|
<< Click to Display Table of Contents >> 算法 |
|
|
<< Click to Display Table of Contents >> 算法 |
|
❖算法
该算法指Y-AI的插件化算子,包含分类、关联规则、回归、聚类和时间序列五种类型的算子。其中,分类又包含决策树多分类、决策树二分类和逻辑回归三种分类算法;关联规则内置了FP-Growth算法,回归包含决策树回归和线性回归两种回归算法;聚类内置了Kmeans聚类算法;时间序列内置了Holt-Winters算法。
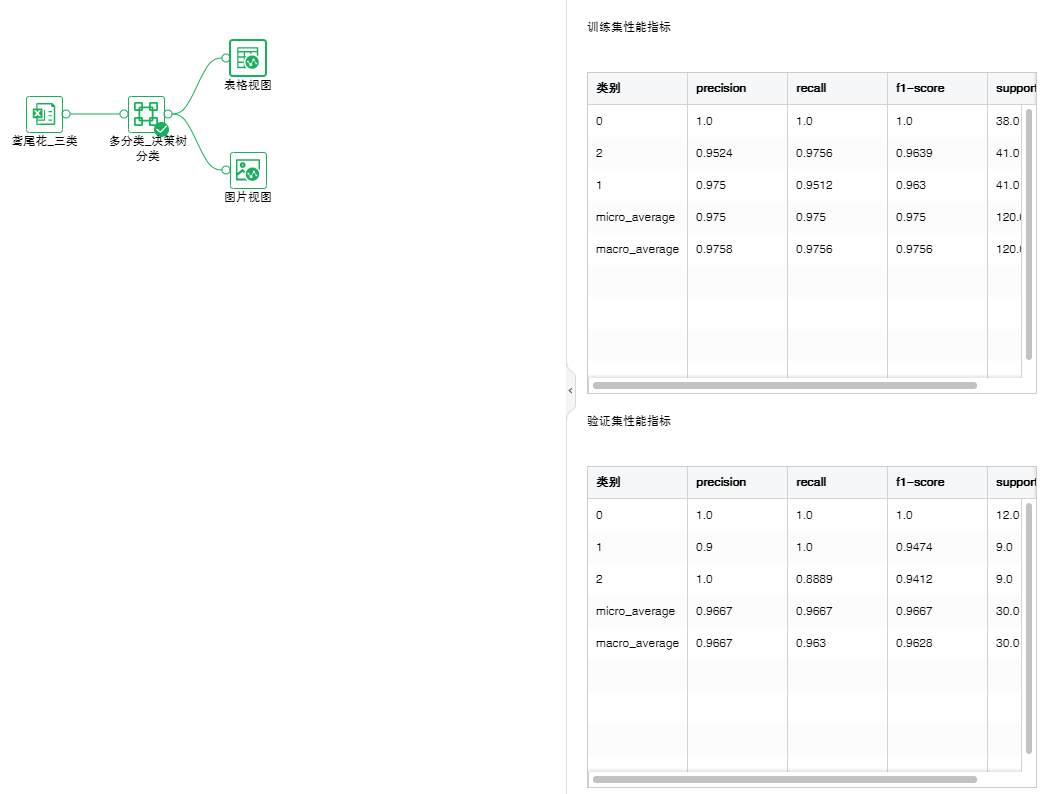
•分类-决策树多分类
决策树分类,采用决策树算法进行分类模型训练,适用于目标列多于2个的情况。
参数列表:通过设置决策树分类算法的各项参数,来进行模型训练,以达到最优分类效果。
输出列表:模型、性能指标、混淆矩阵、PMML文件。
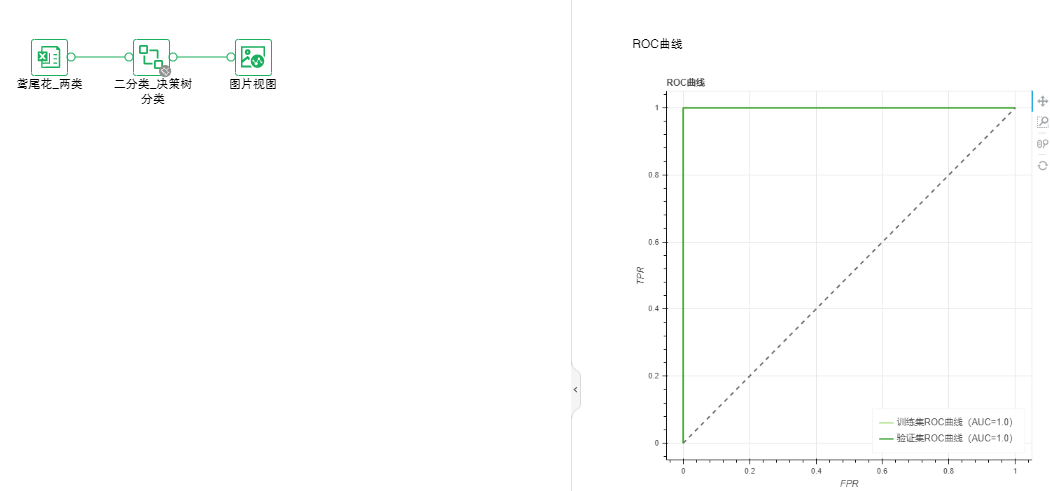
