|
<< Click to Display Table of Contents >> 决策树 |
|
|
<< Click to Display Table of Contents >> 决策树 |
|
决策树是一种用于对实例进行分类的树形结构。决策树由节点(node)和有向边(directed edge)组成。节点的类型有两种:内部节点和叶子节点。其中,内部节点表示一个特征或属性的测试条件(用于分开具有不同特性的记录),叶子节点表示一个分类。
一旦我们构造了一个决策树模型,以它为基础来进行分类将是非常容易的。具体做法是,从根节点开始,用实例的某一特征进行测试,根据测试结构将实例分配到其子节点(也就是选择适当的分支);沿着该分支可能达到叶子节点或者到达另一个内部节点时,那么就使用新的测试条件递归执行下去,直到抵达一个叶子节点。当到达叶子节点时,我们便得到了最终的分类结果。
拖拽一个数据集和一个决策树节点到编辑区,连接数据集和决策树节点。
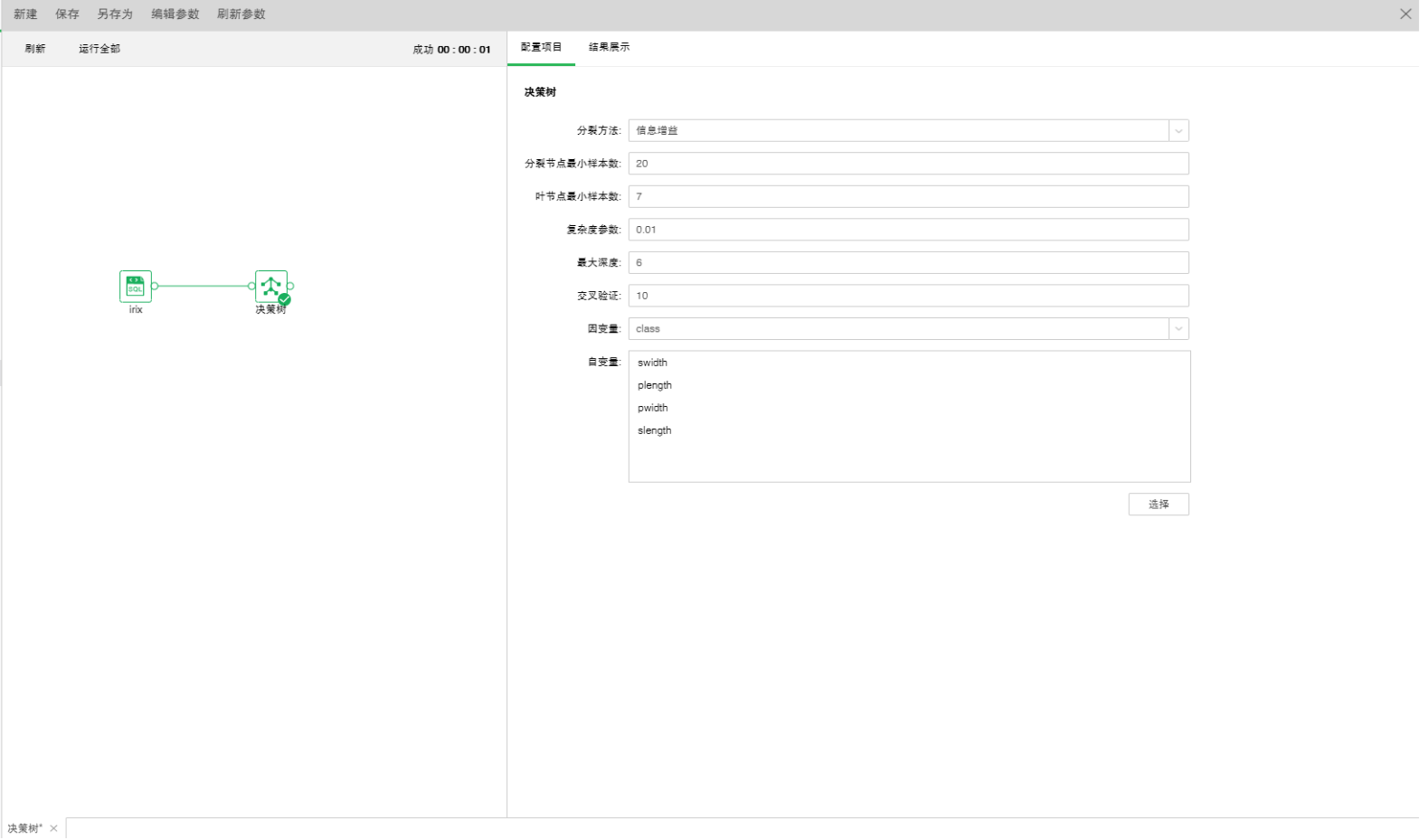
❖决策树模型的配置
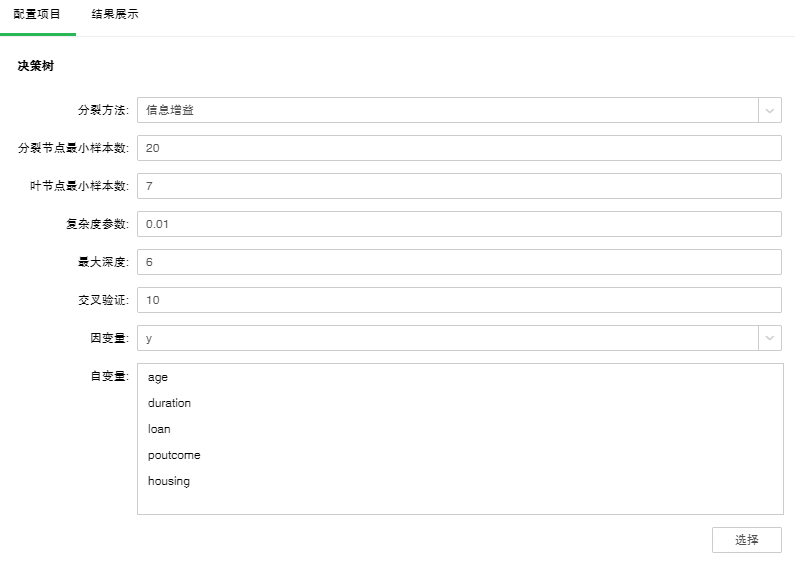
添加决策树模型到实验后,可通过右侧的“配置项目”页面,对模型进行设置。
【分裂方法】包含信息增益和Gini系数。
• 信息增益:划分前后,子集纯度的提升值。
• Gini系数:在样本集合中一个随机选中的样本被分错的概率。
【分裂节点最小样本数】样本数小于该值该节点将不进行分裂。默认值20。
【叶节点最小样本数】样本数小于该值,该分支将被剪除。默认值7。
【复杂度参数】每次分裂会计算一个复杂度,当复杂度大于该参数值不再进行分裂。默认值0.01。
【最大深度】决策树的最层次数。默认值6。
