1.数据源和数据集配置
•qry.sample.rows=5000
样本行数,默认值为5000,影响数据集中的样本行数:

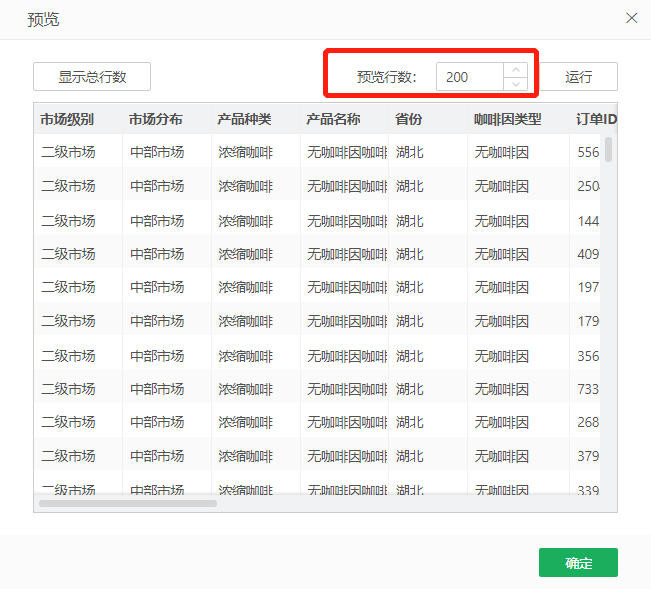
•qry.preview.rows=200
预览行数,默认值为200,影响数据集预览时默认显示的行数。可以通过【管理系统>系统设置>系统参数配置】进行设置。
•qry.preview.max.rows=2000
数据集最大预览行数,默认值为2000,可配置大于1的整数值。在数据集输入的预览行数大于配置值时,提示用户输入1到配置值之间的值。
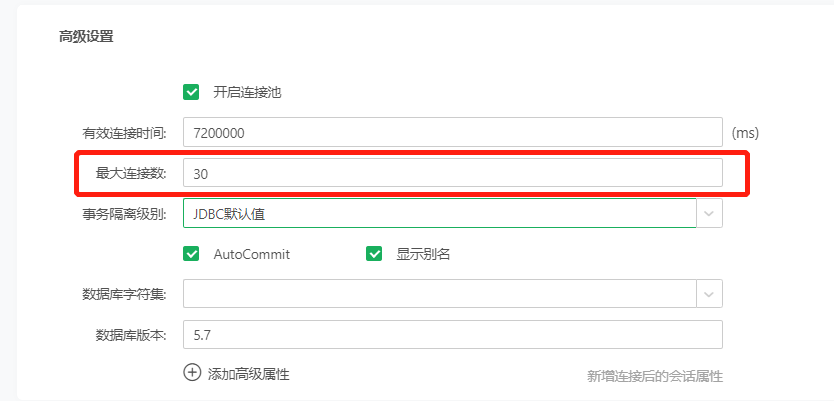
•qry.conn.count=30
最大连接数,默认为30,影响数据源默认的最大连接数,创建时不会显示,打开已添加的数据源会显示:
•sql.conn.minEvictableIdleTimeMillis=1800000
最长连接时长,如果一个数据库连接超过此配置时间未被使用就需要被释放,单位为毫秒(ms),默认为30分钟。
•sql.pool.timeBetweenEvictionRunsMillis=60000
连接池清理空闲连接的周期,单位为毫秒(ms),默认为一分钟。
•sql.conn.minIdle=0
最少维持的闲置连接数。即使没有需求,也要至少维持多少个闲置连接,以应对突发需求。默认为0。
•qry.cache.count=500
缓存多少个数据集的数据,默认为500个。
•qry.cache.timeout=900000
缓存的数据保留多久,单位为ms,默认为900000,即15分钟。
•cube.cache.cnt=30
缓存多少个多维数据集结果。
•cube.cache.timeout=1800000
缓存的数据保留多久,单位为ms,默认为1800000,即30分钟。
•cache.engine.single.max.row=10000
配置单个结果集大小的行数,超过限制不生成缓存。
•cache.engine.single.size=25M
配置的单个结果集大小的大小配置,超出限制不生成缓存
•dc.orderby.limit=500000
后期处理或集市计算时,如果汇总结果集超过所配置值(默认为500000),则不排序。允许配置的最大值为int类型的最大值 2147483647。
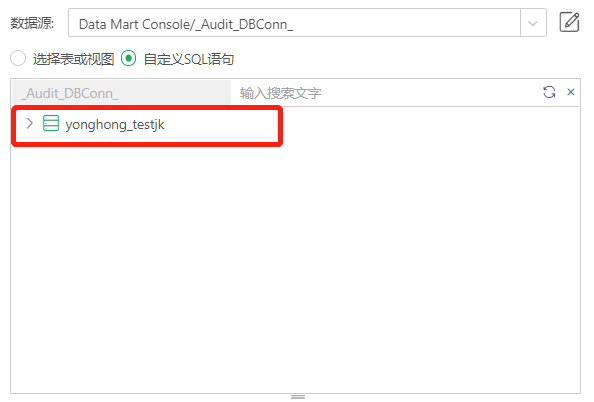
•qry.global.meta=false
默认为false,如果是false,数据集编辑区的表或视图界面只会显示数据源里面指定的catalog和schema,否则的话会把数据库所有的catalog和schema下的meta 信息都拿回来:
•qry.batch.update.num=1000
回写数据库的时候多少行数据提交一次,默认为1000。
•qry.dbmeta.timeout=10000
取元数据的时间如果超过了设置时间,抛错提示,默认为10秒。
•fast.qry.pool.size=100
处理快查询的池子大小。
逻辑中将快查询和慢查询分开处理,避免慢查询长期占用资源,造成阻塞,导致界面不响应。
•fast.qry.pool.init.timeout=5000
查询Init的超时时间,超时则认为是慢查询,放入慢池子。
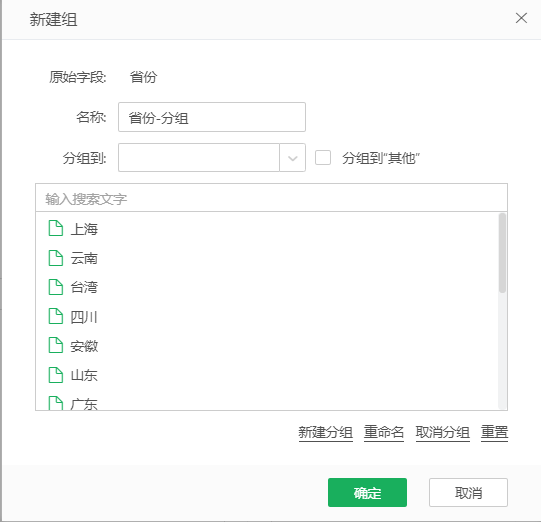
•browse.namedGroupcol.maxrow=1000
新建分组时加载的条数,默认值是1000:
•sap.bw.variable.value.usekey=false
