1.背景介绍
员工离职率与组织成长和组织活力息息相关。离职率影响组织的活力、招聘成本、工作交替的时间成本、核心技术保留、企业文化等问题。某公司希望发现员工离职的主要原因,针对存在问题对症下药,降低员工离职对于公司的各方面损失。
2.数据说明
企业提供员工个人信息汇总统计表,每条记录代表一名员工个人信息,共计14999条记录。数据字段描述如表1所示。
字段名称 |
字段描述 |
数据类型 |
|---|---|---|
Average_Working_Hours_per_Month |
每月平均工时 |
数值型 |
Complete_Projects |
完成项目数量 |
数值型 |
Department |
部门 |
文本型 |
Employee_Competence |
工作能力 |
数值型 |
Mistakes |
失误次数 |
数值型 |
Salary |
工资区间 |
文本型 |
Satisfaction_Degree |
满意度 |
数值型 |
Whether_Get_a_Promotion_in_Five_Years |
五年内是否晋升 |
数值型 |
Whether_Resign |
是否辞职 |
数值型 |
Working_Years |
工作时长(年) |
数值型 |
3.方案介绍
聚类分析又称之为群分析或点群分析,是通过将数值特征类似的样本划分到同一个簇中,它是一种多元性统计分析方法,建模过程中不需要人为总结经验规律,模型会遵循同类个体相似度高、不同个体差异化大的原则,自动在样本数据中“总结规律”。
KMeans算法是用于解决聚类问题的一种基于划分的算法。由于算法运行过程简单,运算效率较高,因此在当每个簇形状是凸型并且不同簇之间具有较大差异性时,KMeans聚类具有良好的表现。
4.方案分析
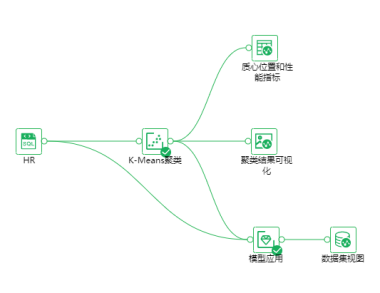
1)搭建模型工作流
先通过KMeans聚类算法对数据进行分组,最后通过统计各组离职率,通过研究离职率较高组的质心特征,总结离职规律。
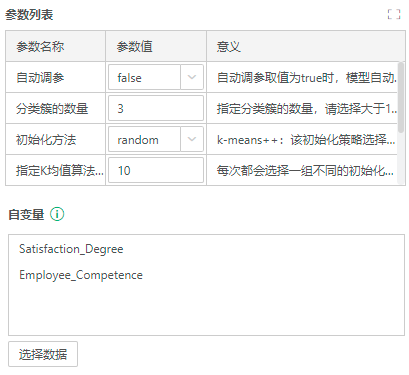
2)参数配置
根据参数列表中的“意义”项的指引,按需求填写参数值。本案例分类簇数量设置为3,模型将把原始数据集分为3个簇。初始化方法在下拉列表中选择random,其他超参数可在案例中查看。
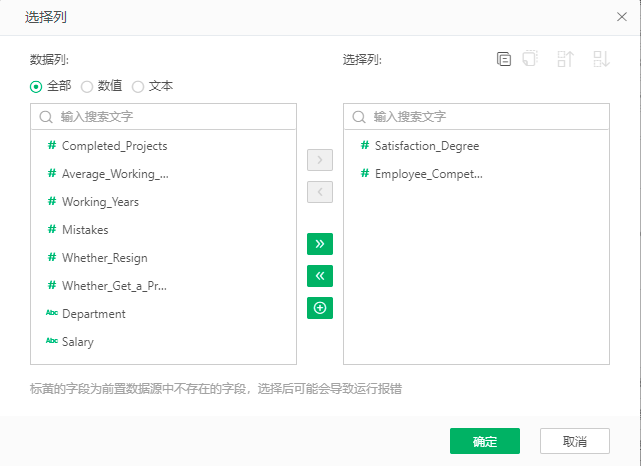
3)字段选择
KMeans是一种无监督算法,只需要选择相应的数值型特征字段输入模型,点击自变量下方的选择数据按钮。再弹出的字段列表中选择相应的字段。
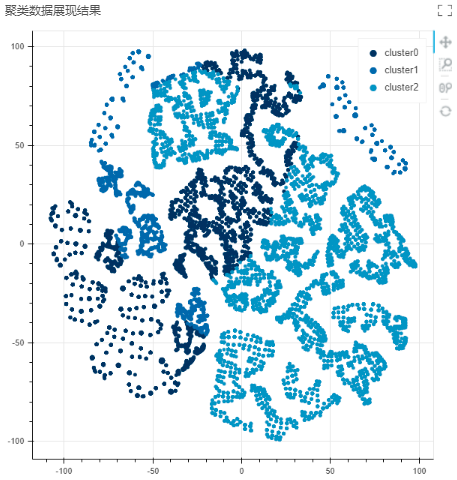
5.结果说明
根据输出类型列表,K-Means算子将输出KMeans模型、质心和模型的性能指标、聚类结果的可视化图。
•KMeans模型,可连接模型应用节点,用模型进行簇标签的预测(Cluster字段)。
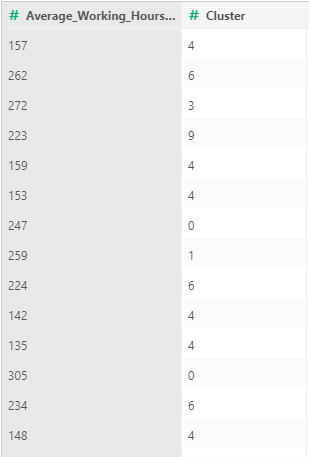
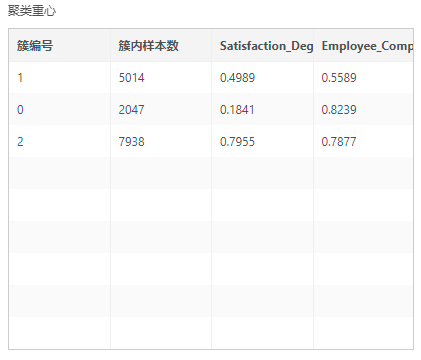
•质心和模型的性能指标,各簇中相应特征的平均值,以及模型的表现相关数值可作为调整模型超参数的参考值。
其中,轮廓系数趋近-1表明聚类结果不好,簇之间有明显重叠,趋近于1表明簇内实例之间紧凑,各簇之间差异显著。Calinski-Harabasz指数在多次调整参数进行比较时,发挥实际作用,该值越大说明聚类效果越好。KMeans聚类可以通过调整分类簇的数量这个参数,并观察上述两个指标的变化情况,找到最优的聚类效果。
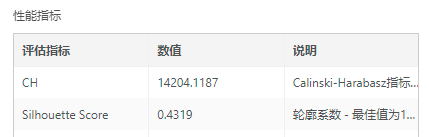
•聚类结果可视化
不同颜色分别代表不同簇的样本点。