|
<< Click to Display Table of Contents >> Python脚本 |
|
|
<< Click to Display Table of Contents >> Python脚本 |
|
Python脚本节点可以连接数据节点,输入脚本用于建模,也可以连接Python脚本,进行验证。
拖拽一个数据集连接一个Python脚本节点,选中Python脚本节点设置及展示区有两个页面:配置项目、属性。
❖配置Python脚本
•8.5-9.0的接口
Python脚本内置输入、输出变量和系统函数。
输入变量
_input_table_ :pandas.DataFrame类型,为前驱数据集节点的输出数据;
_input_model_ :前驱Python脚本节点向本节点输入的数据,可以使模型对象、list、dict等可序列化任意类型;
输出变量
_output_table_ :pandas.DataFrame类型或dict类型,用于输出数据到表格;
_output_model_ :本节点向所有直接后继Python脚本节点输出的数据,可以是模型对象、list、dict等可序列化任意类型;
_pmml_ :为训练模型的PMML文本内容,作为该模型节点的输出值,与函数to_pmml()配合使用;
_plot_ :matplotlib.pyplot类型,用于输出图片;
系统函数
to_pmml(model,features,target):用于导出训练模型的PMML文本文件,其中model为训练出的模型,features为含有训练集所有特征(自变量)的list,这些特征顺序必须与训练模型时的特征顺序保持一致,target为含有训练集标签字段(因变量)的字符串,该系统函数返回的PMML文本可以赋值给_pmml_,以便传递给后继节点;
❖Python的属性配置
V9.3版本新增属性配置可以编辑节点名称、注释内容。详情参考添加数据中的属性配置。
•9.1新接口
Python脚本节点的变更:
