1.背景介绍
某发电厂目前对备用柴油发电机组上继电器是否合格的判定标准的制定,主要靠人为经验评估,无法实现更为精准的判定标准。我们可以根据历史积累的训练数据,建立分类模型,从而更智能地判断继电器是否合格。
2.数据说明
继电器实际维护性检测数据分为训练集(718个样本)和测试集(127个样本)。下表为部分继电器实际维护性检测数据的字段含义。
字段名称 |
字段描述 |
数据类型 |
|---|---|---|
ID |
原继电器编号和位置编号的合并信息,已脱敏 |
数值型 |
OCR1 |
常开接触电阻1,继电器检测信息的一个指标 |
|
OCR2 |
常开接触电阻2,同上 |
|
OCR3 |
常开接触电阻3,同上 |
|
OCR4 |
常开接触电阻4,同上 |
|
CCR1 |
常闭接触电阻1,同上 |
|
CCR2 |
常闭接触电阻2,同上 |
|
CCR3 |
常闭接触电阻3,同上 |
|
CCR4 |
常闭接触电阻4,同上 |
|
CR |
绕圈电阻,同上 |
|
CR_Deviation |
绕圈电阻偏离度,同上 |
|
ReleaseBounce |
释放回跳,同上 |
|
ReleaseTime |
释放时间,同上 |
|
ReleaseVoltage |
释放电压,同上 |
|
PullInBounce |
吸合回跳,同上 |
|
PullInTime |
吸合时间,同上 |
|
PullInVoltage |
吸合电压,同上 |
|
Qualified |
继电器检测结果 |
布尔型 |
3.方案介绍
根据背景内容,可将该问题抽象为二分类问题。目标列为Qualified字段,以true为正样本,false为负样本。针对这种具有多个连续值特征的二分类问题,我们可以使用业界常用的XGBoost二分类算法。
4.方案分析
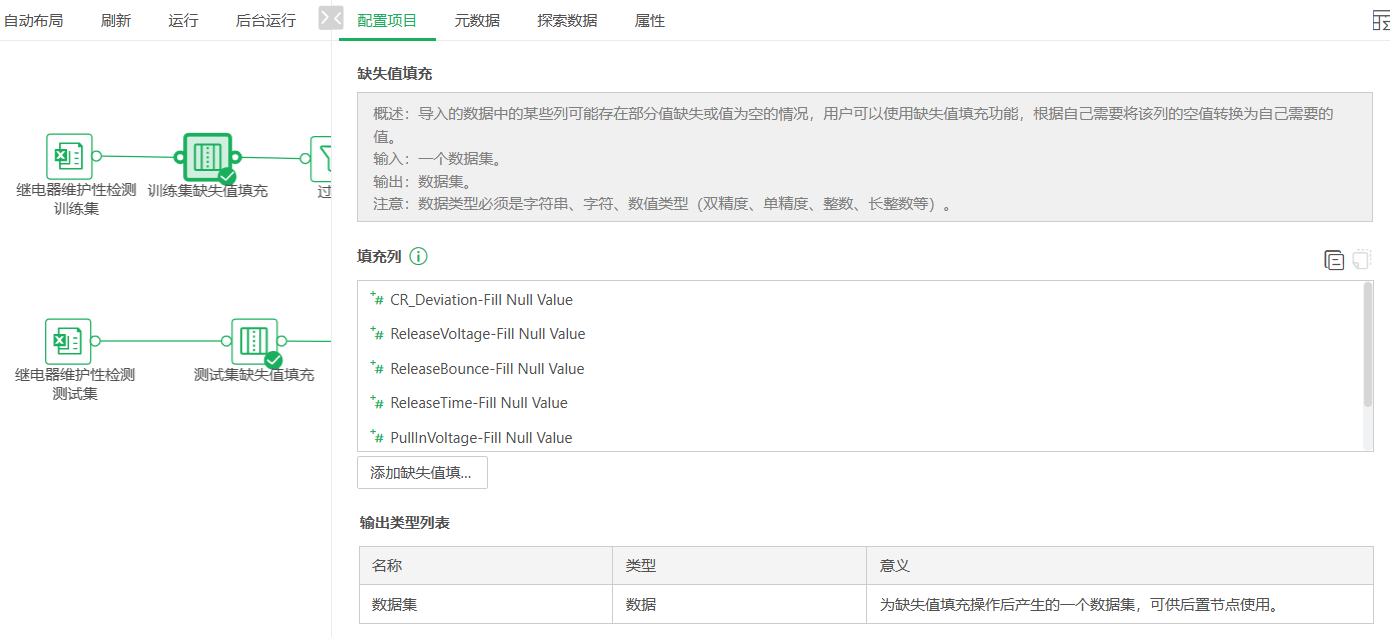
首先进行数据预处理,包括填补缺失数据、排除异常数据、转换数据形式等。
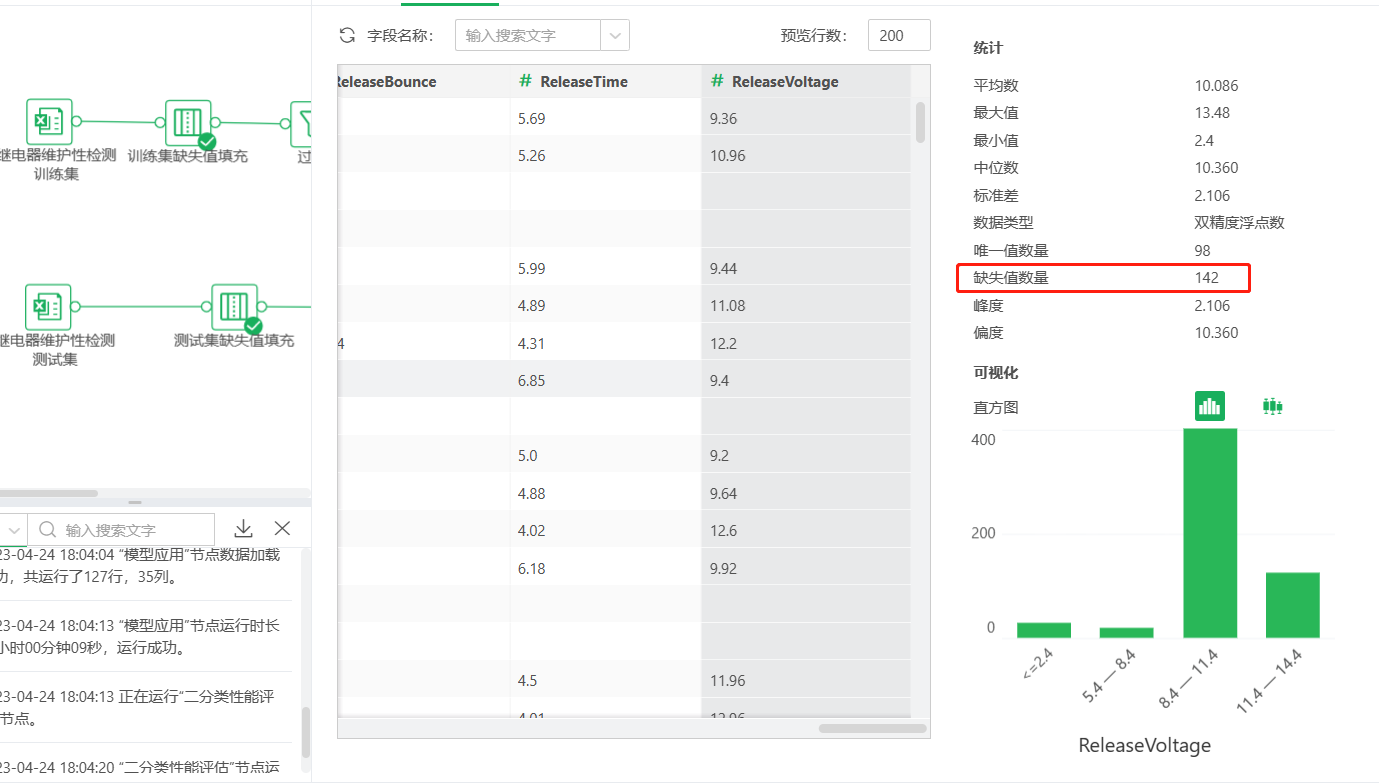
