数据抽取是指将数据集的数据(查询的是数据库中的数据或文本文件的数据)抽取到VooltDB节点。再次查询数据时,数据计算将在VooltDB节点发生。
支持数据抽取的数据集有:SQL数据集、Excel数据集、组合数据集、自服务数据集、Mongo数据集、定制数据集、RESTful数据集。
不支持数据抽取的数据集有:内嵌数据集、流式数据集、数据集市数据集、多维数据集、Neo4j数据集。
1. 数据抽取的方式
1.1 数据集“抽取数据”
抽取数据成功后,在调度任务中运行此数据集或执行基于此数据集的报告,将会在数据集市中计算。
在数据集上,点击“抽取数据”。
弹出抽取数据对话框:
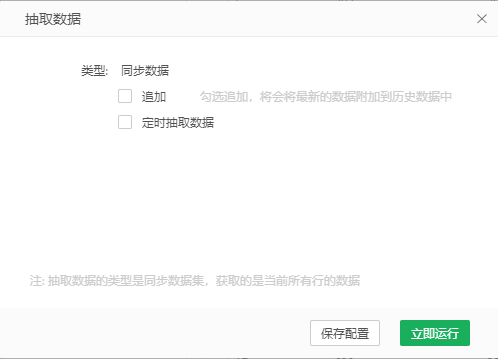
配置项说明:
【追加】默认不勾选,勾选会将更新的数据追加到历史数据中,不勾选将全部数据入集市。
【更新依据列】默认不显示,勾选追加后才显示,更新依据列中只可以选择数值列和日期列。追加时,首先获取集市中依据列字段的最大值,然后查询出数据集中依据列大于此最大值的数据,将这些数据追加到集市中。
【保存配置】用户设置抽取数据对话框中的配置信息后,点击保存配置可以在数据集上保存相关配置。立即运行和定时运行之后,配置信息也会保存。
【立即运行】用户点击立即运行后会开始进行一次性抽取数据,此时,抽取数据对话框消失,弹出抽取数据过程对话框,如下图所示。
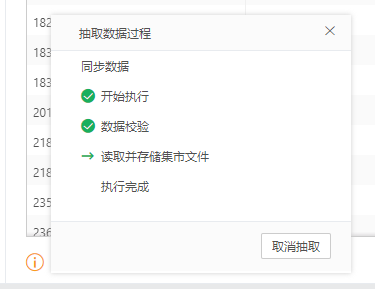
抽取数据过程对话框中会显示数据抽取的步骤,包括:开始执行、数据校验、读取并存储集市文件和执行完成,方便用户知道目前数据抽取的进度。已执行完成的步骤前显示![]() ,正在执行的步骤前显示
,正在执行的步骤前显示![]() ,待执行的步骤前不显示图标。当数据集正在抽取中时,抽取数据前显示橙色图标,抽取数据按钮为置灰状态。点击“取消抽取”,可以停止抽取数据。用户点击右上角的“×”可以关闭对话框,后台继续执行抽数。
,待执行的步骤前不显示图标。当数据集正在抽取中时,抽取数据前显示橙色图标,抽取数据按钮为置灰状态。点击“取消抽取”,可以停止抽取数据。用户点击右上角的“×”可以关闭对话框,后台继续执行抽数。
