1.背景介绍
零售店管理者最为关注的就是零售店的销量,了解当年的销量情况,可以为接下来的发展方案进行准备。为快人一步地把控市场、执行策略,需要根据现有的数据来预测未来的销量情况和走势,以提前应对风险和制定战略方案。该案例中某连锁药店在7个欧洲国家经营着3000多家药店。目前,门店经理的任务是提前至多六周预测每日销售额。商店的销售情况受到许多因素的影响,包括促销、竞争、学校和国家假日、季节性和地区。由于成千上万的经理根据他们独特的情况来预测销售,结果的准确性可能会有很大的差异。
2.数据说明
药店共有两张表,分别为各个商店的信息数据和从所有商店汇总来的历史销售数据。
字段名称 |
字段描述 |
数据类型 |
|---|---|---|
Store |
商店的唯一Id。共1115个。 |
数值型 |
Assortment |
描述商店分类级别:a = basic,b = extra,c = extended |
|
CompetitionDistance |
到最近的竞争对手商店的距离(以米为单位) |
|
CompetitionOpenSinceMonth |
最近的竞争对手商店的(大概)开店月份 |
|
CompetitionOpenSinceYear |
最近的竞争对手商店的(大概)开店年份 |
|
Promo2SinceWeek |
该店开始参与促销活动的日历周 |
|
Promo2SinceYear |
该店开始参与促销活动的年份 |
|
Promo2 |
商店有无持续不断的促销活动 |
布尔型 |
StoreType |
区分4种不同的商店模式:a,b,c,d。其中a(54%),d(31%),其他(15%) |
文本型 |
Assortment |
描述商店分类级别:a = basic,b = extra,c = extended |
|
PromoInterval |
连续时间间隔的促销活动,活动重新启动的月份。如“2月、5月、8月、11月”是指每轮活动开始于每年的2月、5月、8月、11月 |
字段名称 |
字段描述 |
数据类型 |
|---|---|---|
Store |
商店的唯一Id。共1115个。 |
数值型 |
DayOfWeek |
一周的周几 |
|
Date |
日期 |
|
Sales |
当天的营业额 |
|
Open |
商店当天是否营业 |
布尔型 |
Promo |