在检测数据中,通过探索数据中对字段的统计进行分析,可以发现CR_Deviation,ReleaseVoltage,ReleaseBounce,ReleaseTime,PullInVoltage,PullInBounce,PullInTime这几个字段存在缺失值,对上述字段分别使用中位数进行缺失值填充。
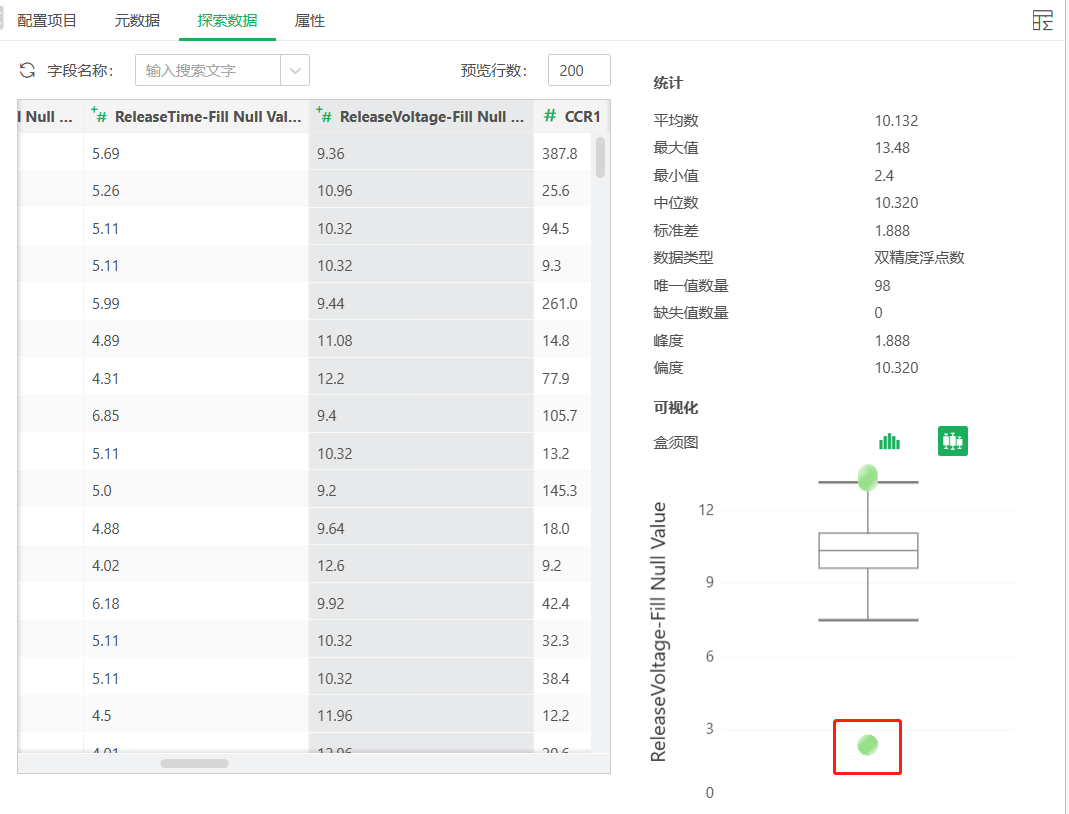
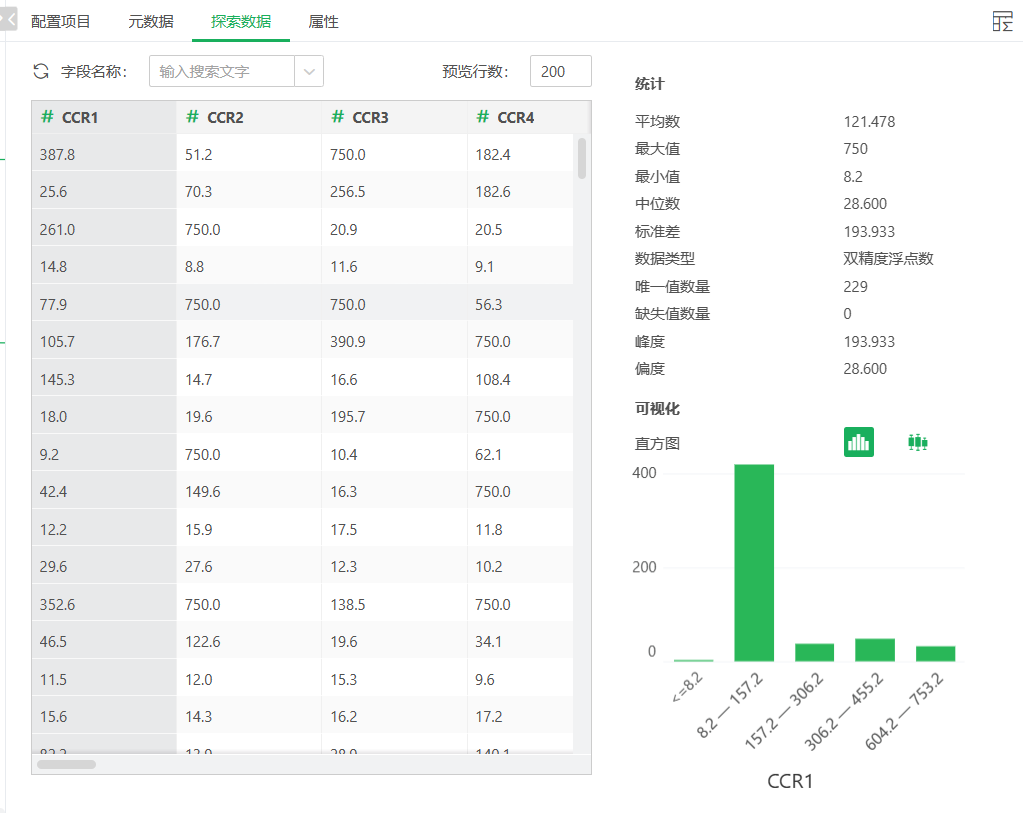
而后将继续使用探索数据中的盒须图,结合实际情况对可能异常值进行分析。最后,分析出各个接触电阻字段中的异常值750是对超量程电阻的特殊值处理,故而不做处理;其他OCR4、CR_Deviation-Fill Null Value、ReleaseVoltage-Fill Null Value、PullInVoltage-Fill Null Value字段中的异常值正常做过滤处理。

在之后,我们发现部分字段存在数据倾斜问题。对存在数据倾斜的字段,我们可以使用log函数处理。
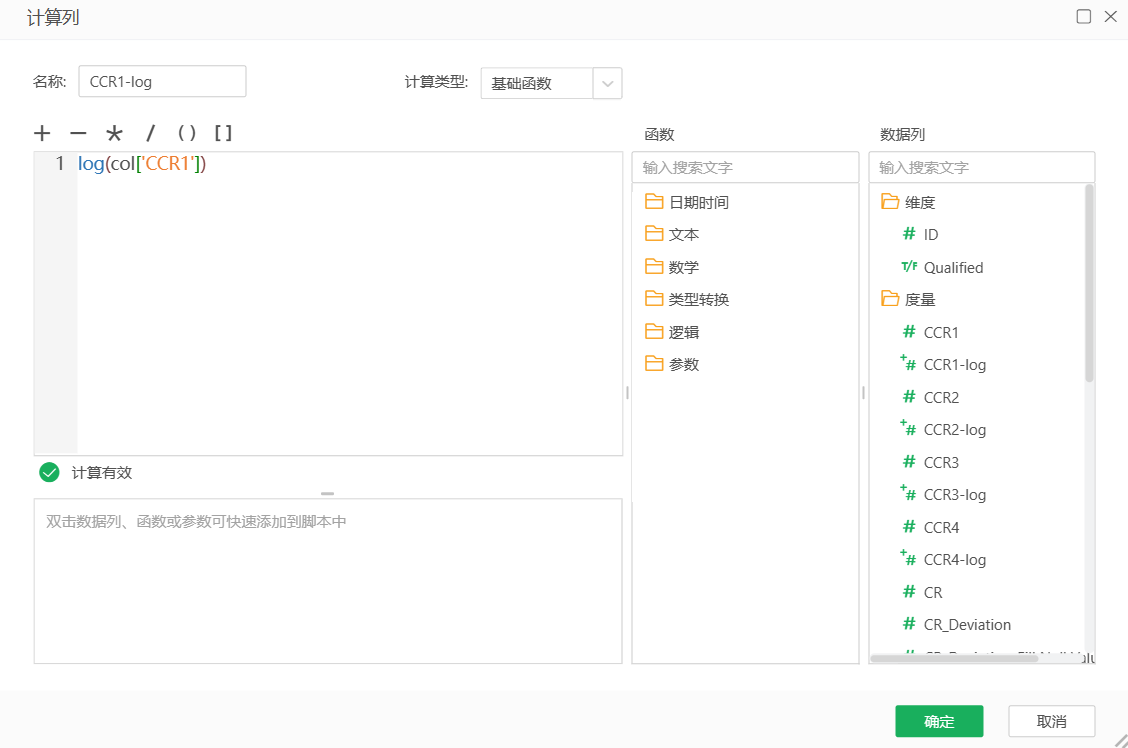
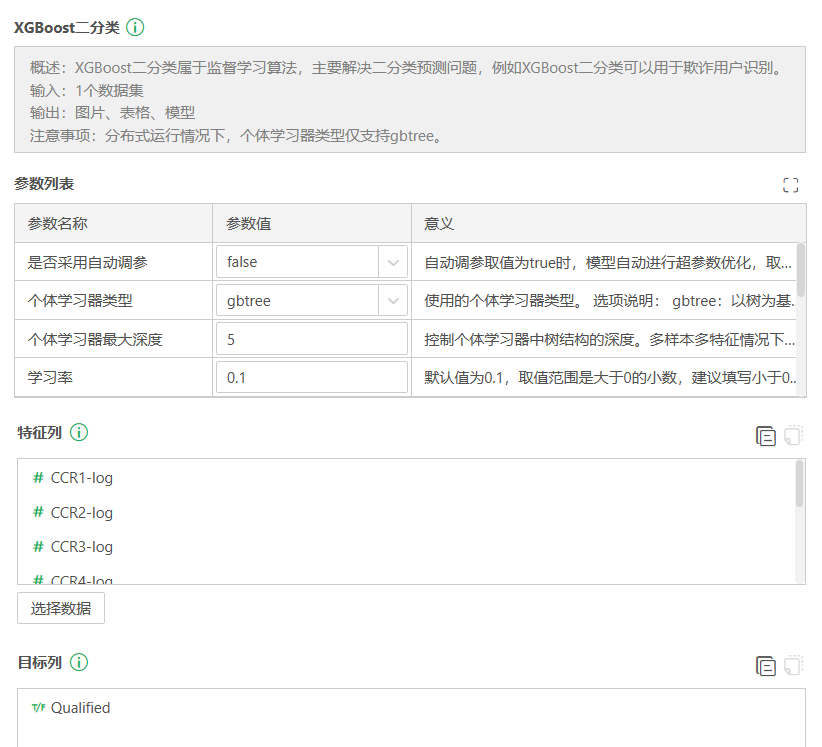
