|
<< Click to Display Table of Contents >> K-Means聚类 |
|
|
<< Click to Display Table of Contents >> K-Means聚类 |
|
该算子可用于对无标签的数据进行分类,属于无监督学习。主要解决无监督学习,聚类预测问题。
用法:
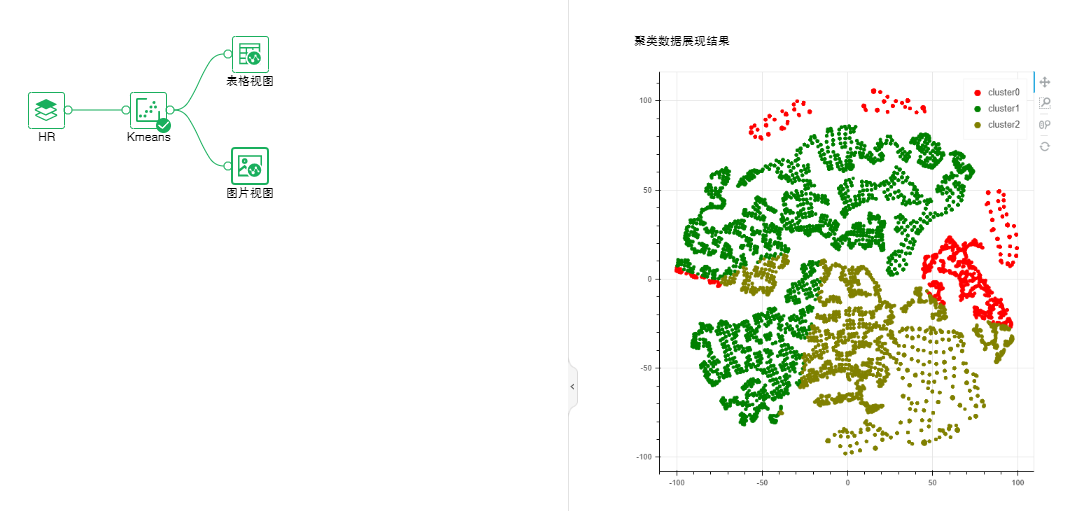
量纲不一致情况下,输入数据需要标准化处理。设置Kmeans后,可通过连接表格视图来查看输出聚类类别、聚类类别个数、聚类中心和模型聚类结果评价指标(Calinski-Harabasz分数、Davies-Boulding指数;连接图片视图来查看聚类数据展现结果。
注意事项:
聚类模型输入数据需要筛选变量的共线性问题,可以使用节点【相关性分析】操作。
聚类模型输入数据需要标准化处理,可以使用节点【标准化】操作。
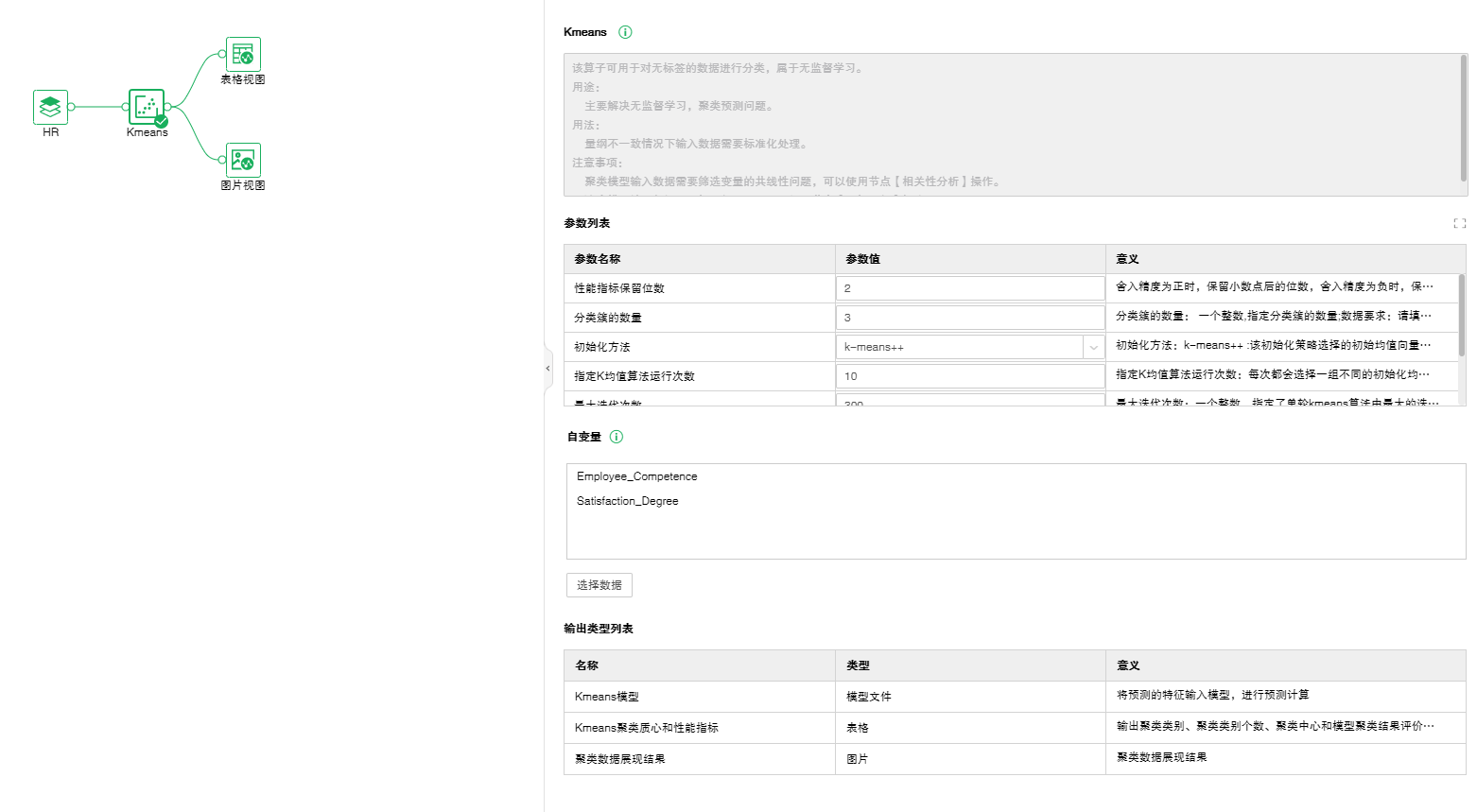
❖K-Means聚类节点的配置方法
将K-Means聚类节点添加到实验后,可通过右侧的“配置项目”页面,对K-Means聚类节点进行设置。
【性能指标保留位数】舍入精度为正时,保留小数点后的位数,舍入精度为负时,保留小数点前的位数。
【分类簇的数量】指定分类簇的数量;数据要求:请填写整数类型数字,数据范围[1,)。
【初始化方法】k-means++ :该初始化策略选择的初始均值向量相互之间都距离较远,它的效果较好; random : 从数据集中随机选择n个样本作为初始均值向量或者提供一个数组,数组的形状为 (n_clusters,n_features),该数组作为初始均值向量。
【指定K均值算法运行次数】每次都会选择一组不同的初始化均值向量,最终算法会选择最佳的分类簇来作为最终的结果。 数据要求:请填输入大于1的整数,数据范围[1,)。