【交叉验证】通过交叉验证可以得到最优的方程。默认值是10。
【因变量】从下拉列表中选出需要作为因变量的字段。任何一个系统(或模型)都是由各种变量构成的,当我们分析这些系统(或模型)时,可以选择研究其中一些变量对另一些变量的影响,那么我们选择的这些变量就称为自变量,而被影响的量就被称为因变量。
【自变量】从选择列对话框中选出需要作为自变量的字段。
❖运行实验模型
当用户完成模型的配置后,点击决策树节点,右键菜单中选择“运行”,即可运行该模型,开始运行后,编辑区右上方开始计算运行时间。你也可以直接点击编辑区上方的“运行全部”来运行你所设置的实验模型。
运行成功后,会弹框输出模型结果,点击收缩图标,查看节点状态,显示节点成功,如下图所示。
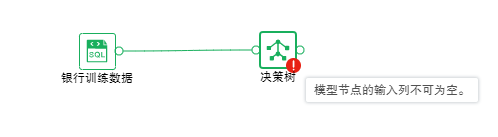
如果运行失败,节点会提示失败,鼠标悬浮在节点上可查看失败原因,如下图所示。
❖查看模型结果
决策树模型运行成功后,会弹框输出模型结果,自动切换到“结果展示”页面,查看实验模型的结果,再次运行时则不会自动切换,可以手工切换至结果展示页面。
•树形结果
分类结果有两种,二分类和多分类。当因变量只有两个不同值时是二分类;当因变量有多于两个不同值时是多分类。节点最上方是节点编号。节点内有两行,第一行是该节点最终分类;当为多分类时第二行是该节点各种分类的概率值,当为二分类时第二行是该节点是主分类的概率值。yes和no代表是否满足条件,来确定分支方向。节点颜色代表纯度。
二分类树形结果展示如下:
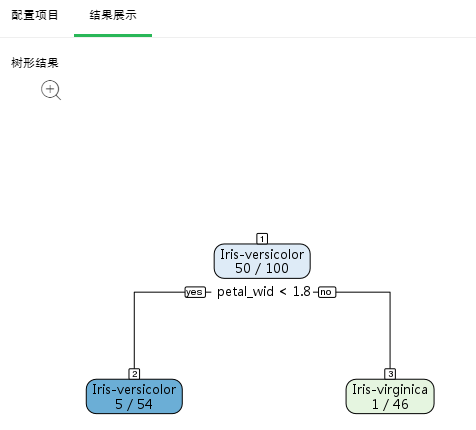
➢注意:主分类是绿色节点,蓝色节点的5/54表示Iris-versicolor是Iris-virginica的概率值。
多分类树形结果展示如下:
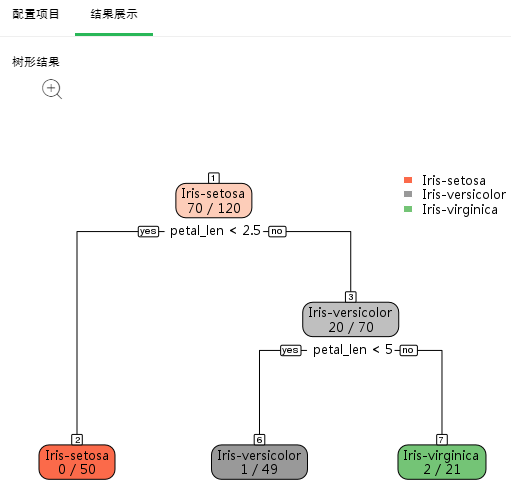
点击放大按钮,可放大图片以更清晰的查看图片。
•节点分类情况
列出所有叶子节点的信息。
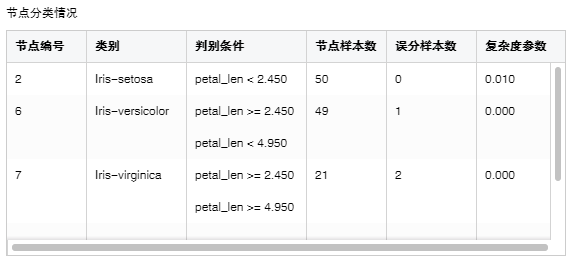
【节点编号】叶子节点的编号。
【类别】叶子节点的类别。
【判别条件】从根部到该叶子节点的判别条件。
【节点样本数】叶子节点的样本数。
【误分样本数】错误分类的样本数。
【复杂度参数】每个叶子节点的复杂度参数。
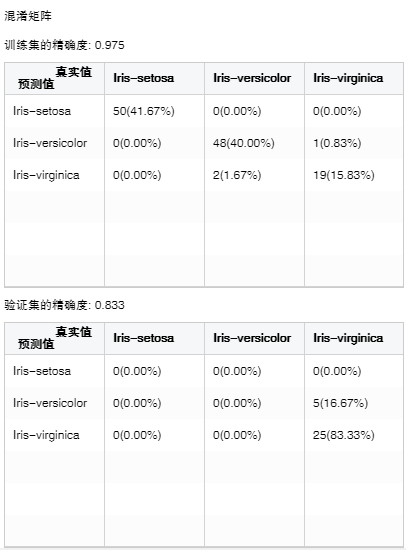
•混淆矩阵
预测结果的情形分析表,当有数据分区时还可查看验证集的分析表。
横向表头是真实值,纵向表头是预测值。整数值代表样本个数,百分数是样本个数占总样本个数的比例。精确度为真实值和预测值相同的比例总和。
❖保存为训练模型
决策树模型运行成功后,可通过连接“保存为训练模型”节点将模型保存。只有将模型保存为训练模型,才可以在制作报告模块进行可视化的应用。在左侧训练模型的目录下,可以查看决策树训练模型 。
以“案例分析/银行电话营销”为例,选中决策树节点,节点的配置项目如下图:
保存为训练模型,并且打开保存的训练模型,信息展示如下:
|
❖保存为PMML文件
当模型节点训练完成后会生成与之对应的PMML文件,用户可通过连接保存为PMML文件节点,选择“保存为PMML文件”,将生成的PMML文件导出到本地,进而用于其他的平台使用。
❖决策树节点重命名
在决策树节点的右键菜单中,选择“重命名”,可以对节点进行重命名。
❖删除决策树节点
在决策树节点的右键菜单中,选择“删除”或者点击键盘 delete 键进行删除,能够删除节点以及节点的输入、输出连线。
❖刷新决策树节点
在决策树节点的右键菜单中,选择“刷新”,可以更新同步数据或者参数信息。