本案例算法节点的参数配置相比默认参数,主要调整了个体学习器数量,从默认的100提升为120。这是考虑到特征数较多,适当增加复杂度,但不宜增加过高,在样本数不高的情况下过高容易导致过拟合。这个超参数具体的调整可以参考训练结果图片中的算法迭代收敛曲线。注意将正例标签设置为目标列中的值—true。其他参数信息请查阅参数列表中的意义栏。
在进行模型的特征列选择过程中,最终选择的字段如下。
字段名称 |
字段描述 |
数据类型 |
|---|---|---|
CCR1-log |
原字段基础上进行了log函数计算 |
数值型 |
CCR2-log |
同上 |
|
CCR3-log |
||
CCR4-log |
||
OCR1-log |
||
OCR2-log |
||
OCR3-log |
||
OCR4-log |
||
CCR4 |
||
CR |
原字段基础上过滤了异常值 |
|
CR_Deviation-Fill Null Value-log |
原字段基础上用中位数填补了缺失值,过滤了异常值,进行了log函数计算 |
|
ReleaseBounce-Fill Null Value |
原字段基础上用中位数填补了缺失值 |
|
ReleaseTime-Fill Null Value |
原字段基础上用中位数填补了缺失值 |
|
ReleaseVoltage-Fill Null Value-log |
原字段基础上用中位数填补了缺失值,过滤了异常值,进行了log函数计算 |
|
PullInBounce-Fill Null Value |
原字段基础上用中位数填补了缺失值 |
|
PullInTime-Fill Null Value |
原字段基础上用中位数填补了缺失值 |
|
PullInVoltage-Fill Null Value-log |
原字段基础上用中位数填补了缺失值,过滤了异常值,进行了log函数计算 |
目标列选择是否合格,至此,参数配置和字段选择完成。
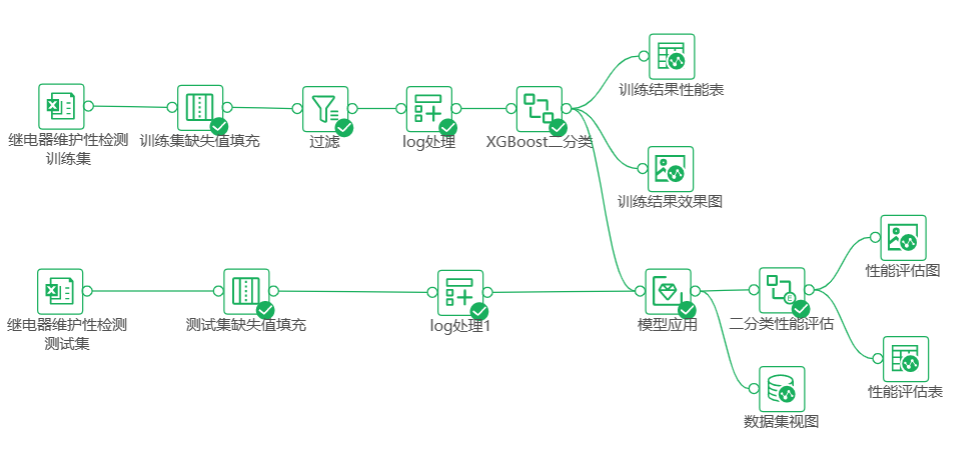