(1)8.5-9.0的接口仍然兼容,仅能使老版本创建的实验导入到9.1时仍然可以正常运行,但由于不能支持多数据集输入,所以不要在9.1版本新创建的实验中使用9.0及以前的接口;
(2)新API从产品9.1搭配DM-Engine_v1.4使用,脚本可使用python SDK v0.2进行离线编写;
yonghong.script.port 编写自定义python脚本的子工具包,包含两个工具类: EntryPoint:当前脚本节点的输入输出端口 input:本节点的数据输入,访问某个前置节点的某种数据可以这样:entry.input['数据集节点1'][ResourceType.DATAFRAME] 表示 获取“数据集节点1”的输出数据集;
output:本节点的数据输出; dataset: 待输出的数据集 model: 待输出的模型 pmml: 待输出的pmml images: 待输出的png图片数据,使用方法 images.put_image_from_plot("图片名字1",plot)
ResourceType: 输入输出数据的枚举类型,DATAFRAME表示数据集,MODEL表示模型
|
❖新API使用案例
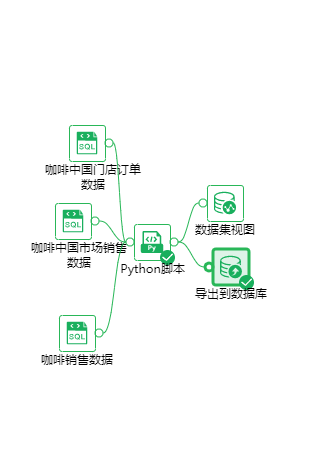
案例1-- 运用python脚本对咖啡中国门店订单数据、咖啡中国市场销售数据、咖啡销售数据这三个数据集做某种业务逻辑处理,处理完成后向外输出一个数据集视图、将处理后的数据导出到数据库。 其中“数据集视图”节点用于查看Python脚本是否符合预期,“导出到数据库”节点用于将处理结果写入数据库表。
操作步骤 输入节点:咖啡中国门店订单数据、咖啡中国市场销售数据、咖啡销售数据 1.在画布区域拖入系统自带的数据集:咖啡中国门店订单数据、咖啡中国市场销售数据、咖啡销售数据。
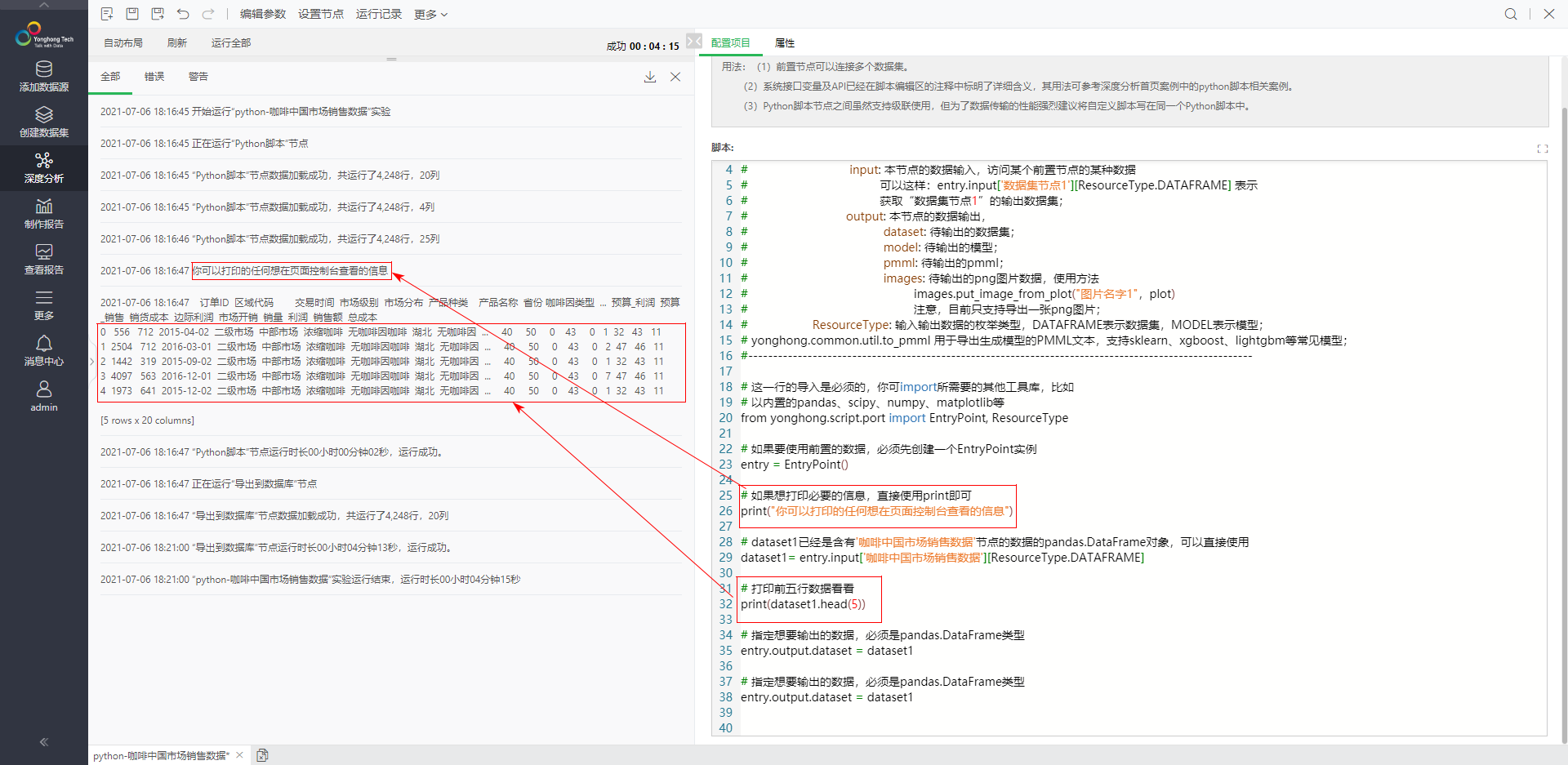
