|
<< Click to Display Table of Contents >> 增量导入数据 |
|
|
<< Click to Display Table of Contents >> 增量导入数据 |
|
增量导入数据,即定期的按照某种条件将数据导入到VooltDB数据库中。
执行增量导入数据时,会将数据导入到VooltDB数据库中。比如,由于数据库中的数据可能会更改,故用户可创建增量导入数据任务每天八点对特定的数据集中的数据进行监视,以便用户及时做出处理。
新建增量导入数据的步骤如下:
1.新建增量导入任务。在新建作业的任务区域,或新建任务界面,选择任务类型为“增量导入数据”,如下图所示:

增量导入数据的方式分为“普通增量”和“动态增量更新”两种,默认为“普通增量”。“普通增量”是将数据集中的数据全量或追加导入到数据集市中;“动态增量更新”既能按配置时间更新数据集市中的历史数据,又能将数据集中新增的数据导入到数据集市中。
2.数据集,选择要导入到数据集市中的数据集,必填项。点击“刷新数据集”可以同步数据集列表。当增量导入数据的方式为“普通增量”时,用户可以选择数据集下拉列表中的所有数据集;当增量导入数据的方式为“动态增量更新”时,用户只能选择可以下推到数据库中执行的数据集。

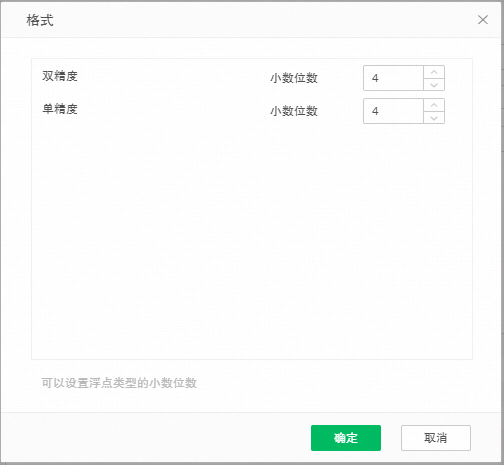
3. 8.5版本中,对于高精度进行了进一步的优化,使得在数据量较大时进行累计运算不会出现精度偏差,并且加入了集市存储数值型数据支持精度灵活设定,点击数据集右侧的编辑格式按钮,显示数据集中存在的double,float类型的数据列,将存储精度设置在集市文件夹上,支持不同的集市文件夹可以有不同的保存精度,double,float类型的数据列默认值均为4,如下图所示。

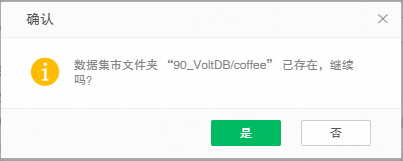
4. 输入进行增量导入数据生成的数据集市文件夹名称,也可以选择已生成的数据集市文件夹,必填项。当用户输入或选择了一个已经存在的数据集市文件夹,系统会根据追加与否,给出重名提示,防止用户在未知情况下覆盖了已经存在的数据集市文件夹,删除了已经存在的数据集市文件,造成数据丢失。如下图所示:
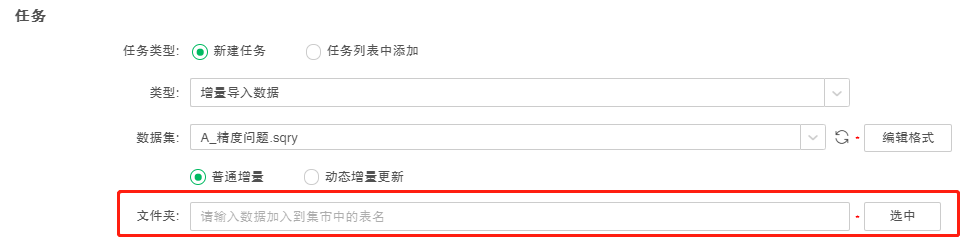
5. 设定执行增量导入数据生成的文件夹名称。