【最大迭代次数】一个整数,指定了单轮K-Means聚类算法中最大的迭代次数。算法总的迭代次数为:max_iter*n_init。数据要求:请输入大于0的整数,数据范围[1,)。
【随机种子】数据要求:请填写大于1的整数,数据范围[1,]。
【预先计算距离】该参数指定是否提前计算好样本之间的距离。‘True’ :提前计算。‘False’ :不提前计算。
【算法】auto:自动选择算法。
对于稀疏数据,使用full。full:使用经典的EM风格的算法。
对于密集数据,使用elkan。elkan:使用‘elkan’变种算法,它通过使用三角不等式来优化算法,但是不支持稀疏数据。
【自变量】模型的特征字段,可以为多个。
K-Means聚类节点右键菜单

❖K-Means聚类节点运行
运行节点,将数据传递给DM-Engine进行计算,得到输出结果。
❖K-Means聚类节点重置
已经运行过的节点进行重置,删除返回的结果,节点状态更改为未运行。
❖K-Means聚类节点重命名
在K-Means聚类节点的右键菜单中,选择“重命名”,可以对节点进行重命名。
❖刷新K-Means聚类节点
在K-Means聚类节点的右键菜单中,选择“刷新”,可以更新同步数据或者参数信息。
❖保存为组合节点
在K-Means聚类节点的右键菜单中,选择“保存为组合节点”,可以将选中的节点保存为组合节点以实现复用节点,保存的节点的参数与原节点一致。
❖剪切K-Means聚类节点
在K-Means聚类节点的右键菜单中,选择“剪切”,在目标位置右键选择“粘贴”,可以实现节点的剪切粘贴。
❖复制K-Means聚类节点
在K-Means聚类节点的右键菜单中,选择“复制”,在目标位置右键选择“粘贴”,可以实现节点的复制粘贴。
❖删除K-Means聚类节点
在K-Means聚类节点的右键菜单中,选择“删除”或者点击键盘 delete 键进行删除,能够删除节点以及节点的输入、输出连线。