将对训练集的预处理(除了异常值处理)的逻辑复制到测试集后面,将结果和XGBoost二分类节点后连接模型应用节点,此流程的意思为将训练完成的模型用于测试集。模型应用节点的自变量选择和模型的特征列一致(可以直接点击特征列旁边的复制按钮,再点击自变量旁边的粘贴按钮)。因变量选择时,需要新建变量,命名为predict。

模型应用后接二分类性能评估,用各种指标比较真实值和预测值的差距,predict_Prob字段为模型应用运行后自动生成的字段。该节点参数中正例标签和算法算子一致,设定为true。

XGBoost二分类节点后可接图片视图和表格视图,模型应用后可接数据集视图,二分类性能评估后可接图片视图和表格视图,最终模型训练与评估部分整体流程如下图。
5.结果说明
1.训练集和验证集上的性能指标:准确率、召回率、F1-score、标签对应样本数。其中准确率、召回率、F1-score的取值范围为[0,1],当数值越接近1,说明模型表现越好。

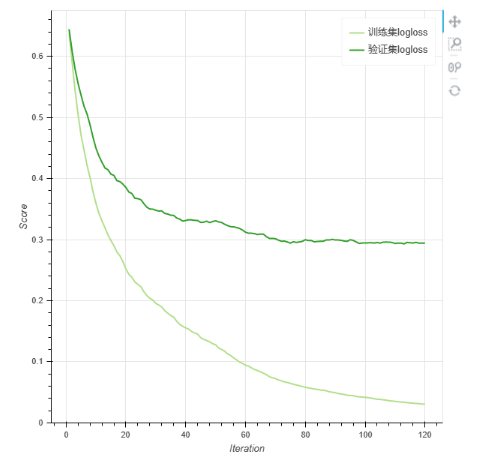
2.算法迭代收敛曲线:观察模型在训练迭代中,在训练集和验证集上的logloss变化,如果验证集logloss在训练末期没有明显回升,则判断没有过拟合。如果训练集logloss在训练末期已经没有了下降趋势,则判断没有欠拟合。