•分类-决策树二分类
决策树分类,采用决策树算法进行分类模型训练,适用于目标列为2个的情况。
参数列表:通过设置决策树分类算法的各项参数,来进行模型训练,以达到最优分类效果。
输出列表:模型、模型系数、性能指标、ROC曲线、PMML文件。
•分类-逻辑回归
逻辑回归属于机器学习算法有监督问题,主要解决二分类问题。
参数列表:选择正例标签和算法需要用的优化器。
输出列表:模型、ROC曲线、性能指标、PMML文件。

•关联规则-FP-Growth
在交易数据、关系数据或其他信息载体中,查找存在于项目集合或对象集合之间的频繁模式、关联、相关性或因果结构关联规则挖掘过程主要包含两个阶段:第一阶段必须先从资料集合中找出所有的高频项目组,第二阶段再由这些高频项目组中产生关联规则。
参数列表:最小支持数和最小置信度
输出列表:关联关系挖掘结果、关联关系图
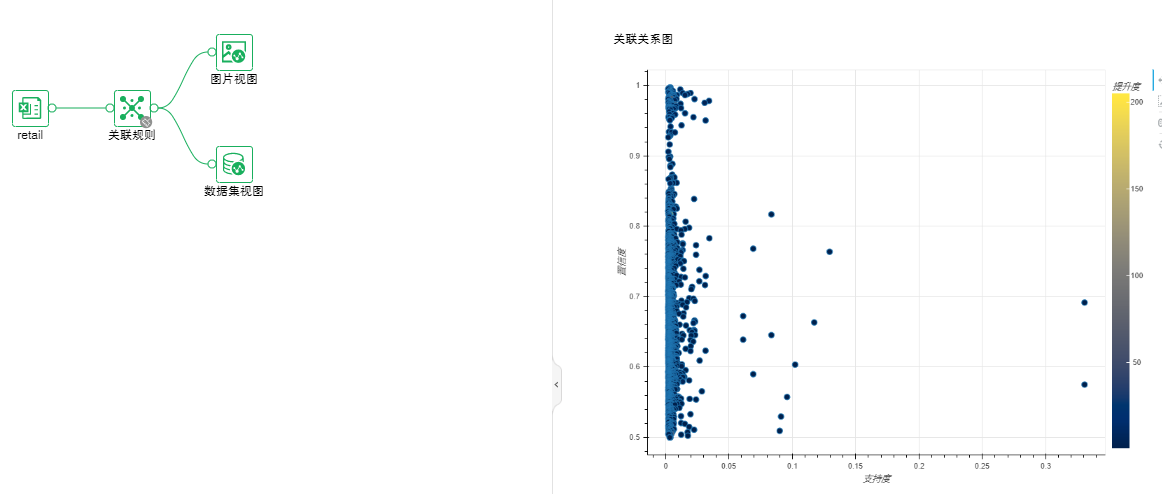
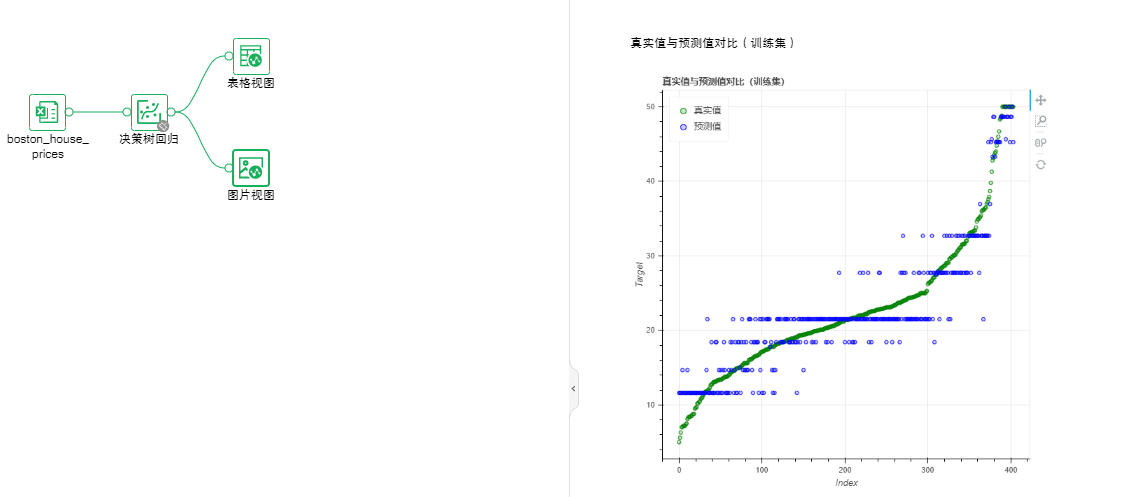