【定时抽取数据】默认不勾选。勾选此选项来定时抽取数据。界面如下图:
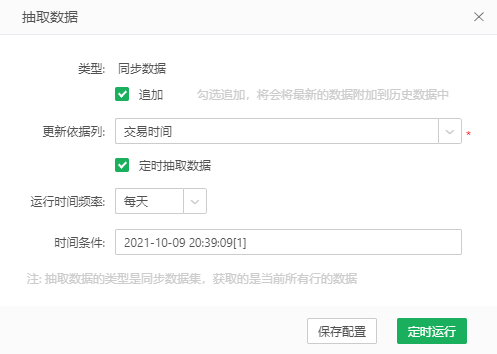
【运行时间频率&时间条件】默认不显示,勾选定时抽取数据后才显示。用户可以选择“每天、每周、每月”的任意时间定时抽取数据。运行时间频率与时间条件的设置方法详见调度任务->作业 。
【定时运行】用户点击定时运行后,会按设置的时间定时抽取数据。
点击定时运行后,状态如下:
![]()
鼠标悬停到图标时,显示抽数数据的结果信息如下:
•抽取数据信息
鼠标悬停在图标上时,可查看抽取数据的实时信息,如下图所示:
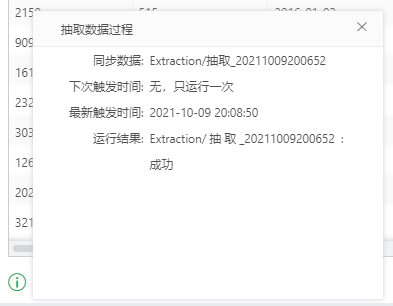
抽取数据采用调度任务执行。
同步数据:显示作业名称。
下次触发时间:显示下次触发时间。
最新触发时间:显示最后一次触发时间。
运行结果:显示作业的运行结果。
•抽取完成状态
抽取数据成功后,抽取数据旁会显示绿色图标和释放按钮,抽取数据失败后,抽取数据旁会显示红色图标,红色图标中会显示抽取数据失败的原因。
抽取数据成功如下图:
![]()
用户如需释放已同步的数据集数据,可点击 “ 释放 ”,释放已同步的数据集数据。
➢说明:
•用户只要有某个数据集的写权限就可以对该数据集抽取数据。
•修改抽取数据对话框中的配置信息后,点击“保存配置 ”只是在数据集上保存配置信息,点击“立即运行/定时运行”按钮后配置信息才会生效。
•对于一次性抽取数据,点击“取消抽取”或“释放”按钮,抽取数据旁的图标会消失,对于定时抽取数据,只有删除相关的定时任务,图标才会消失。
1.2 定时任务“同步数据”和“增量导入数据”
在调度任务中创建“同步数据”和“增量导入数据”作业,把数据库、文本文件等中的数据抽取出来,导入永洪数据集市中。
1.2.1 同步数据
同步数据成功后,运行此数据集或执行基于此数据集的报告,将会在数据集市中计算。
同步数据任务界面如下:
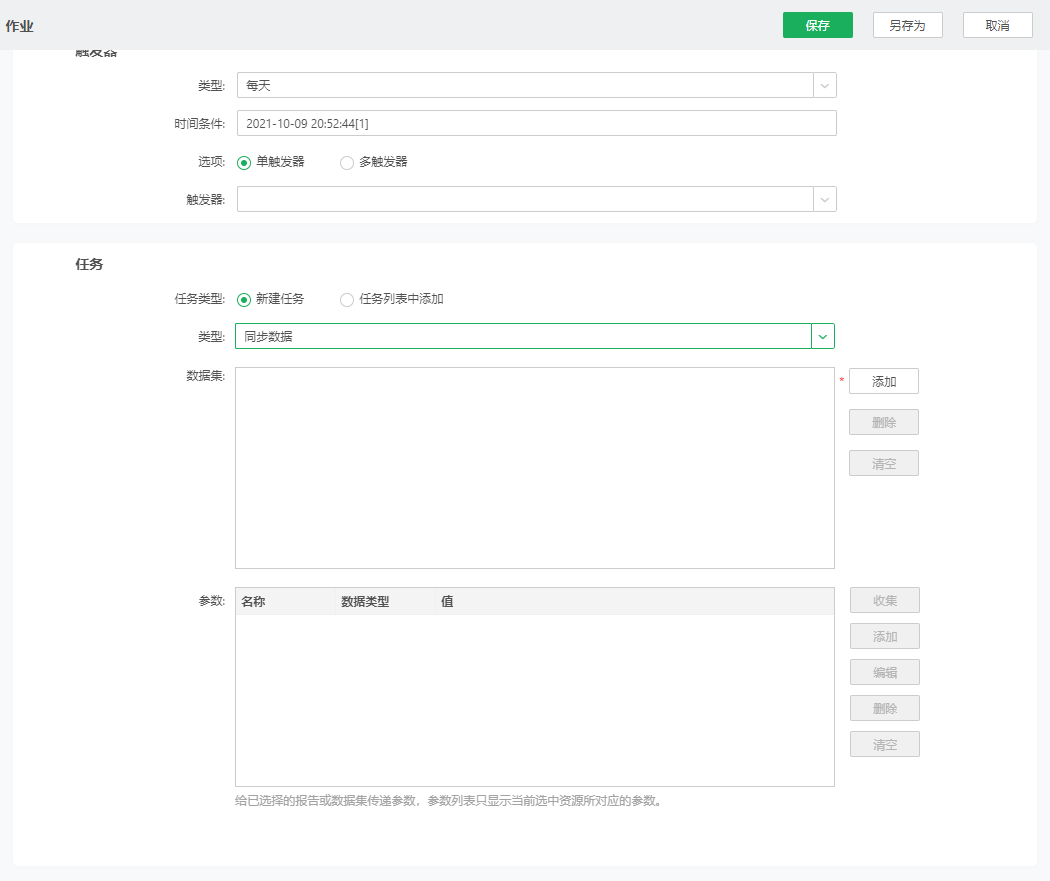
点击“添加”,可在已有的数据集中选择一个或多个需要同步的数据集。
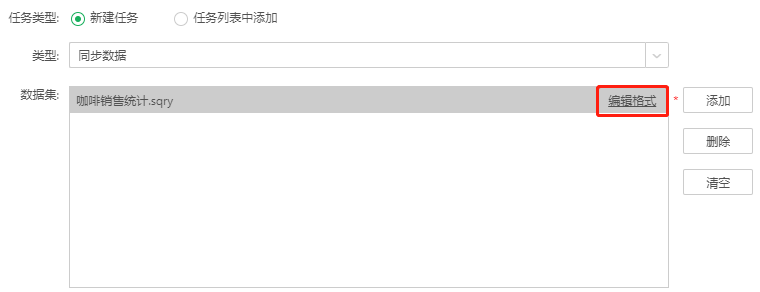
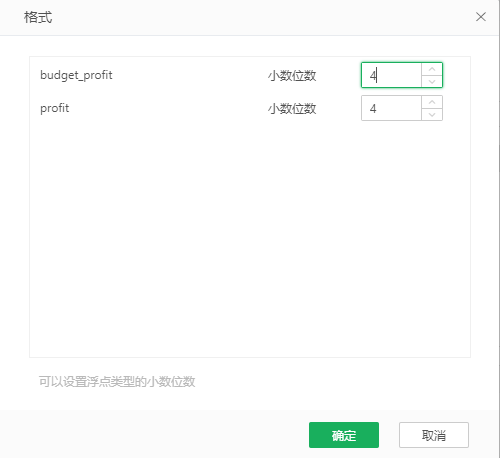
点击数据集右侧的编辑格式按钮,显示数据集中存在的双精度浮点型和单精度浮点型的数据列,将存储精度设置在集市文件夹上,支持不同的集市文件夹可以有不同的保存精度,双精度浮点型和单精度浮点型类型的数据列默认值均为4,可以修改其值以支持更高的精度计算。
1.2.2 增量导入数据
将数据集数据抽取到数据集市中,运行此数据集,不会从集市中计算和取数,需要创建集市数据集来查询数据。
增量导入数据任务专门负责把一个数据集里的数据,提取到集市系统中,如下图所示。
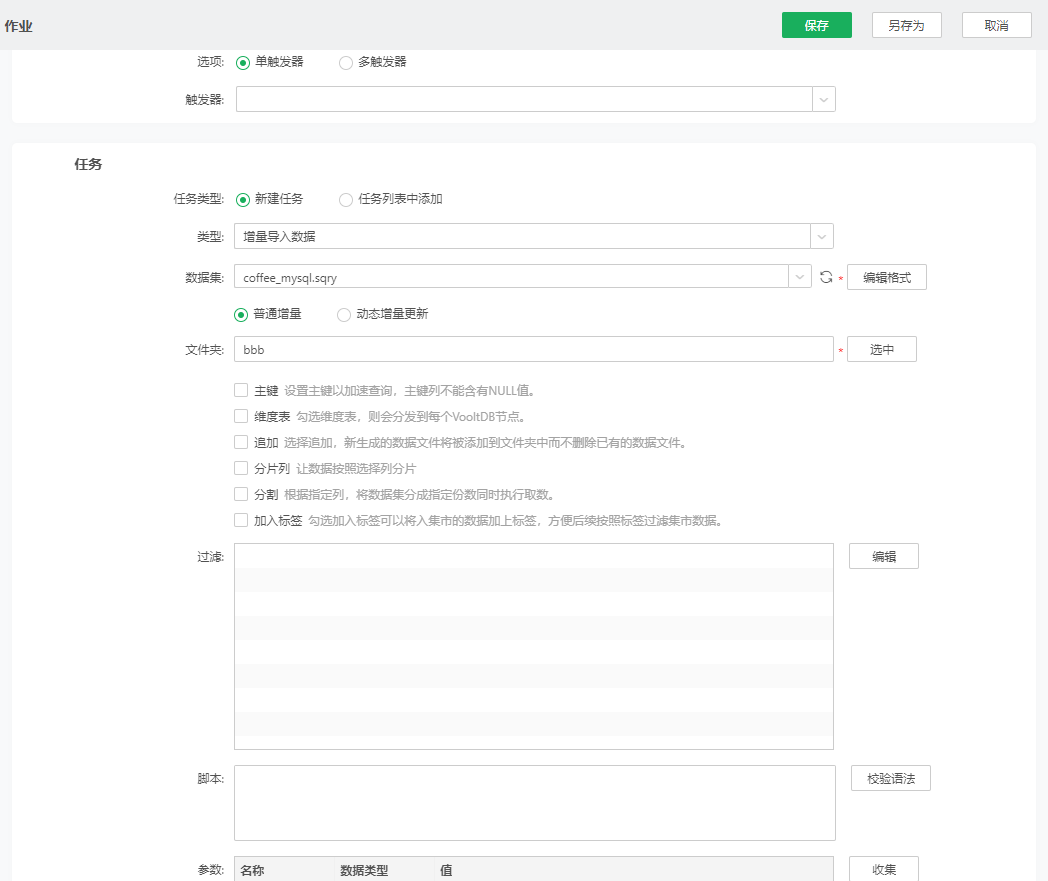
【数据集】选择要导入到数据集市中的数据集,必填项。该数据集是通过创建数据集界面来定义的,可以访问数据库数据。点击刷新数据集图标可以同步数据集列表。当增量导入数据的方式为“普通增量”时,用户可以选择数据集下拉列表中的所有数据集;当增量导入数据的方式为“动态增量更新”时,用户只能选择可以下推到数据库中执行的数据集。
【编辑格式】当所选的数据集中有浮点型的数据列时,鼠标悬浮在数据集名称上,在右侧会显示"编辑格式"按钮。点击数据集右侧的编辑格式按钮,显示数据集中存在的双精度浮点型和单精度浮点型的数据列,将存储精度设置在集市文件夹上,支持不同的集市文件夹可以有不同的保存精度,双精度浮点型和单精度浮点型类型的数据列默认值均为4,可以修改其值以支持更高的精度计算。
【文件夹】输入进行增量导入数据生成的数据集市文件夹名称,也可以选择已生成的数据集市文件夹,必填项。当用户输入或选择了一个已经存在的数据集市文件夹,系统会根据追加与否,给出重名提示,防止用户在未知情况下覆盖了已经存在的数据集市文件夹,删除了已经存在的数据集市文件,造成数据丢失。可以用多个作业把不同数据集数据或同一数据集不同条件下的数据提取到同一个文件夹中。
【过滤】在选择的数据集上增加过滤条件,将符合过滤条件的数据入集市。
【脚本】可以在运行数据集之前执行此脚本。此脚本可以修改文件夹和追加的值,还可以通过setMeta/getMeta来修改元数据,给参数赋值。
➢例如:
folder = "aaa"; //设置集市文件夹为“aaa”
append = true; //设置追加为true
setMeta("region", "beijing"); //给此次入集市的数据块打标签,标签名为日期,值为字符串的"2021-10-10"
param["market"] = "East"; //给参数market赋值East
•普通增量
【主键】用户设置主键后可以加速查询的速度,且主键列不能包含NULL值。
【维度表】当用户勾选维度表时,对于分布式系统的星形数据(一个大表,若干个小表),可以将小表的数据抽取到集市,抽取到集市的大表和小表Join时执行Map Side Join,用来提高数据的读取与处理速度。详见Map Side Join。
【追加】当用户勾选追加时,新生成的数据文件会追加到文件夹中而不删除已有的数据文件。如用户创建一个增量导入数据任务,即每天八点对某一数据集中的数据进行收集,生成数据集市文件,第一天生成的文件名称为test0,第二天生成的文件名称为test1,以此类推。当用户不勾选追加时,倘若当前系统中已经存在该集市文件夹,则会创建新的数据集市文件夹来替代。如用户创建一个增量导入数据任务,即每天八点对某一数据集中的数据进行收集,生成数据集市文件,第一天生成的文件放入文件夹 folder0 中,第二天会生成新的数据集市文件夹 folder0 来覆盖已经存在的文件夹以及文件。
【分片列】勾选分片列后,会采用一致性哈希方式对数据列进行分片存储。两个数据集增量导入集市时,勾选分片列后,选择列的数量、列的类型均匹配时:以分片列为联接条件,在联接(Join)时可以实现Map Side Join。同维度表的场景区别是,能将抽取到集市的大表和大表Join执行Map Side Join。