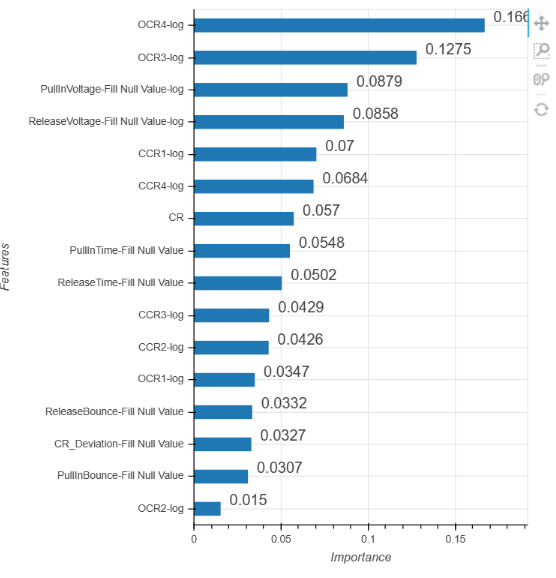
3.特征重要性:可以估计各个自变量(特征)在分类过程中的贡献度,展现了每个自变量(特征)对于模型的影响大小,并对它们进行降序排列,使得研究者能够直观便捷的了解每个特征在模型中发挥作用的大小。
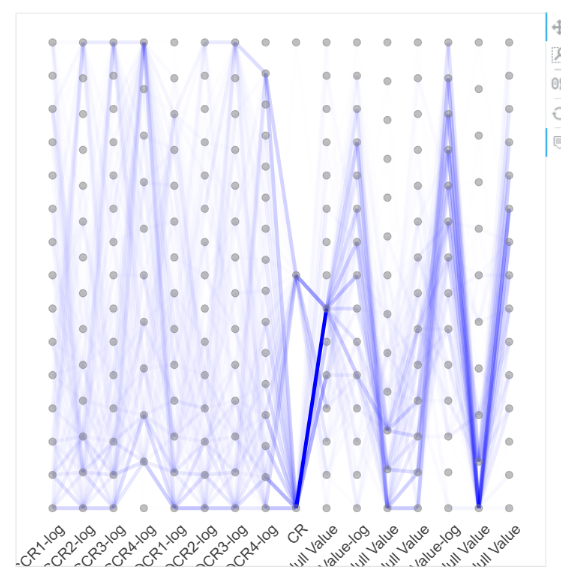
4.平行坐标图:平行坐标图是一种通用的可视化方法,能够用于探索高维或多元数据的分布情况。颜色的深浅代表了数据分布情况,颜色越深代表该区间上的数据分布越多。
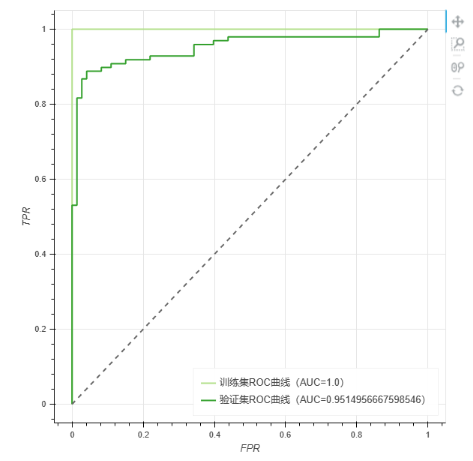
5.ROC曲线:能反映模型在选取不同阈值的时候其敏感性(sensitivity, FPR)和其精确性(specificity, TPR)的趋势走向,ROC曲线有一个巨大的优势就是,当正负样本的分布发生变化时,其形状能够基本保持不变,而P-R曲线的形状一般会发生剧烈的变化,因此该评估指标能降低不同测试集带来的干扰,更加客观的衡量模型本身的性能。