中间节点:Python脚本 2.单击“操作”,从数据集Tab切换到操作Tab。 3.将“脚本”文件夹下的“Python脚本”拖入画布区域,并与三个数据集节点相连。 4.选中“Python脚本”,在配置项目的脚本区域,输入Python脚本相关的设置。 # 这一行的导入是必须的,你可import所需要的其他工具库,比如 # 以内置的pandas、scipy、numpy、matplotlib等 from yonghong.script.port import EntryPoint, ResourceType
# 如果要使用前置的数据,必须先创建一个EntryPoint实例 entry = EntryPoint()
# 如果想打印必要的信息,直接使用print即可 print("你可以打印的任何想在页面控制台查看的信息")
# dataset1已经是含有'中国市场销售数据'节点的数据的pandas.DataFrame对象,可以直接使用 dataset1= entry.input['中国市场销售数据'][ResourceType.DATAFRAME]
# 打印前五行数据看看 print(dataset1.head(5))
#指定想要输出的数据,必须是pandas.DataFrame类型 entry.output.dataset = dataset1
➢说明: 蓝色信息为输入节点中的数据集名称,您可以替换为输入节点中另外两个数据集:咖啡中国门店订单数据、咖啡销售数据。
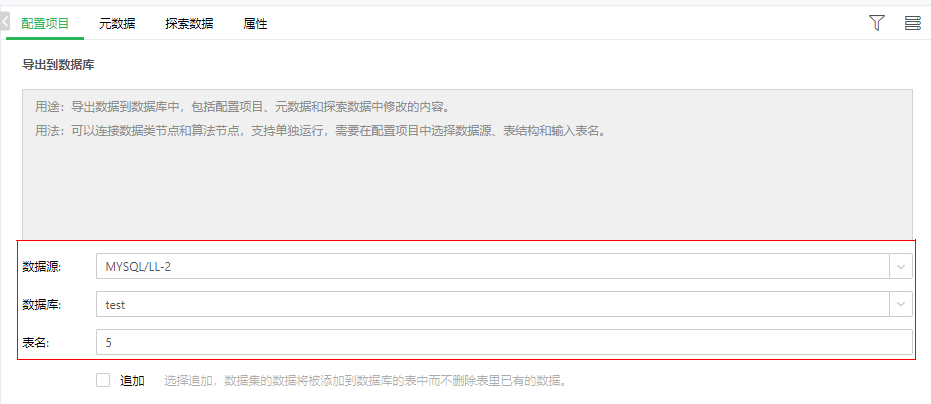
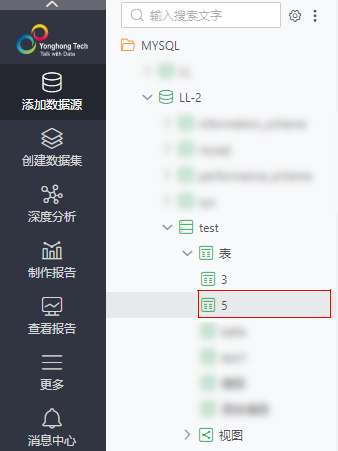
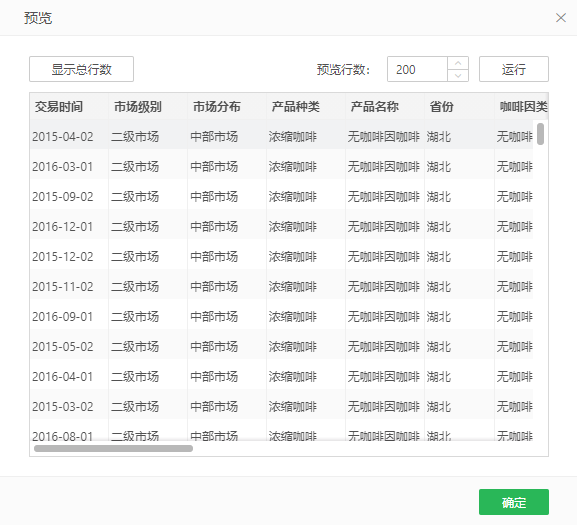
输出节点:数据集视图、导出到数据库 数据集视图 5.在“视图”文件下拖入“数据集视图”节点,并与“Python脚本”节点相连。 导出到数据库 6.在“导出”文件下拖入“导出到数据库”节点,并与“Python脚本”节点相连。 7.选中“导出到数据库”节点,在配置项目下,选择数据源、数据库和输入表名(如MYSQL/LL-2、test、5)。
8.单击顶部工具栏左上角 9.单击画布区域的“运行实验”。 实验运行后结果如下图所示。 日志信息:
数据集视图:
导出到数据库:
|
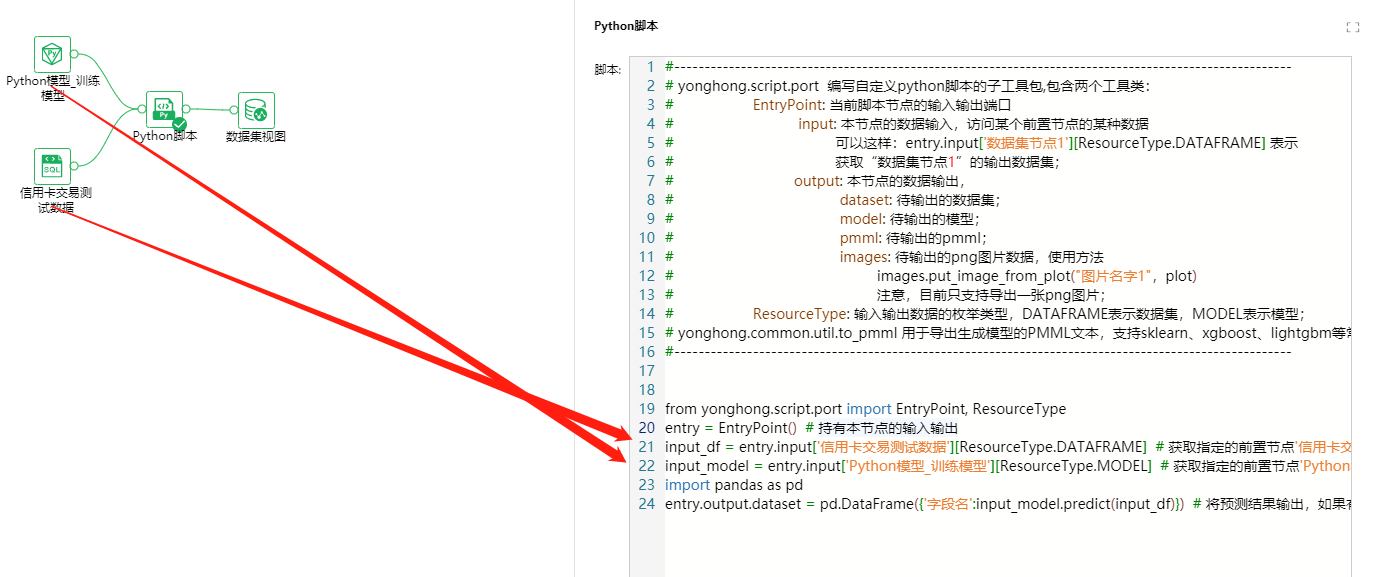
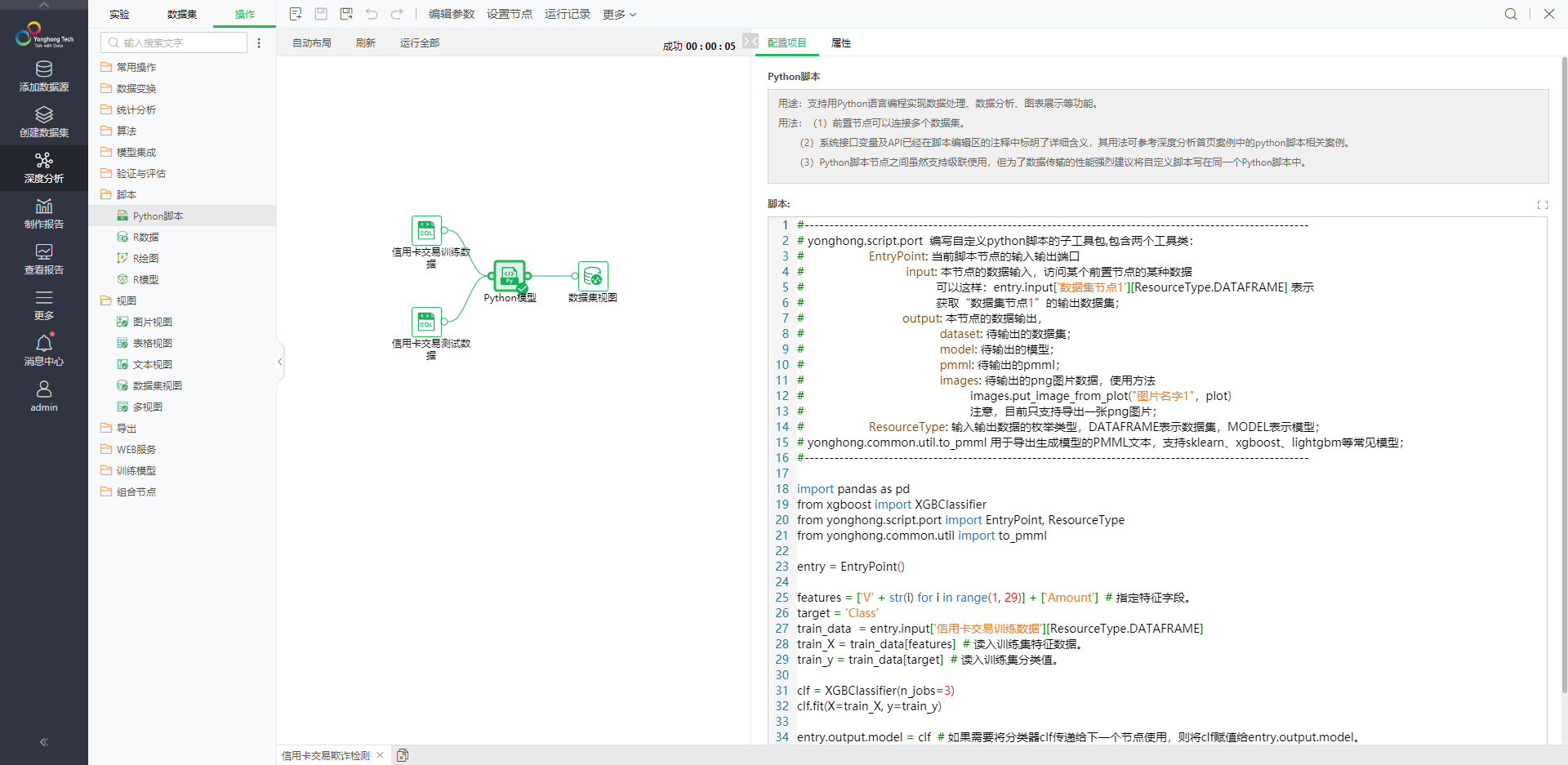
案例2--前置节点为一个数据集节点、一个训练模型节点(Python脚本导出的训练模型);节点输出为一个数据集
# EntryPoint:当前脚本节点的输入输出端口 # ResourceType:输入输出数据的枚举类型,DATAFRAME表示数据集,MODEL表示模型 from yonghong.script.port import EntryPoint, ResourceType entry = EntryPoint() # 持有本节点的输入输出 input_df = entry.input['样例数据集'][ResourceType.DATAFRAME] # 获取指定的前置节点'样例数据集'的输出数据 input_model = entry.input['决策树模型'][ResourceType.MODEL] # 获取指定的前置节点‘决策树模型’输出的训练模型 import pandas as pd entry.output.dataset = pd.DataFrame({'字段名':input_model.predict(input_df)}) # 将预测结果输出,如果有后置节点将被后置节点接收
|
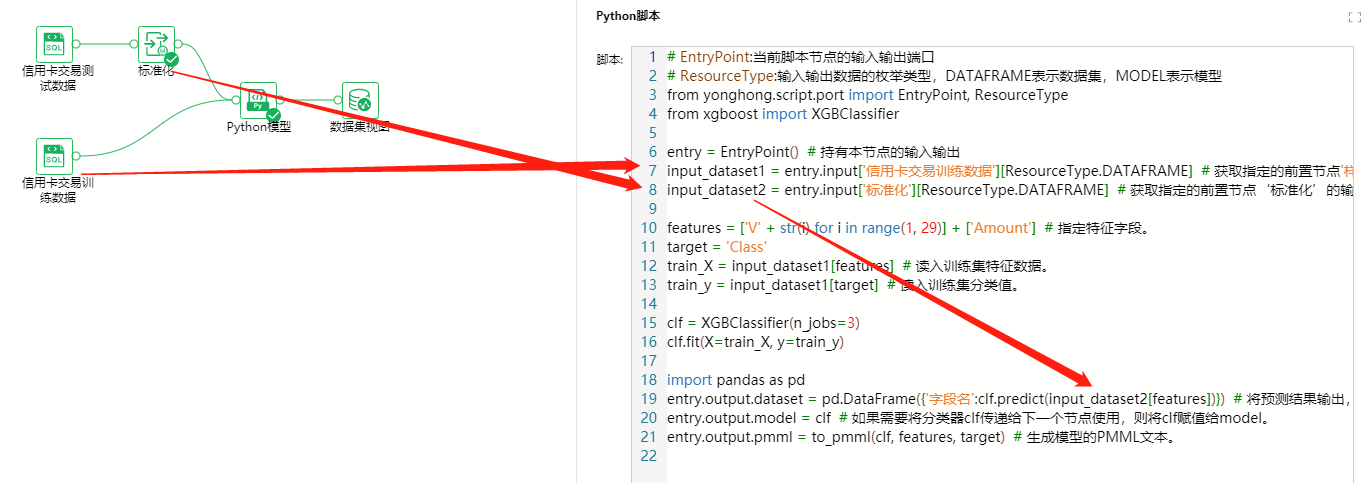
案例3--前置节点为一个数据集节点、一个插件节点(有输出数据集);节点输出为一个训练模型
# EntryPoint:当前脚本节点的输入输出端口 # ResourceType:输入输出数据的枚举类型,DATAFRAME表示数据集,MODEL表示模型 from yonghong.script.port import EntryPoint, ResourceType from xgboost import XGBClassifier
entry = EntryPoint() # 持有本节点的输入输出 input_dataset1 = entry.input['样例数据集'][ResourceType.DATAFRAME] # 获取指定的前置节点'样例数据集'的输出数据 input_dataset2 = entry.input['标准化'][ResourceType.DATAFRAME] # 获取指定的前置节点‘标准化’的输出数据集
features = ['V' + str(i) for i in range(1, 29)] + ['Amount'] # 指定特征字段。 target = 'Class' train_X = input_dataset1[features] # 读入训练集特征数据。 train_y = input_dataset1[target] # 读入训练集分类值。
clf = XGBClassifier(n_jobs=3) clf.fit(X=train_X, y=train_y)
import pandas as pd entry.output.dataset = pd.DataFrame({'字段名':clf.predict(input_dataset2[features])}) # 将预测结果输出,如果有后置节点将被后置节点接收 entry.output.model = clf # 如果需要将分类器clf传递给下一个节点使用,则将clf赋值给model。 entry.output.pmml = to_pmml(clf, features, target) # 生成模型的PMML文本。
|
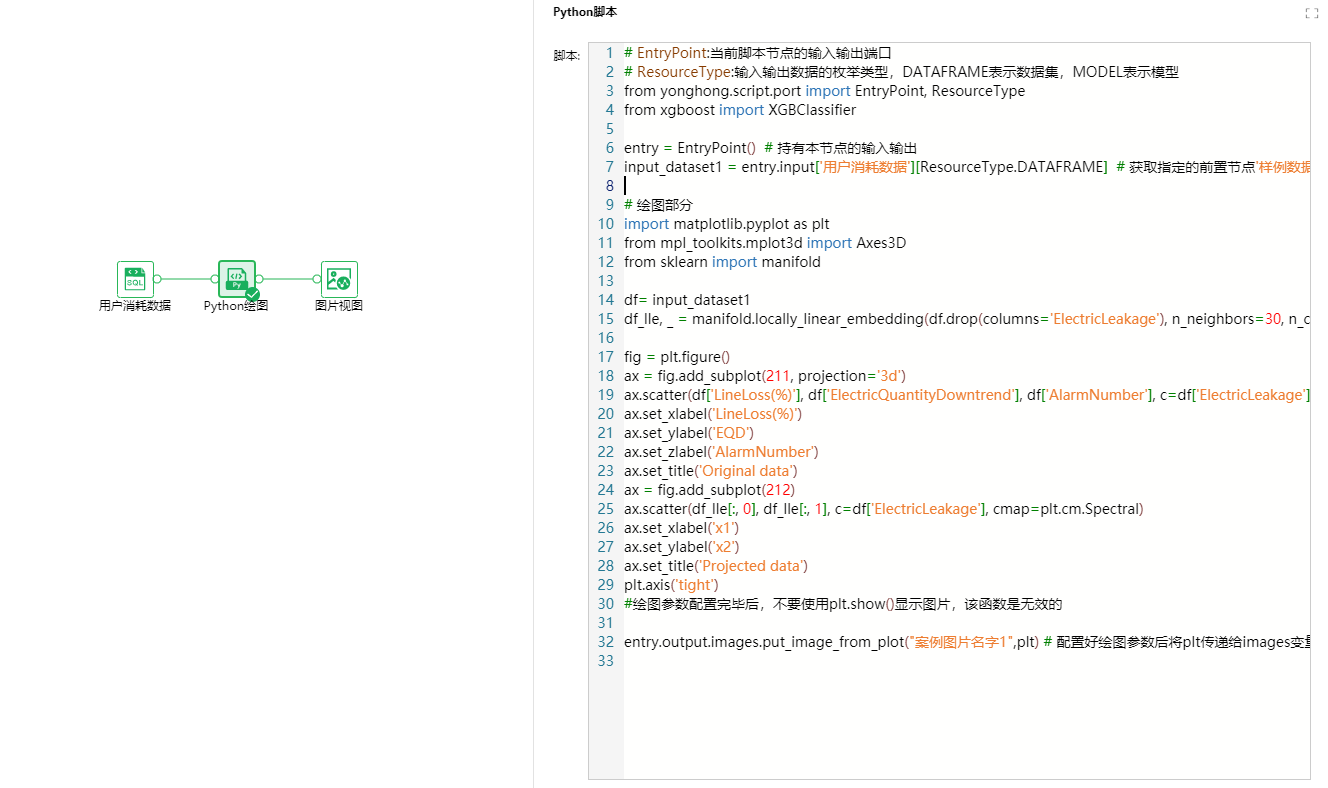