6. 设置普通增量的其他属性,如下图所示:
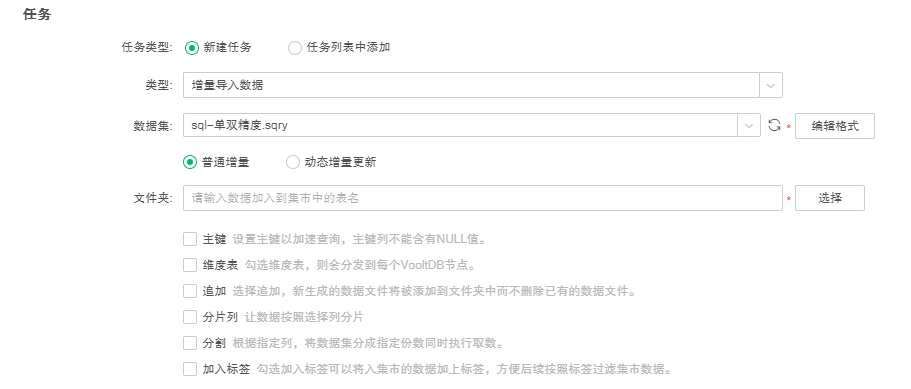
说明:Yonghong Desktop 只支持追加、分割、加入标签。
【主键】用户设置主键后可以加速查询的速度,且主键列不能包含NULL值。
【维度表】当用户勾选维度表时,对于分布式系统的星形数据(一个大表,若干个小表),可以将小表的数据复制到每个 VooltDB节点,执行 Map side join,用来提高数据的读取与处理速度。
【追加】当用户勾选追加时,新生成的数据文件会追加到文件夹中而不删除已有的数据文件。如用户创建一增量导入数据任务,即每天八点对某一数据集中的数据进行收集生成数据集市文件,第一天生成的文件名称为 test0,第二天生成的文件名称为 test1,以此类推。当用户不勾选追加时,倘若当前系统中已经存在该集市文件夹,则会创建新的数据集市文件夹来替代。如用户创建一增量导入数据任务,即每天八点对某一数据集中的数据进行收集生成数据集市文件,第一天生成的文件放入文件夹 folder0 中,第二天会生成新的数据集市文件夹 folder0 来覆盖已经存在的文件夹以及文件。
【分片列】勾选分片列后,会采用一致性哈希方式对数据列进行分片存储。两个数据集增量导入集市时,勾选分片列后选择列的数量、列的类型均匹配时:以分片列为链接条件,在组合时可以实现Mapsidejoin。
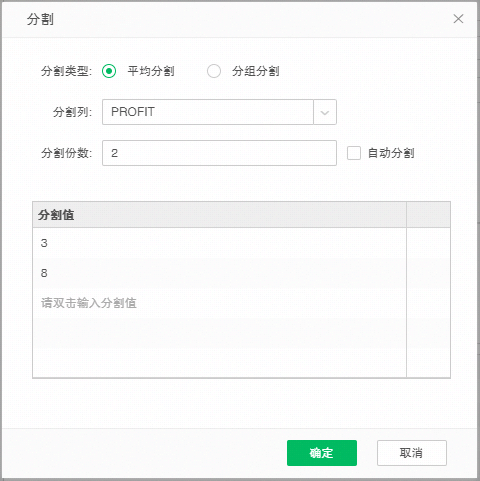
【分割】实现按列分割,并行导入集市的功能。当用户勾选分割时,会自动弹出分割对话框。分割类型分为平均分割和分组分割,平均分割只能选择一个分割列,默认为自动分割,分割份数由用户输入,默认值为4,如下图所示:
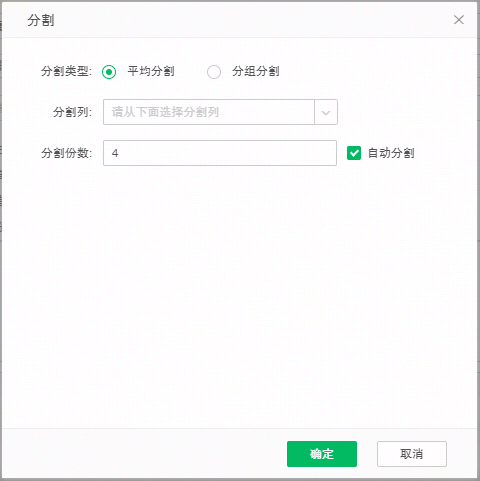
当取消自动分割时,用户可以手动输入分割值,手动分割是按照分割值将数据进行分组,再将分组好的数据存放zb中,zb数量为设置分割份数,需要注意的是在输入表格的分割值时,如果分割值的数目超过【n-1,n+1】范围时,点击确定时候弹框提示,提示信息如下: 自定义分割值只能设置在【n-1,n+1】范围时,请删除多余行数的分割值。
如下图所示,将Double列,按照 Double<3 ; 3≤ Double ≤8 ; Double>8 ; Double为空 ,进行分割,分割份数为2份:
分组分割不能填写分割份数,可以选择多个分割列。为了不影响导入数据的效率,建议分割列的列数不超过 10。分组分割可以自动生成 Meta 信息,以方便对数据集市中的数据进行过滤。其中,Meta 中的 key 为分割列对应的列名 ,Meta 中的 value 为分割列对应的值。当用户不勾选分割时,数据集市文件会按系统默认的设置进行生成。
【加入标签】8.6版本我们在增量导入数据新增了加入标签的属性,用来给入集市的数据集指定列打标签,并同时解决了当数据集SQL加载较慢时,使用分组分割的方式打meta会使job运行时间过长的问题。
在8.6版本之前,我们只能通过分组分割的方式对于入集市的数据集打标签,但是由于分割实现机制的问题,导致了当数据集本身SQL执行时间比较长时,分割会加大资源的消耗,延长job的运行时间。8.6后引入Setmeta属性来解决这个问题,使用Setmeta的限制条件与分组分割相同(需要满足数据总行数/数据分割列不同值>262144行),达成的效果与分组分割一致。但是当SQL运行时间较短时,Setmeta不会像分组分割一样起到加速job运行的效果,仅当SQL运行时间较长时,Setmeta的运行速度会小于使用分组分割打meta的运行速度。
7. 设置动态增量更新的属性,如下图所示:
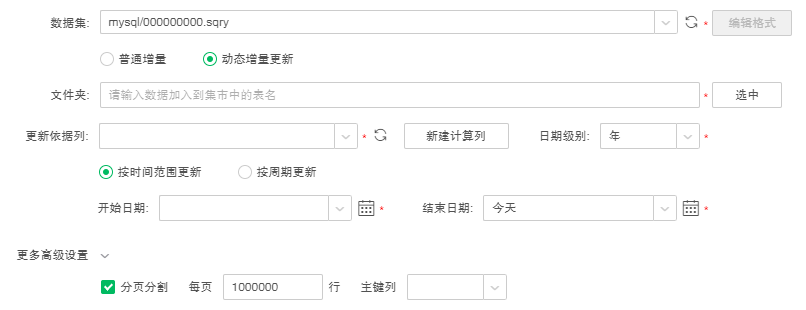
【更新依据列】更新依据列只能是日期类型或时间戳类型,必填项。用户可以选择数据集的原始列,也可以新建计算列,但只能新建一个计算列,新建完计算列后可以编辑计算列。点击“刷新更新依据列”可以同步数据集的列。
【日期级别】日期级别包括年、季度、月、周和天,默认为年,必填项。选择日期级别后,会根据选择的日期级别生成集市文件。
【按时间范围更新】设置要更新集市数据的开始日期和结束日期,必填项。开始日期和结束日期可以选择今天、昨天、本周、上周、本月、上月、本季度、上季度、本年和去年这些内置参数,也可以选择具体时间。
【按周期更新】设置要更新集市数据的一段时间,默认为近3年到今天,必填项。
【更多高级设置】展开更多高级设置后,用户可以使用分页分割,默认不勾选。当数据集所使用的数据库支持分页,且数据集的数据量很大,需要快速分割入集市时,可以使用分页分割。勾选分页分割后,可以按照主键列降序排序后每页默认按1000000行分页。主键列默认为更新依据列,用户可以根据需要自行设置每页的行数和主键列。支持分页的数据库包括:MySQL、Oracle、DB2、SqlServer、Gbase8a、Kylin、SysbaseIQ、Hana。
