|
<< Click to Display Table of Contents >> Set Meta |
|
|
<< Click to Display Table of Contents >> Set Meta |
|
In schedule task, create a job which task type is Incremental Import Data to Data Mart. Choose one data set, and add label to the could file that is stored in the database by setMeta() method in the script, as shown in the script below.
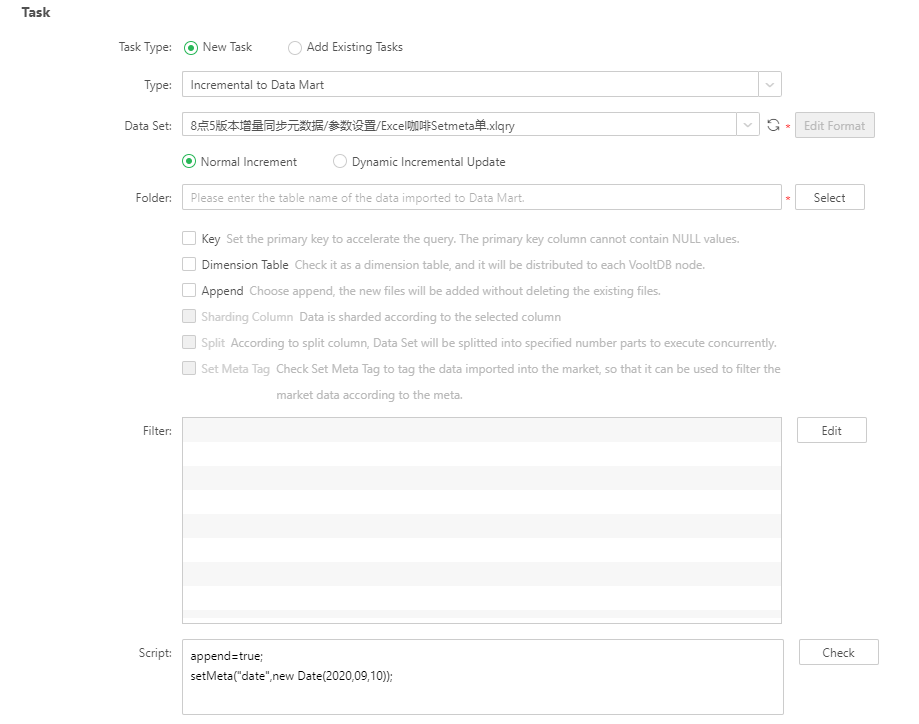
About the functions of dividing by column, and parallel importing in mart, when the user chooses the “Split” option, the dialog “Split” will be popped up automatically. The division type includes “Split by Average” and “Split by Group”. “Split by Average” can only select one column to split. And the “Split Number ” should be integer. For example: 3. “Split by Group” divides through Group By, do not fill the “Split Number”, and multiple split columns can be chosen. In order not to impact the efficiency of importing data, we suggest that the split number is no more than 10. Choosing “Split by Group”, the data entered in data mart will be added. Meta automatically according to the division data, to facilitate the filter of cloud file in cloud folder. The key of Meta is the corresponding name of split column, and the value of Meta is the corresponding value of split column. When the user does not check “Split”, the cloud file will be generated according to the default setting of system.
➢Attention: while choosing the “Split by Group”, the data entering into the mart will be added Meta automatically according to the division data, but the following three conditions must be met:
A.The total rows of data > dc.unit.rows (The default value is 262144)
B.Number of groupings <= dc.split.range (The default value is 1000)
C.(Total rows of data/number of groupings) > dc.unit.rows (The default number is 262144)