案例4--前置节点为一个数据集节点、一个插件节点(有输出数据集);节点输出为一个png图片
# EntryPoint:当前脚本节点的输入输出端口 # ResourceType:输入输出数据的枚举类型,DATAFRAME表示数据集,MODEL表示模型 from yonghong.script.port import EntryPoint, ResourceType from xgboost import XGBClassifier
entry = EntryPoint() # 持有本节点的输入输出 input_dataset1 = entry.input['样例数据集'][ResourceType.DATAFRAME] # 获取指定的前置节点'样例数据集'的输出数据 input_dataset2 = entry.input['标准化'][ResourceType.DATAFRAME] # 获取指定的前置节点‘标准化’的输出数据集
# 绘图部分 import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D from sklearn import manifold
df= input_dataset1 df_lle, _ = manifold.locally_linear_embedding(df.drop(columns='ElectricLeakage'), n_neighbors=30, n_components=2) # 对数据进行降维操作
fig = plt.figure() ax = fig.add_subplot(211, projection='3d') ax.scatter(df['LineLoss(%)'], df['ElectricQuantityDowntrend'], df['AlarmNumber'], c=df['ElectricLeakage'], cmap=plt.cm.Spectral) ax.set_xlabel('LineLoss(%)') ax.set_ylabel('EQD') ax.set_zlabel('AlarmNumber') ax.set_title('Original