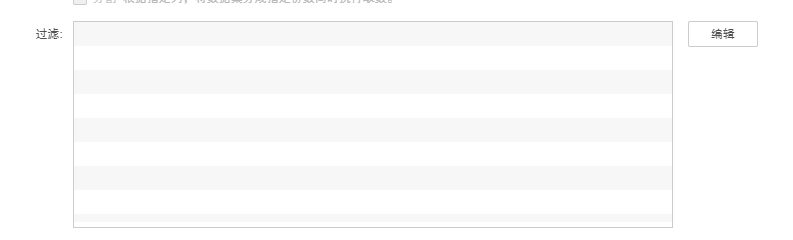
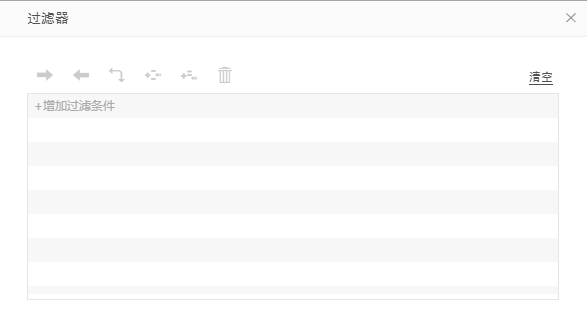
8. 设置过滤条件。点击【编辑】按钮,弹出过滤对话框,点击点击添加过滤条件,选择需要设置过滤的列,如下图所示。系统只会对满足过滤条件的数据执行增量导入动作。
9. 用户可通过脚本来实现对增量导入数据的控制。通过脚本用户可设定数据集市文件夹的名称、传递参数、是否追加、以及设定数据集市文件的属性。在执行此任务时,脚本的优先级最高。
脚本语句 |
说明 |
举例 |
|---|---|---|
folder |
创建一个数据集市文件夹 |
folder="CloudTest"; |
append |
是否追加 |
append=true; |
setMeta |
给数据集市文件设定属性 |
setMeta("date",new Date(2012,9,19));//数据集市文件的 日期属性为2012,9,19,则在数据集市数据集中可通过过滤条件查看这个属性 |
param |
传递参数 |
param["market"]="East";//market是East的所有数据,参数market来自相应的数据集 |
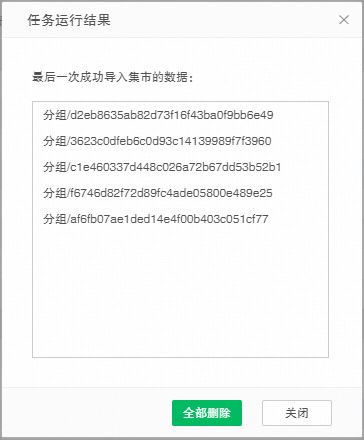
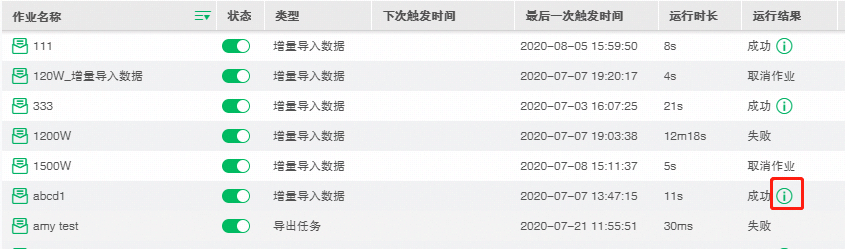
10.当作业类型为增量导入数据并且运行成功时 , 在当前作业界面和历史作业界面的结果" 成功 ” 后会出现可以触发导入到集市的数据文件对话框的图标。
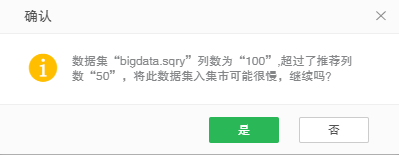
11.在当前页面中选择数据集时,数据集入集市的推荐列数为50,超过该值保存时将提示入集市可能很慢,如下图所示:
❖删除追加的增量数据
在当前作业状态页面中,允许用户删除最后一次成功导入到集市中的数据,而保留之前导入的数据。如果用户通过追加的方式,连续多次将数据导入到集市,其中第二次导入到集市中的数据有误,那么用户可以在历史作业状态页面找到对应的作业执行记录,打开任务运行结果对话框,删除此次导入到集市中的数据,而保留其他数据。