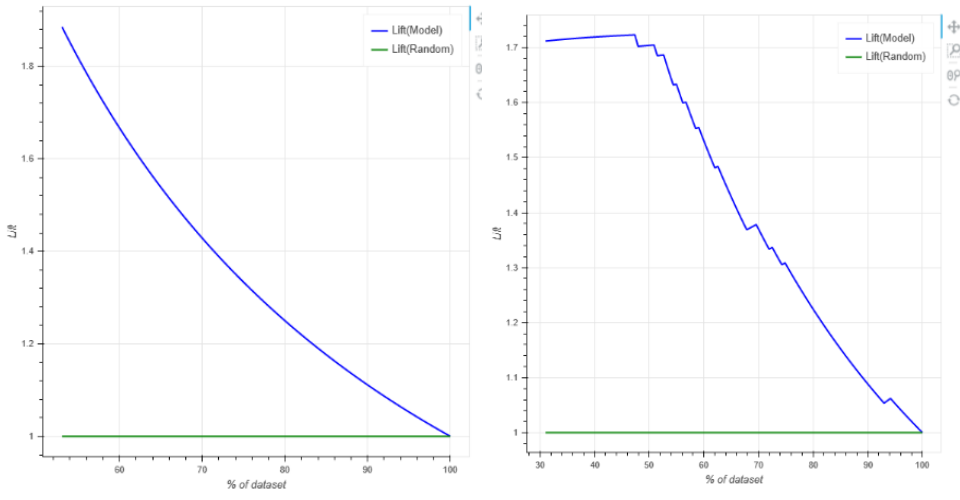
6.Lift曲线:与ROC曲线不同的是lift考虑分类器的准确性,强调投入与产出比,是表示与不利用模型相比,模型的预测能力“变好”了多少的工具,表示“运用该模型”与“未运用该模型(即随机选择)”所得结果的比值,Lift应该一直大于1,且Lift(提升指数)越大,模型预测效果越好。
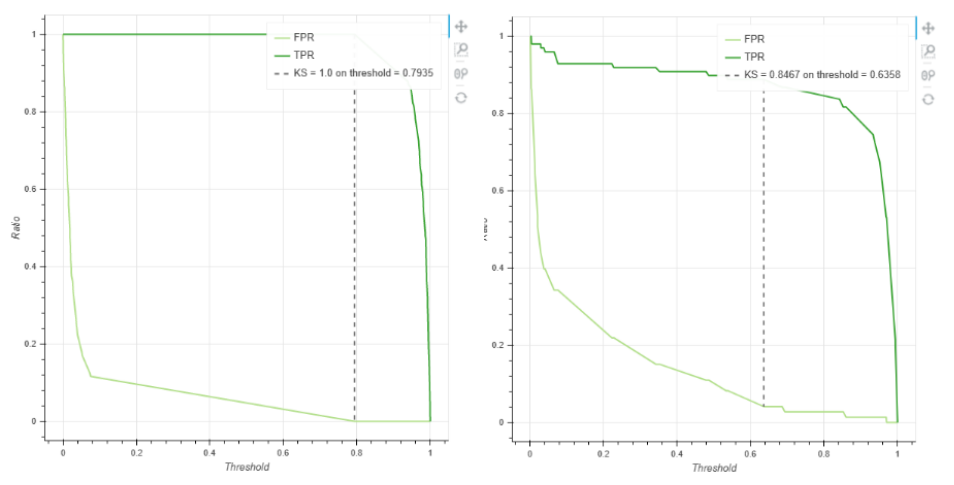
7.KS曲线:KS 曲线之间的最大间隔距离为KS值,KS值越大表示模型的区分能力越强。一般KS值>0.2,代表模型的区分能力较好。
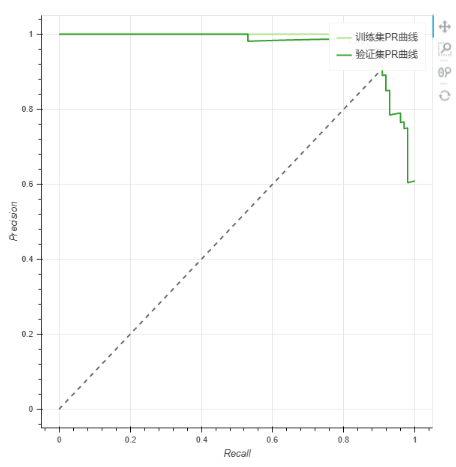
8.PR曲线:如果一条曲线完全“包住”另一条曲线,则前者性能优于另一条曲线。被经过原点且斜率为1的直线经过的两点被称为平衡点(BEP),平衡点的取值越大,代表效果越优。
9.模型在测试集上的表现:以下指标同训练集和验证集上的性能指标,除“标签对应样本数”外的三个指标,指标越接近1越好。