【分割】实现按列分割,拼where条件并行查询数据库,并行导入集市的功能。当用户勾选分割时,会自动弹出分割对话框。分割类型分为平均分割和分组分割。分割入集市实际上有两个目的,第一个是通过并行来加快入集市的速度;第二个是为了打Meta(分组分割会打Meta)。
【平均分割】平均分割只能选择一个分割列,默认为自动分割,分割份数由用户输入,默认值为4,如下图所示。

当取消自动分割时,用户可以手动输入分割值,手动分割是按照分割值将数据进行分组,再将分组好的数据存放到集市中。
➢注意:
在输入表格的分割值时,如果分割值的数目超过【n-1,n+1】范围时(n为分割份数),点击确定时候弹框提示,提示信息如下:自定义分割值只能设置在【n-1,n+1】范围,请删除多余行数的分割值。
➢例如:
如下图所示,将SALES列,按照 100=<SALES<1000 ; 1000=<SALES<= 10000 or SALES为空,进行分割,分割份数为2份。

如果分割值为[100],则按照SALES<100; SALES>=100 or SALES为空,进行分割,分割份数为2份。
如果分割值为[100, 1000],则按照SALES <100; 100 <= SALES <= 1000 or SALES为空, 进行分割,分割份数为2份。
【分组分割】分组分割不能填写分割份数,可以选择多个分割列。为了不影响导入数据的效率,建议分割列的列数不超过10。分组分割可以自动生成Meta信息,以方便对数据集市中的数据进行过滤。其中,Meta中的key为分割列对应的列名 ,Meta中的value为分割列对应的值。当用户不勾选分割时,数据集市文件会按系统默认的设置进行生成。分组分割需要满足:A. 分组的份数 <= dc.split.range (默认为1000);B.数据的总行数 > dc.unit.rows (默认为262144) ;C. 数据总行数/数据分割列不同值>262144行才会执行。
【加入标签】8.6版本我们在增量导入数据新增了加入标签的属性,用来给入集市的数据集中的指定列打标签(Meta),同时解决了当数据集SQL加载较慢时,使用分组分割方式打Meta会使作业运行时间过长的问题。