商店当天是否有促销活动 |
|
SchoolHoliday |
是否受公立学校停课影响 |
|
StateHoliday |
是否国家假日(一般情况,除少数例外,所有商店在国定假日都关门)。 a =公众假期,b =复活节假期,c =圣诞节,0 =无 |
文本型 |
3.方案介绍
首先,根据项目背景介绍,整个问题是一个预测商店销售额的问题,可以将其抽象为一个回归问题,销售数据中的Sales字段,就是建模采用的目标值。将销售数据中1115个商店的最后48天销售数据单独分出作为测试集,其他数据为训练集。
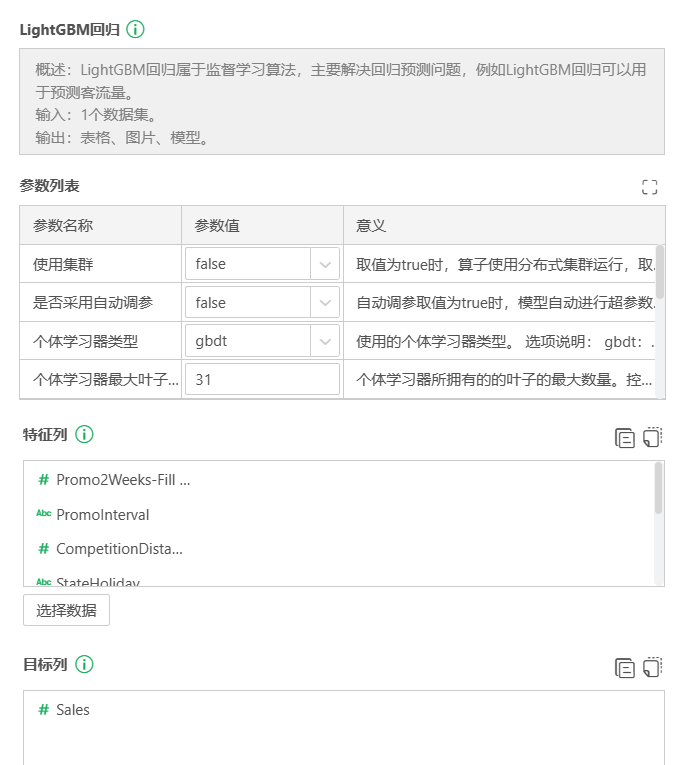
LightGBM在实际工程项目中,其对类别型特征的处理非常适合一些金融数据或多因素影响的销量数据建模场景,故而本方案选择使用LightGBM进行回归任务。
4.方案分析
首先进行数据预处理,包括填补缺失数据、排除异常数据、转换数据形式等。
销售数据中,由探索数据中对字段的统计进行分析,发现CompetitionDistance字段存在3个缺失值,且各个门店CompetitionDistance差别较大(最小20,最大75860),故而使用中位数填充。又由下方的数据分布直方图可知CompetitionDistance存在数据倾斜,需要进行对数变换。