data') ax = fig.add_subplot(212) ax.scatter(df_lle[:, 0], df_lle[:, 1], c=df['ElectricLeakage'], cmap=plt.cm.Spectral) ax.set_xlabel('x1') ax.set_ylabel('x2') ax.set_title('Projected data') plt.axis('tight') #绘图参数配置完毕后,不要使用plt.show()显示图片,该函数是无效的
entry.output.images.put_image_from_plot("案例图片名字1",plt) # 配置好绘图参数后将plt传递给images变量,图表就可以绘制到页面中
|
❖Python脚本运行
在Python脚本节点的右键菜单中,选择“运行”,可以运行该节点及前置节点。
❖Python脚本节点重命名
在Python脚本节点的右键菜单中,选择“重命名”,可以对节点进行重命名。
❖刷新Python脚本节点
在Python脚本节点的右键菜单中,选择“刷新”,可以更新同步数据或者参数信息。
❖保存为组合节点
在Python脚本节点的右键菜单中,选择“保存为组合节点”,可以将选中的节点保存为组合节点以实现复用节点,保存的节点的脚本与原节点一致。
❖复制/剪切/粘贴/删除脚本节点
脚本节点的右键菜单支持复制、剪切、粘贴、删除的操作。
【复制】选中脚本节点可以复制。
【剪切】选中脚本节点节点可以剪切。
【粘贴】选择复制后,画布空白处右键可以粘贴,把脚本节点复制一份。
【删除】点击节点右键菜单点击删除,或者点击键盘 delete 键进行删除,能够删除节点以及节点的输入、输出连线。