1.概述
关联规则挖掘过程主要包含两个阶段:第一阶段必须先从资料集合中找出所有的高频项目组,第二阶段再由这些高频项目组中产生关联规则。
输入:1个数据集,数据集中应该至少有事务标识列和事项列。
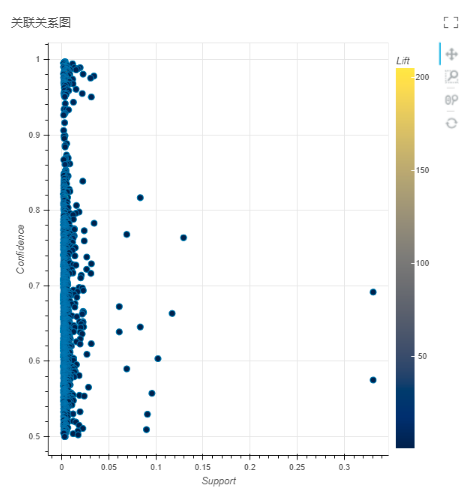
输出:事务之间关联关系结果,关联关系图。
2.配置方法
将FP-Growth节点添加到实验后,可通过右侧的“配置项目”页面,对FP-Growth节点进行设置。
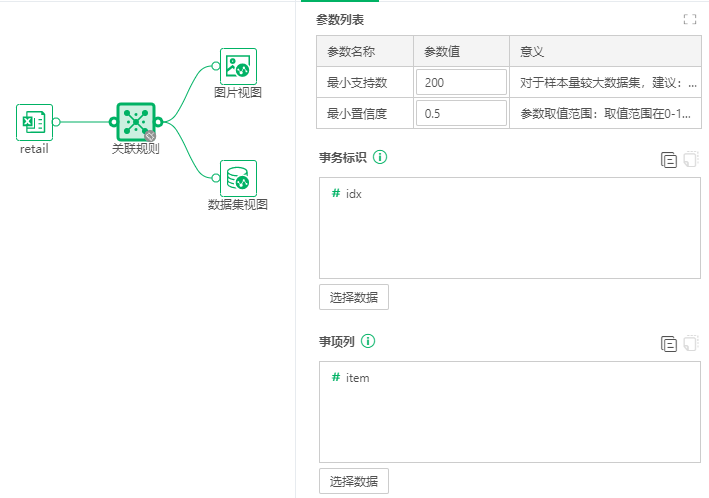
2.1参数列表
【使用集群】选择true时,算子使用分布式集群运行,选择false时单机运行,默认为false。集群运行需要在集群环境下才能生效。
【最小支持数】对于样本量较大数据集,建议:最小支持数/事务标识总量(支持度)>0.5%,应当小于所有事务中的最大事务项数量。例如,事务标识总量=10000,最小支持数建议大于50。参数取值范围:取值范围大于等于1的整数。
【最小置信度】参数取值范围:取值范围在0-1之间。
2.2选择变量
事务标识:选择事务主体标识列,通常为某个事务ID,如订单号、Session_ID等等,仅能选择一列。
事项列:选择记录事项编号、名称等等信息的字段,仅能选择一列。
选择数据页面操作见插件节点>选择数据。
3.查看结果
可通过连接数据集视图查看事务之间关联关系结果,连接图片视图来查看关联关系图。
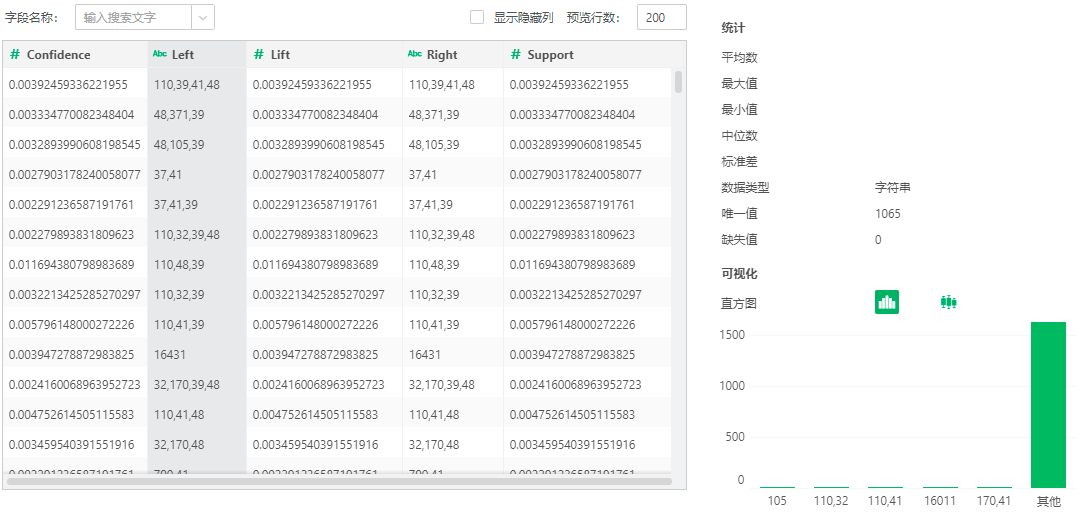
【左项】规则的先导项集。
【右项】规则的结论项集。
【支持度】项集出现的次数除以总的记录数。
【置信度】项集{X,Y}同时出现的次数占项集{X}出现次数的比例。
【提升度】度量项集{X}和项集{Y}的独立性。数值越大模型越好。