在8.6版本之前,我们能通过分组分割的方式对入集市的数据集打标签,但是由于分割实现机制的问题,导致了当数据集本身SQL执行时间比较长时,分割会加大资源的消耗,延长作业的运行时间。原因如下:
对于有些复杂的SQL查询,基础查询本身花费的时间比较久。假设基础查询是A,我们平均分成4分,那么实际上运行了5个查询。
SELECT MIN("XX"), MAX("XX"), COUNT(*) From A ---平均分割,自动分割
4个SELECT * From A WHERE BETWEEN “XX” and “XX”
SELECT "XX", COUNT(*) From A GROUP BY “XX” ---分组分割
每个不同值增加一次部分查询。加上为了计算进度新起线程执行的SQL:
SELECT COUNT(*) FROM (select "XX" from COFFEE_CHAIN) "SUB_QRY"
8.6后新增加入标签属性来解决这个问题,使用加入标签的限制条件与分组分割相同(需要满足:A. 分组的份数 <= dc.split.range (默认为1000);B.数据的总行数 > dc.unit.rows (默认为262144) ;C. 数据总行数/数据分割列不同值>262144),达成的效果与分组分割一致。但是当SQL运行时间较短时,加入标签不会像分组分割一样起到加速作业运行的效果,仅当SQL运行时间较长时,加入标签的运行速度会小于使用分组分割打Meta的运行速度。
➢说明:
Yonghong Desktop 只支持追加、分割、加入标签。
•动态增量更新
动态增量更新用于动态更新最新的数据,并加入集市。
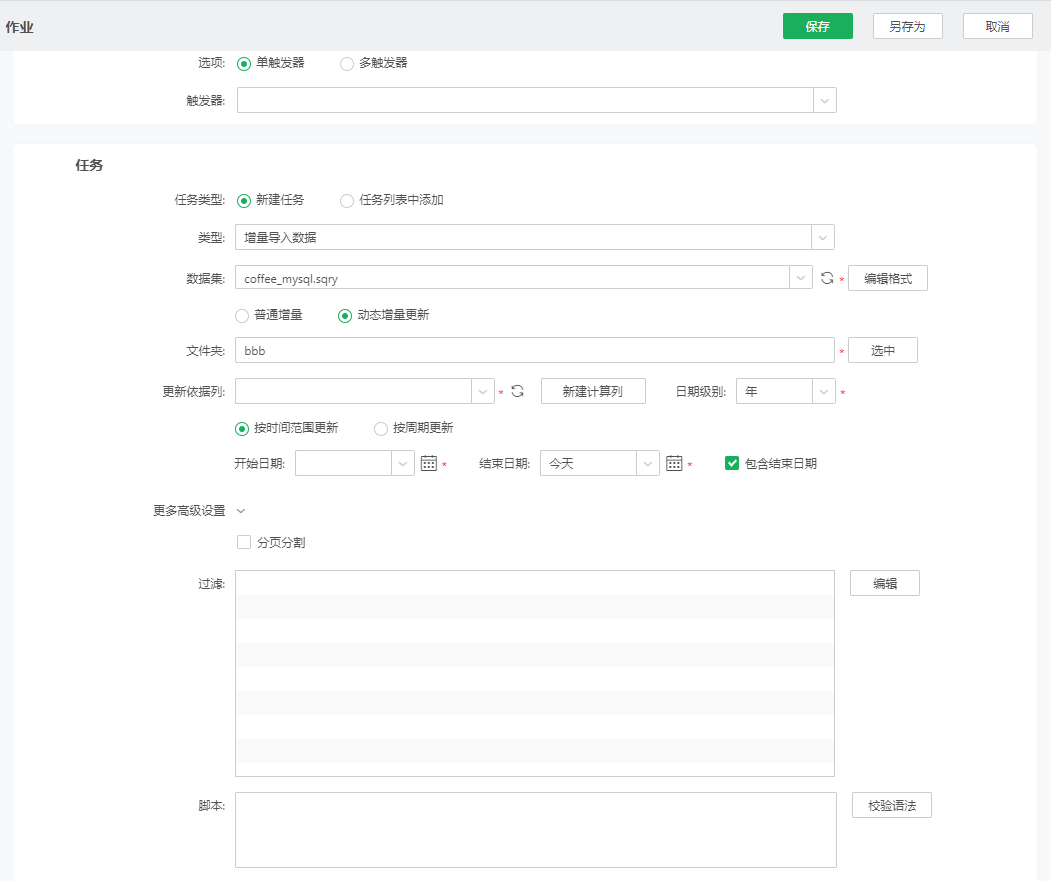
【更新依据列】更新依据列只能是日期类型或时间戳类型,必填项。用户可以选择数据集的原始列,也可以新建计算列,但只能新建一个计算列,新建完计算列后可以编辑计算列。点击“刷新更新依据列”可以同步数据集的列。其中新建计算列详情可参考计算列。
【日期级别】日期级别包括年、季度、月、周和天,默认为年,必填项。选择日期级别后,会根据选择的日期级别生成集市文件。