默认是false。用于SAP BW,cube中带参数,在多维数据集中使用cube刷新参数后,如果属性是false,参数值显示的是unique_name+description,如果是true,显示的是name+description。
•monday.first.day.of.week=false
控制周从周一开始还是从周日开始:默认值false从周日开始,true从周一开始;例如日期表达式:天_周(DayofWeek),周_年(WeekofYear),年周(YearWeek);报表中日期组件等等。默认情况如图:

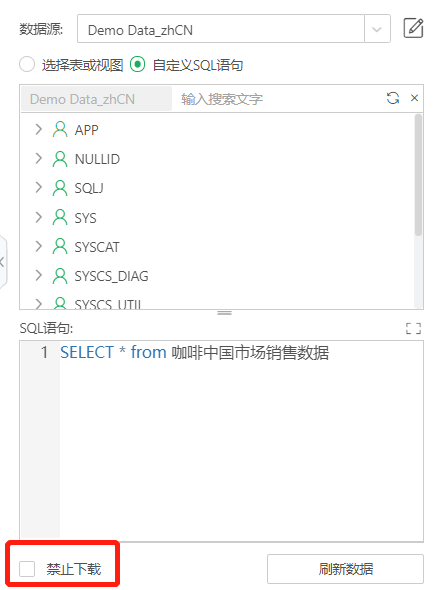
•data.download.strict=false
控制下图禁止下载开关的限制程度。数据集勾选禁止下载后,该属性如为false,依赖该数据集的资源也可以导出图片或pdf;当属性值为true,全部不能导出。默认为false。
•flow.query.node.cache=true
组合和自服务数据集是否缓存。 默认值是true,走缓存;设置为false后不走缓存。
•elasticsearch.timezone=UTC
Elasticsearch 的时区默认
•kylin.timezone=UTC
Kylin的时区默认。
➢注意:由于部分情况下Kylin的时区差8个小时,这时候需要设置此属性默认加8,数据才正确。
•external.resources=XXX.css
隐藏界面操作,详情参考界面上隐藏操作。
•metadatapane.default=meta或data
配置数据集右侧Pane默认显示元数据或预览数据。不区分大小写,对除了自服务数据集、组合数据集,多维数据集以外的数据集生效。支持2022年12月后发布的9.2、9.4、10.0稳定小版本,如10.0.1。
控制数据存储为double还是decimal,默认值为true,将decimal处理成double,会降低数据的精度;配置false时,保留decimal原始类型,高精度计算。值为true,同时数据集上设置了_DECIMAL_KEEP_ACCURACY_=true,此时数据集上的内置参数优先级更高, 保留decimal原始类型。
•pre.process.timeout=10000
查看数据集数据详情和总行数时,数据库查询或集市计算的超时时间,超过配置时间则弹提示“执行SQL慢,请检查对应数据库”或“执行集市计算慢”,默认值为10000,单位毫秒。
•post.process.timeout:查看数据集数据详情和总行数时,内存计算的超时时间,超过配置时间则弹提示“后期处理计算慢,请进行性能检查查看具体原因”,默认值为10000,单位毫秒。
•dataset.save.check:数据集保存时是否进行性能检测和自服务数据集节点的有用性检测。默认true表示保存时当性能检测或有用性检测不通过时弹出检测结果的提示框,设置成false表示保存时不弹此框。
•dataset.save.performance.valid.check=true
默认值为true,控制保存SQL数据集、自服务数据集、组合数据集时是否进行性能检测,配置为false,不进行性能检测。
•query.meta.cols.limit=500
限制数据集刷新元数据列的数量 ,默认值为500。
•dictionary.query.maxrow=10000
控制字典表的数据行数,防止字典过大,默认值为10000。
•execute.notify.enable=true
是否开启前台“正在执行”提示,默认true,开启,false,关闭。
•execute.notify.interval=2000
检测一次连接的中间状态(等待、执行中、执行完成)的间隔时间,默认2s。
2.SQL数据库配置
•sql.charset=
将sql送入数据库取数时,指定数据库识别(匹配)的字符集,默认为空。
•sql.blob.image=true
Blob类型存储,true为image,false为string。默认为true。
•sql.creatable.read.rows=100
创建表时,依据前多少行计算string列的宽度,默认为100。
•sql.push.select=true
是否将column push到subquery的select中,把*替换成具体的列,默认为true。
•sql.push.filter=true
是否将filter push到subquery里,默认为true。
•hive.execute.mode=nonstrict
两种模式:strict,nonstrict;
strict:模式比较严格,可以防止用户执行那些可能产生意想不到的不好的效果的查询。即某些查询在严格模式下无法执行。可以禁止3种类型的查询:带有分区的表的查询,带有orderby的查询,限制笛卡尔积的查询;
nostrict:非严谨模式,默认采用此模式。
•conn.hive.transwarp=false
数据库拼SQL时,若此属性为true,order by 后面要用alias,值为false时只用列名(星环例外,都使用别名)。
•sql.mysql.ali.mpp=true
控制ADS(分析型数据库)数据库的引擎:COMPUTENODE Local/Merge(简称LM)或Full MPP Mode(简称MPP)。默认是true引擎是MPP,这种引擎支持的sql语法更多,设置为false时为LM。
•conn.create.timeout=30000
创建连接的最大耗时, 超过此时间, 就不再重新尝试创建连接, 单位毫秒(ms),默认为30000,即30s。
•conn.create.attempt.times=3
重连次数,超过此次数就不再重连,默认为3。
•oracle.jdbc.ReadTimeout=7200000
控制oracle连接超时参数,在指定时间内连接不上会抛出异常,单位毫秒(ms),默认为7200000,即2小时。
•hana.views.permit.memory.calc=false
针对hana视图,拖拽到组合自服务数据集中,默认为false则限制后期处理(就是不允许取消库内计算),预览会提示报错,可以设置成true,但是计算的结果可能会不对。
•sqlrouter.engine.url.prefix=jdbc:router:
ThunderEngine连接时支持选择底层数据库方言。
3.Mongo数据集配置
•mongo.read.rows=200
控制先读取多少行数据以判断每列数据的数据类型,默认为200。
•mongo.allow.diskuse=true
控制mongo的参数: allowDiskUse:true,即允许使用磁盘缓存。mongo v2.6开始支持此功能。
如果低于此版本,需要设置为mongo.allow.diskuse=false
4.Excel数据集配置
•query.excel.cache.row=1000
读满多少行后从内存存入到grid中,默认为1000。
•query.excel.head.rows=100
控制先读取多少行数据以判断每列数据的数据类型,默认为100。
•query.excel.correlation=0.05
设置Excel数据集刷新元数据获取有效列的显著性水平,默认为0.05。
•excel.upload.size=200
Excel数据集,上传文件的大小不能超过这个值,单位为兆(M),默认为200。
•excel.upload.allow.suffix=xlsx,xls,csv,log,txt
Excel数据集限制上传的文件类型,默认是xlsx,xls,csv,log,txt。
5.SQL数据集配置
•sql.parser.available=CLICKHOUSE,DB2,MYSQL,ORACLE,POSTGRESQL,SQLSERVER,ELASTICSEARCH,GAUSSDB100,GAUSSDB200,GBASE8A,GREENPLUM,HANA,HBASE,HIVE,IMPALA,SPARK,PRESTO,KINGBASE,KYLIN,SYBASEIQ,ANALYTICDB,MAXCOMPUTE,CTSDB,TBDS,TBDSOLAP,FUSIONINSIGHTELK,FUSIONINSIGHTHD,HUAWEICLOUDDWS,TRANSWARP,DAMENG,INFORMIX,TERADATA,VERTICA,GENERIC,ACCESS,DATAMART,DERBY
以上默认配置的数据源创建的SQL数据集显示性能优化设置,默认不勾选,没有配置的不显示性能优化。数据源类型名称不区分大小写,添加多种数据源,用英文逗号分隔。
6.自服务数据集配置
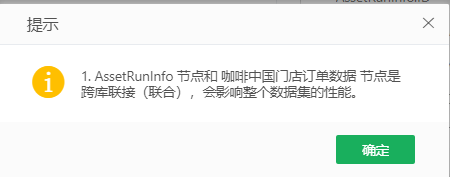
•flow.query.support.multisource=1
自服务数据集中联接和联合两个节点引用的sql数据集和物理表是否同源(同源:指ip和端口一致的数据源),如果不同源:0(默认,保持后期处理的现状),1(弹出下图提示不同源,但是可以继续使用),2(弹出提示并彻底禁止继续使用)。
•conn.multisource.strict
false时,检查IP和端口(例外情况:Oracle比较URL,同时还比较了Schema;PostgreSQL还比较了Catalog)是否一致判断是否同源;true时,只要是不同的数据源,就认为是不同源。
•push.max.cases=500
自循环列拼下推SQL的是case when,当case when 超过配置数量时就不下推SQL,配置数量以内才会执行SQL,默认为500。
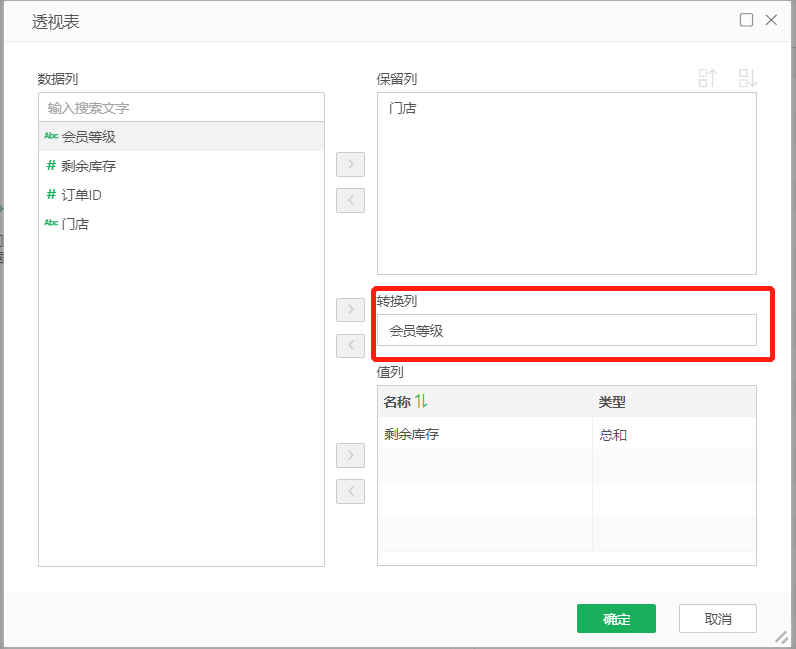
•pivot.max.columns.count=1000
自服务数据集中透视表节点,转换列的值支持的数量上限,默认为1000。
•sql.in.value.limit=1000
限制了过滤器里“其中一个”下推SQL时in的值的个数,默认1000;超过配置值,执行时给出提示:过滤条件为“其中一个”时,传递的参数值个数不能超过{配置值}个。
•hide.postprocess.function=false
根据数据源智能隐藏不能下压的函数,配置为true时,开启智能隐藏;默认为false。
7.数据模型配置
•query.model.node.sample.row=1000
数据模型新增或编辑关系的时候,取前1000行数据检测是否有重复值,默认值1000。
8. 数据处理配置
•qry.disable.pre.calc=false
V10.2开始默认将常量计算列进行预处理。通过配置该参数控制常量计算列是否预处理,true为不预处理,false为预处理,默认值为false。同时提供内置参数_DISABLE_PRE_CALC_控制是否预处理。
➢说明:常量计算列预处理,即对未引用字段列的,直接算出结果再下推到数据库执行。