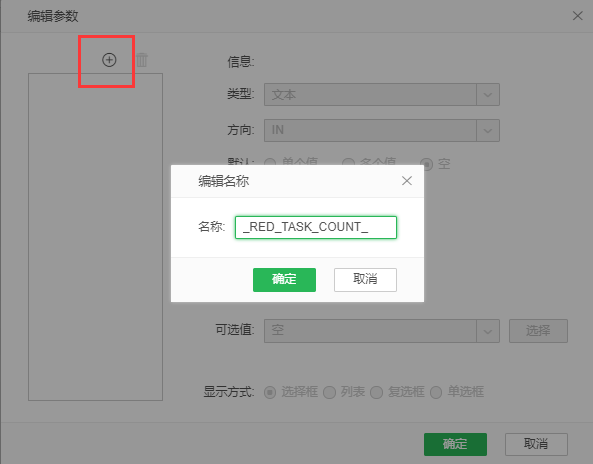
2.点击添加参数,编辑名称中输入 _RED_TASK_COUNT_,点击确定,如下图所示。
3.设置参数类型为数值类型,勾选单个值,并输入需要参与计算的Reduce节点数量,点击确定。以需要参与Reduce计算的数量为4举例:如下图所示
❖管理任务和计算任务隔离
产品中很多地方采用了线程池,异步执行的线程池任务带来一些问题是会有等待的任务。将管理类型的任务和计算类型的任务进行物理隔离,当出现任务排队时,不会有互相影响的情况发生。
•相关属性配置:
以下属性配置中的值都是系统默认值,可根据使用情况来决定是否进行调整,一般使用默认值即可。
属性 |
说明 |
|---|---|
performance.channel.separate=true |
定义是否开启管理任务和计算任务隔离,默认开启。 |
❖表达式落盘优化
针对集市数据表达式的列内容作压缩处理。在计算出表达式值后,对内容进行压缩处理,减少内存和磁盘占用,从而落盘文件也实现存储压缩。