|
<< Click to Display Table of Contents >> 通过命令行工具设置调度任务 |
|
|
<< Click to Display Table of Contents >> 通过命令行工具设置调度任务 |
|
命令行工具又被称为 CMD 命令,是 Yonghong Z-Suite 一个独立的模块,可以被热衷于用命令来进行操作的用户所使用。命令行工具在使用的时候无需启动产品。它与调度任务中某些任务的功能是等价的。主要支持三条命令:
•expcsv:导出数据集数据到 CSV 文件,等价于调度任务中的导出到 CSV 文件。
•expdb:导出数据集数据到数据库,等价于调度任务中的导出到数据库。 说明:Yonghong X-Suite、Y-Reporting、Desktop不支持导出到数据库。
•import:导入数据集数据到 DATA MART MPP 数据集市,等价于调度任务中的增量导入数据。
❖启动命令行工具
运行安装目录 command 下的 startCMD.bat(Linux 系统下启动 startCMD.sh) 命令启动命令行工具。
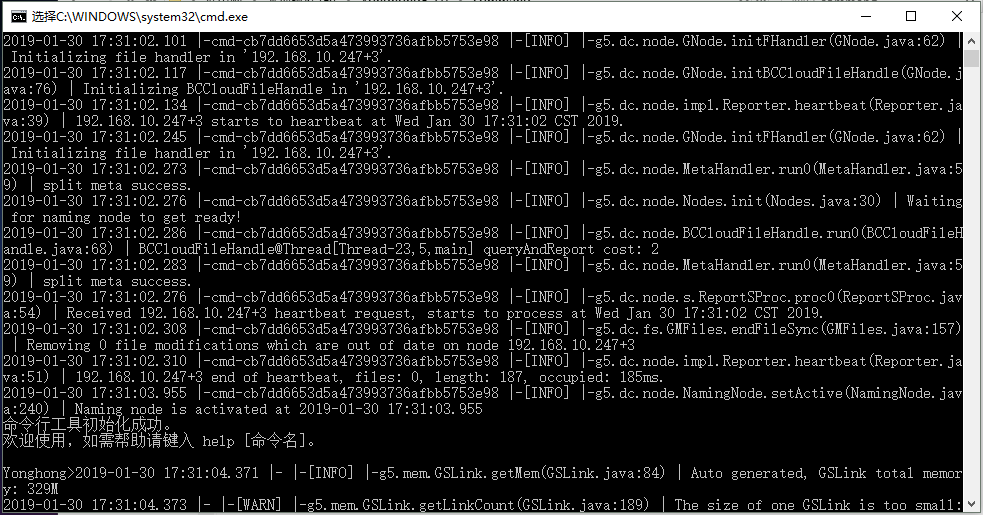
命令行工具启动后,键入 help 命令,出现命令行工具支持的 4 条命令介绍,如图所示:

•expcsv:以 csv 格式将数据集执行结果导出到本地文件系统。
•expdb:将数据集执行结果导出到指定的数据库中。
•import:将数据集执行结果导入到集市中。
•quit:退出命令行工具。
❖导出到CSV文件
用户在使用 expcsv 时,可查看参数介绍,只需输入 help expcsv,如图所示:

•-q:必须指定的选项。指定数据集文件,数据集文件必须是系统支持类型。
•-d:必须指定的选项。文件保存路径,确保具备写入权限。
•-p:可选选项。提供数据集所需要的参数,例如:" 参数 1= 值 1; 参数 2= 值 2"。
•-fl:可选选项。指定添加给数据集的过滤条件,例如:"ID > 20 and ID < 100"。
•-r:可选选项。导出的数据记录数,默认为全部导出。
在 bi.properties 加入属性 cmd.csv.file.row (如 cmd.csv.file.row=500)后,重启命令行工具,来控制所有导出 csv 文件的最大数据行数。
➢例如:Yonghong>expcsv -q 咖啡销售统计 1.sqry -d d:\ -p“market=East;type=Decaf”-fl ID>59 -r5
当在 bi.properties 中加入了 cmd.csv.file.row=500, 先退出 startCMD.bat,再进行重新启动,才可控制导出的 csv 行数在 500 以内。
❖导出到数据库
用户在使用 expdb,可查看参数介绍,只需输入 help expdb,如图所示:
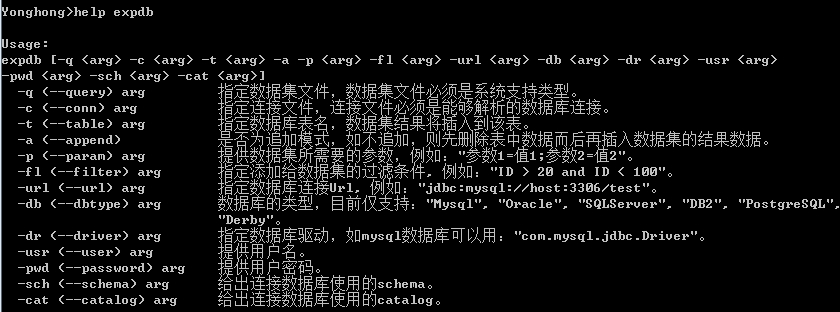
•-q:必须指定的选项。指定数据集文件,数据集文件必须是系统支持类型。
•-c:必须指定的选项。指定连接文件,连接文件必须是能够解析的数据库连接。
•-t:必须指定的选项。指定数据库的表名,数据集结果将插入到该表。
•-a:可选选项。是否为追加模式,如不追加,则删除表中的数据而后再插入数据集的结果数据。
•-p:可选选项。提供数据集所需要的参数,例如:“ 参数 1= 值 1 ;参数 2= 值 2”。
•-fl:可选选项。指定添加给数据集的过滤条件。例如:“ID>20 and ID<100”。
•-url:必须指定的选项。指定数据库连接 Url, 例如:”jdbc:mysql://host:3306/test”。
•-db:必须指定的选项。数据库的类型,目前仅支持四种数据库 :mysql、oracle、sqlserver 和db2。
•-dr:必须指定的选项。指定数据库驱动,例如:org.gjt.mm.mysql.Driver。
•-usr:必须指定的选项。提供用户名。
•-pwd:必须指定的选项。提供用户密码。
•-sch:可选选项。给出连接数据库使用的 schema。
•-cat:可选选项。给出连接数据库使用的 catalog。
导出数据库时,数据源的选择方式有两种:
•通过参数 -c 设置数据源。
•通过参数 -url,-db,-dr,-usr,-pwd,-sch,-cat 设置数据源。
➢例如一:Yonghong>expdb -q t1.sqry -t“t1”-c mysql.conn -a -p“id=11;id=12”-fl“id=12”
➢例如二:Yonghong>expdb -q t1.sqry -db mysql -usr root -pwd yonghong4 -url “jdbc:mysql:// 192.168.1.104:3306/testdb”-p“Product_Type=Coffee”-fl“ID<2000 and ID>50”-t “t1”-dr“com.mysql.jdbc.Driver”
❖导入数据导数据集市
用户在使用 import,可查看参数介绍,只需输入 help import,如图所示:

•-q:必须指定的选项。指定数据集文件,数据集文件必须是系统支持类型。
•-p:可选选项。提供数据集所需要的参数,例如:“ 参数 1= 值 1 ;参数 2= 值 2”。
•-d:必须指定的选项。指定文件夹名称,数据集结果将保存在集市中以该名称命名的文件夹中。
•-f:必须指定的选项。指定文件名称,数据集结果将保存在以该名字命名的文件中,如:file_name.zb。
•-a:可选选项。是否为追加模式,如不追加,则删除表中的数据后再插入数据集的结果数据。
•-fl:可选选项。指定添加给数据集的过滤条件。例如:“ID>20 and ID<100”。
•-sc:可选选项。指定用来将数据集进行平均分割的列名称。可选分割列为数字类型、日期类型和时间类型。这个数据集会依据指定列分割成指定数目的数据集,同时执行这些数据集以提高数据导入 MPP 集市的效率。
•-sn:可选选项。声明将数据集进行分割的数目。
➢例如:Yonghong>import -q t1.sqry -d“cloud1”-f“all”-sc ID -sn 2
该命令意为:将数据集 t1 的数据导入数据集市,以 ID 列进行平均分割,数据集分割的数目为 2,集市中文件夹的名称为 cloud1,文件名称为 all.zb。
❖退出
用户在使用 quit,可查看参数介绍,只需输入 help quit,如图所示:

此命令直接退出命令行工具。