【按时间范围更新】设置要更新集市数据的开始日期和结束日期,必填项。开始日期和结束日期可以选择今天、昨天、本周、上周、本月、上月、本季度、上季度、本年和去年这些内置参数,也可以选择具体时间。包含结束日期选项默认为勾选状态。
【按周期更新】设置要更新集市数据的一段时间,默认为近3年到今天,必填项。
➢例如:
当前日期2021.10.10,设置如下(不包含结束日期):
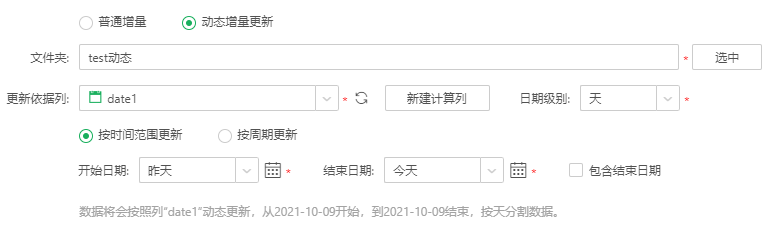
先删除集市中2021.10.9日的数据,并将数据库中2021.10.9日最新的数据入集市,入集市的数据执行类似以下1条SQL:
SELECT date1, number1, string1
FROM fiona_90.`fiona_日期`
WHERE ( date1 >= '2021-10-09' ) AND ( date1 < '2021-10-10' )]
包含结束日期,则执行类似以下2条SQL:
•SELECT date1, number1, string1
FROM fiona_90.`fiona_日期`
WHERE ( date1 >= '2021-10-09' ) AND ( date1 < '2021-10-10' )]
•SELECT date1, number1, string1
FROM fiona_90.`fiona_日期`
WHERE ( date1 >= '2021-10-10' ) AND ( date1 < '2021-10-11' )]
【更多高级设置】展开更多高级设置后,用户可以使用【分页分割】,默认不勾选。当数据集所使用的数据库支持分页,且数据集的数据量很大,需要快速分割入集市时,可以使用分页分割。勾选分页分割后,可以按照主键列降序排序,每页默认按1000000行分页。主键列默认为更新依据列,用户可以根据需要自行设置每页的行数和主键列。支持分页的数据库包括:MySQL、Oracle、DB2、SqlServer、Gbase8a、Kylin、SysbaseIQ、Hana。