|
<< Click to Display Table of Contents >> K-Means聚类 |
|
|
<< Click to Display Table of Contents >> K-Means聚类 |
|
❖K-Means聚类
K-Means聚类要指定聚类的分类个数N,随机取N个样本作为初始类的中心,计算各样本与类中心的距离并进行归类,所有样本划分完成后重新计算类中心,重复这个过程直到类中心不再变化。在R中使用kmeans函数进行K-means聚类。
kmeans(data,centers=3,nstart=10),其中centers 参数用来设置分类个数,nstart 参数用来设置取随机初始中心的次数,即运行kmeans 方法的次数,我们在用kmeans 函数时,默认取10。
【聚类维度】聚类的样本集。从左侧的可配置列中选择需要作为聚类维度的字段直接拖入到聚类维度框中。
【设置K 值】分类的个数。可以手动输入分类个数,也可以输入最大K 值,系统根据轮廓系数计算出最佳的K 值。
【输出值】【聚类标签】每个样本所属的类别。
【输出值】【主成分】对聚类的维度做主成分分析,取最重要的两个成分。
•举例说明
假设去掉类别列,根据四种属性对三种花进行分类。
在图表上创建K-means 聚类分析,如图:
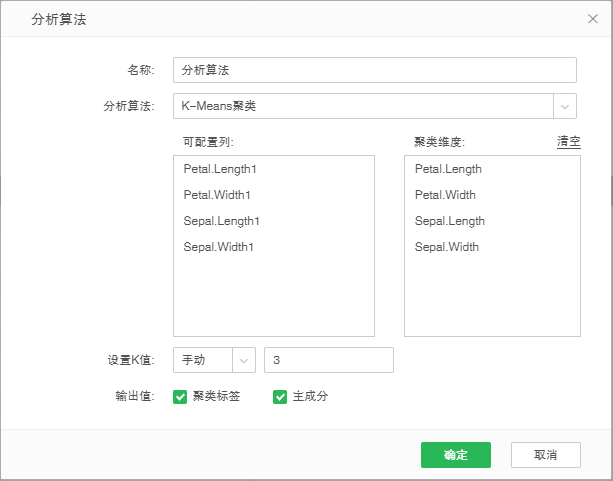
聚类结果如图: