1.概述
用决策树算法进行回归模型训练。
➢例如:决策树回归可以用于预测客流量。
输入:1个数据集。
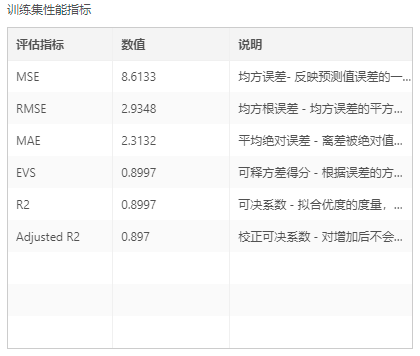
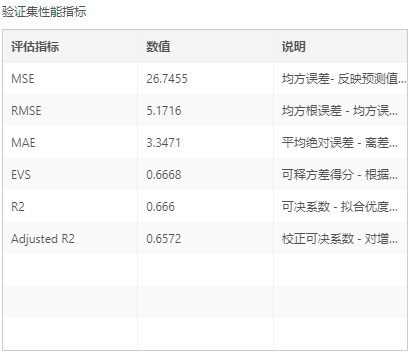
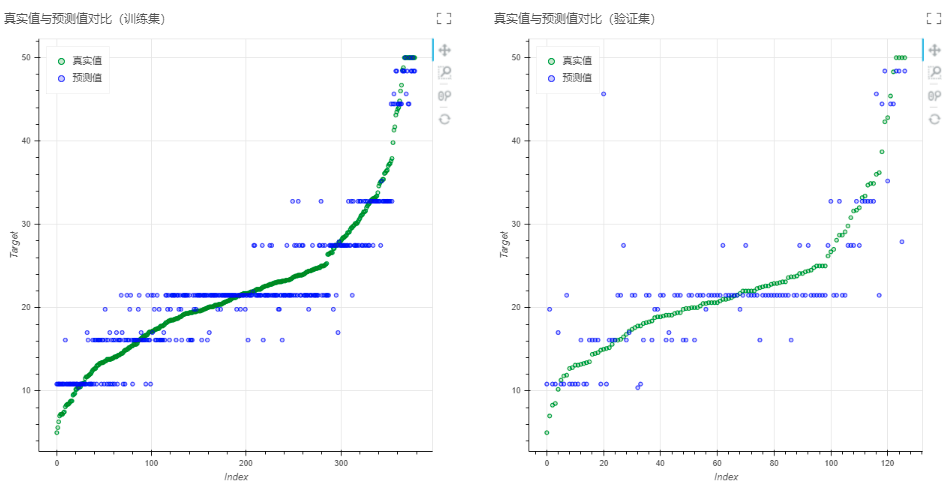
输出:模型、真实值与预测值对比图(训练集)、真实值与预测值对比图(验证集)、训练集性能指标(MSE、RMSE、MAE、EVS、R2、Adjusted R2)、验证集性能指标(MSE、RMSE、MAE、EVS、R2、Adjusted R2)、决策树、特征重要性图、平行坐标图、PMML文件。
2.配置方法
将决策树回归节点添加到实验后,可通过右侧的“配置项目”页面,对决策树回归节点进行设置。
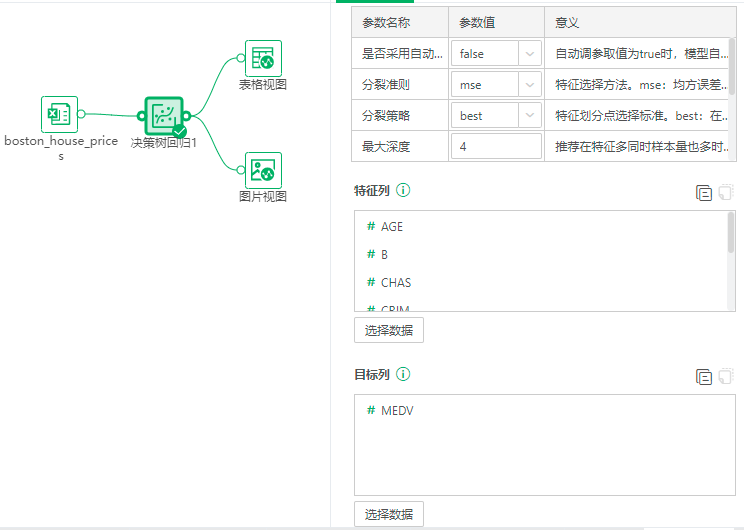
2.1参数列表
【使用集群】选择true时,算子使用分布式集群运行,选择false时单机运行,默认为false。集群运行需要在集群环境下才能生效。
【自动调参】自动调参取值为true时,模型自动进行超参数优化,取值为false时,需要手动调参。
【分裂准则】mse:均方误差。friedman_mse:修正的均方误差。mae:平均绝对误差。
【分裂策略】best:在所有分裂点中找到最优分裂点,适用小数据量。random:随机在部分分裂点中找到局部最优分裂点,适用大数据量。
【最大深度】推荐在特征多同时样本量也多时,适当增大最大深度设置。设置为0时,禁用最大深度限制。
【分裂所需最小样本数】节点中样本量小于设定值,该节点停止分裂,可限制决策树分支的增长,设定值越小决策树模型复杂度越低,泛化能力提高,但是会减低精度。
【叶子节点最小样本数】当前节点的子节点中的任一节点样本量小于设定值,会和其所有兄弟节点被剪枝,设定值越小决策树模型复杂度越低,泛化能力越低,但是会增大精度。
【叶子节点最小样本权重和】当前节点的子节点所有样本权重之和小于设定值,会和其所有兄弟节点被剪枝。
【最大特征数】特征划分时考虑的最大特征数。auto:最大特征数=sqrt(特征总数);sqrt:最大特征数=sqrt(特征总数);log2:最大特征数=log2(特征总数);None:最大特征数=特征总数。
【最大叶子节点】推荐在特征多同时样本量也多时,适当限制整棵树的叶子节点数量,设置限制整棵树的叶子节点数量,设置为0时,禁用最大叶子节点数。
【最小不纯度降低值】决策树在创建分支时,信息增益必须大于这个设定值,否则节点不分裂。该值设定越低,泛化能力越低,但是会增大精度。
2.2选择变量
特征列:选择模型训练的特征字段,至少选择一个字段。
目标列:选择模型预测的目标字段,只能选择一个字段。
选择数据页面操作见插件节点>选择数据。
3.查看结果
可通过连接多视图节点查看结果或连接表格视图来查看性能指标。连接图片视图来查看真实值与预测值对比、决策树、特征重要性图和平行坐标图。连接保存为PMML文件,将训练后的模型转化为pmml格式,输出pmml文件。也可连接保存为训练模型节点,将模型保存为操作节点后再次使用。
评估指标可以通过说明进行了解。
特征重要性展现了每个特征对于模型的影响大小,并对它们进行降序排列。
平行坐标图中颜色的深浅代表了数据分布情况,颜色越深代表该区间上的数据分布越多。