•回归-决策树回归
用决策树算法进行回归模型训练。
参数列表:决策树算法参数
输出列表:模型、真实值与预测值对比、性能指标、PMML文件。
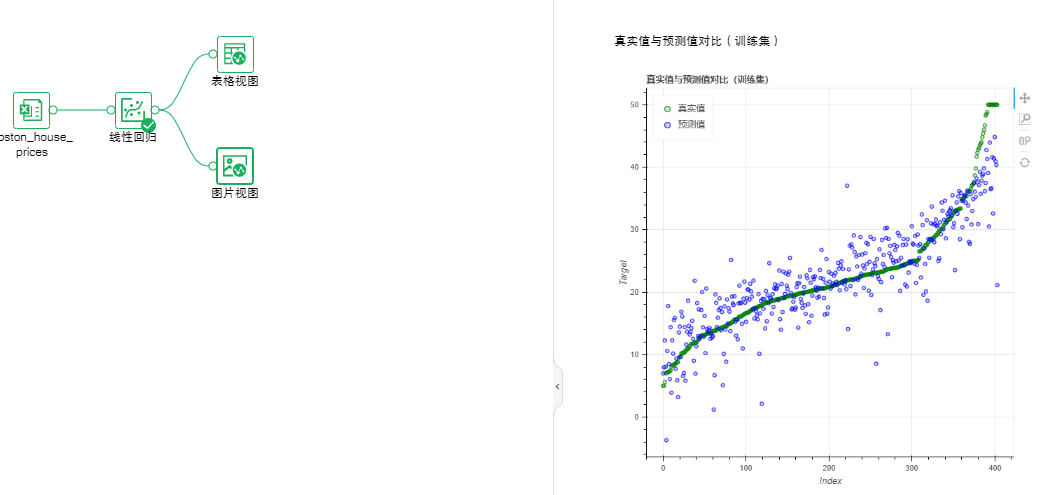
•回归-线性回归
线性回归方程是利用数理统计中的回归分析,来确定两种或两种以上变数间相互依赖的定量关系的一种统计分析方法之一。
参数列表:训练集占比
输出列表:模型、真实值与预测值对比、性能指标、模型系数、PMML文件。
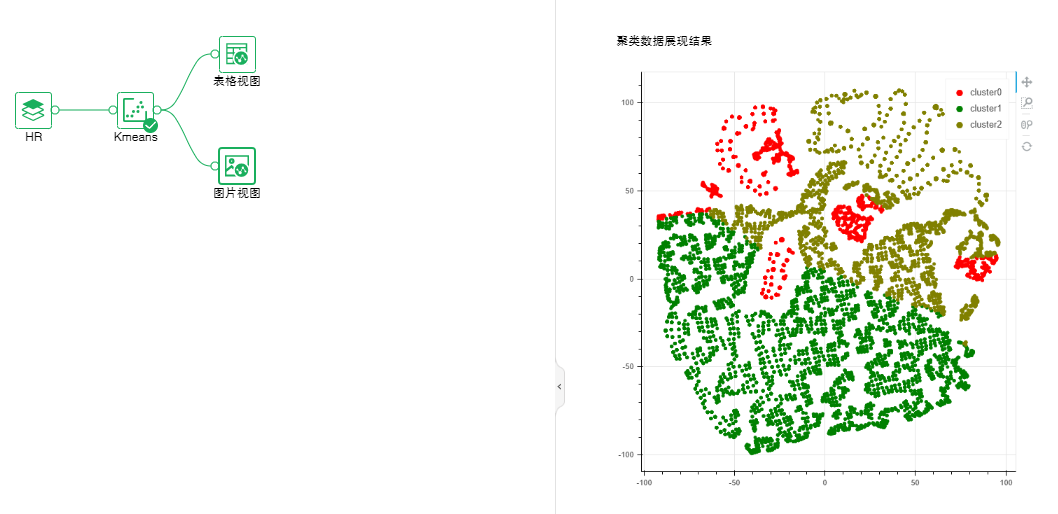
•聚类-Kmeans聚类
该算子可用于对无标签的数据进行分类,属于无监督学习。
参数列表:训练集占比
输出列表:模型、聚类质心和性能指标、聚类数据展现结果。
•时间序列-Holt-Winters
用于分析一个随时间变化的数值型变量,根据历史数据,预测未来变量情况。
参数列表:时序分析算法要求的周期、单位等。
输出列表:预测结果、预测数据、性能指标。