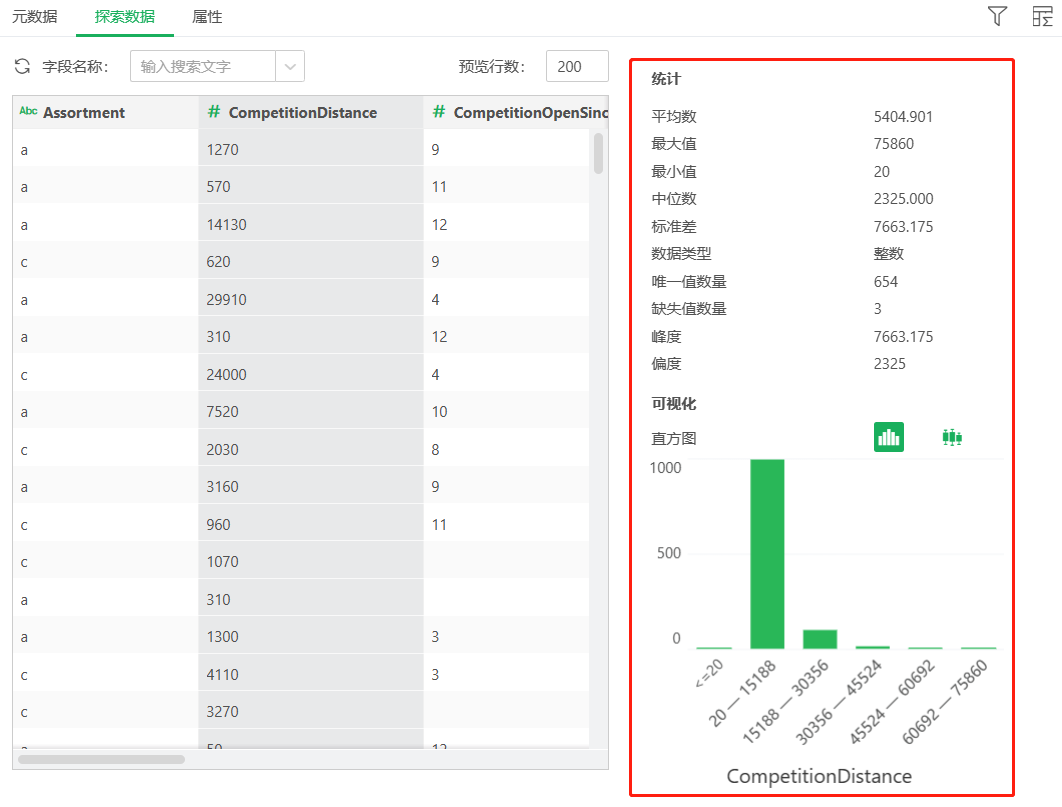
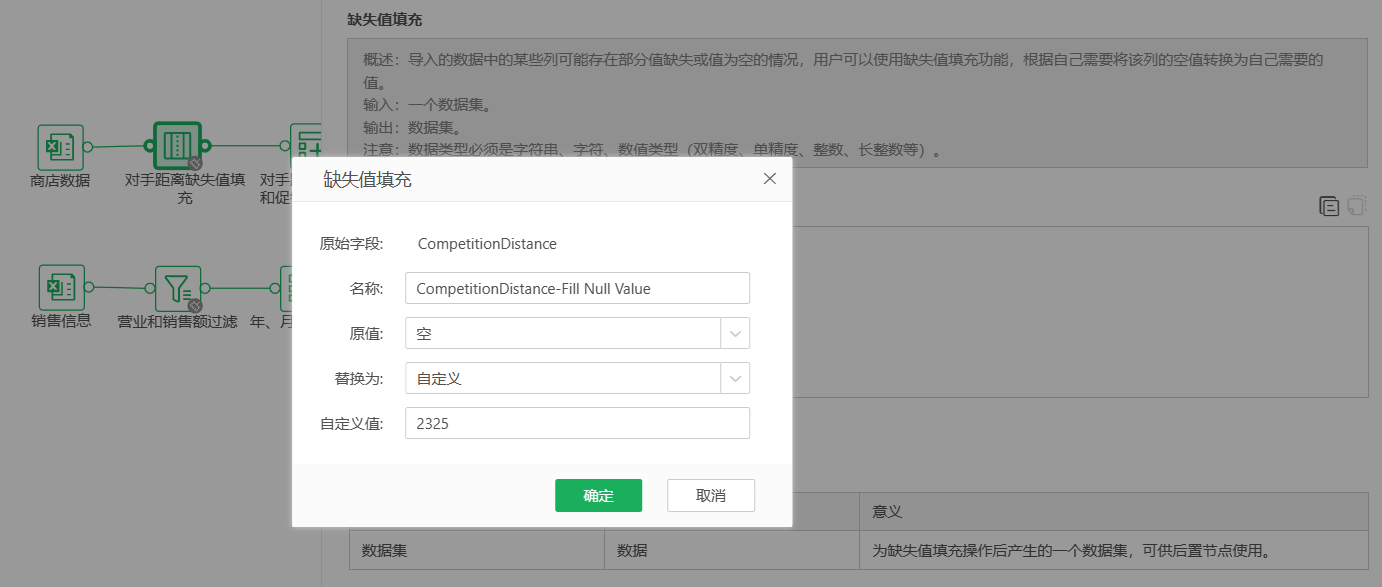
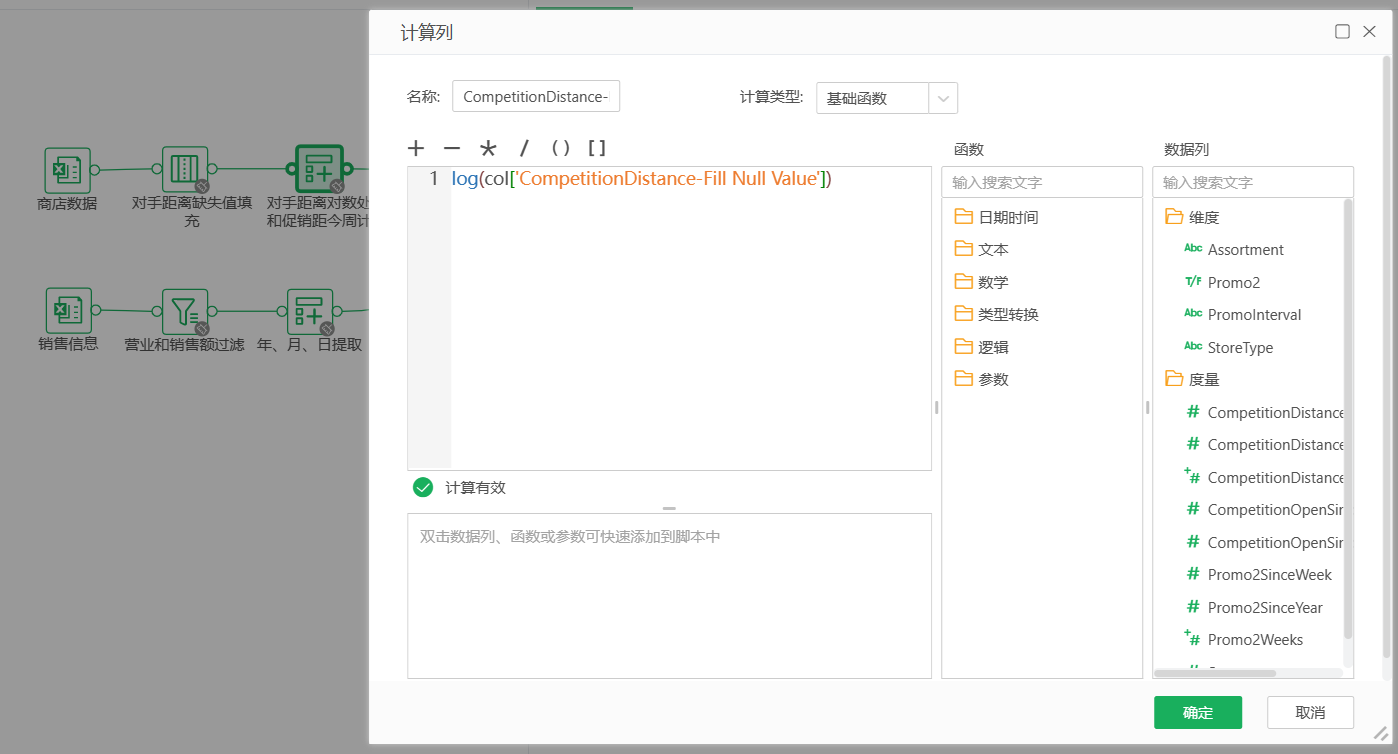
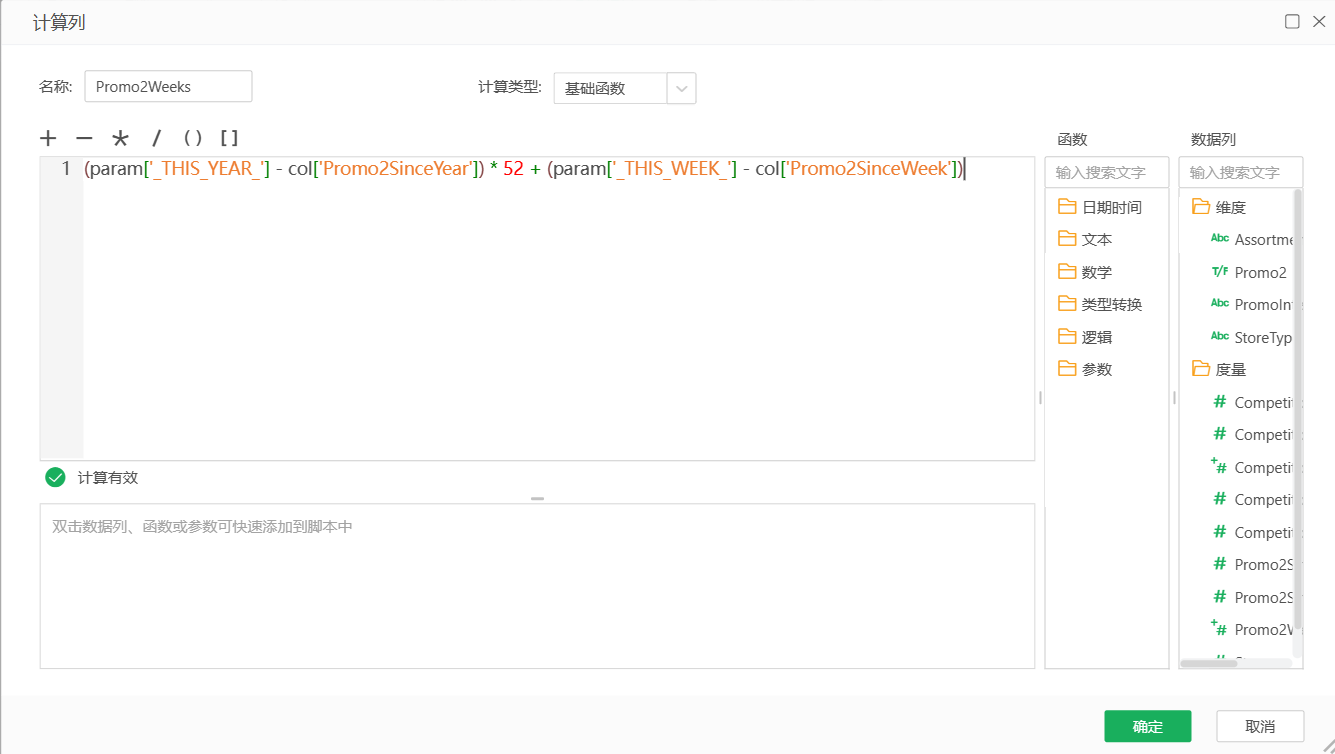
此外,CompetitionOpenSinceMonth和CompetitionOpenSinceYear字段也存在缺失值,但规则不好制定,后经分析对销量几乎无影响,故而删除两列。Promo2SinceYear,Promo2SinceWeek,PromoInterval三个字段都有544个缺失值,但和Promo2字段的缺失情况一致,说明不属于缺失数据。将Promo2SinceYear和Promo2SinceWeek字段的信息合并处理为Promo2Weeks字段,意为促销距今有多少周,之后缺失值置零。下图为新建Promo2Weeks计算列的操作,缺失值置零略。
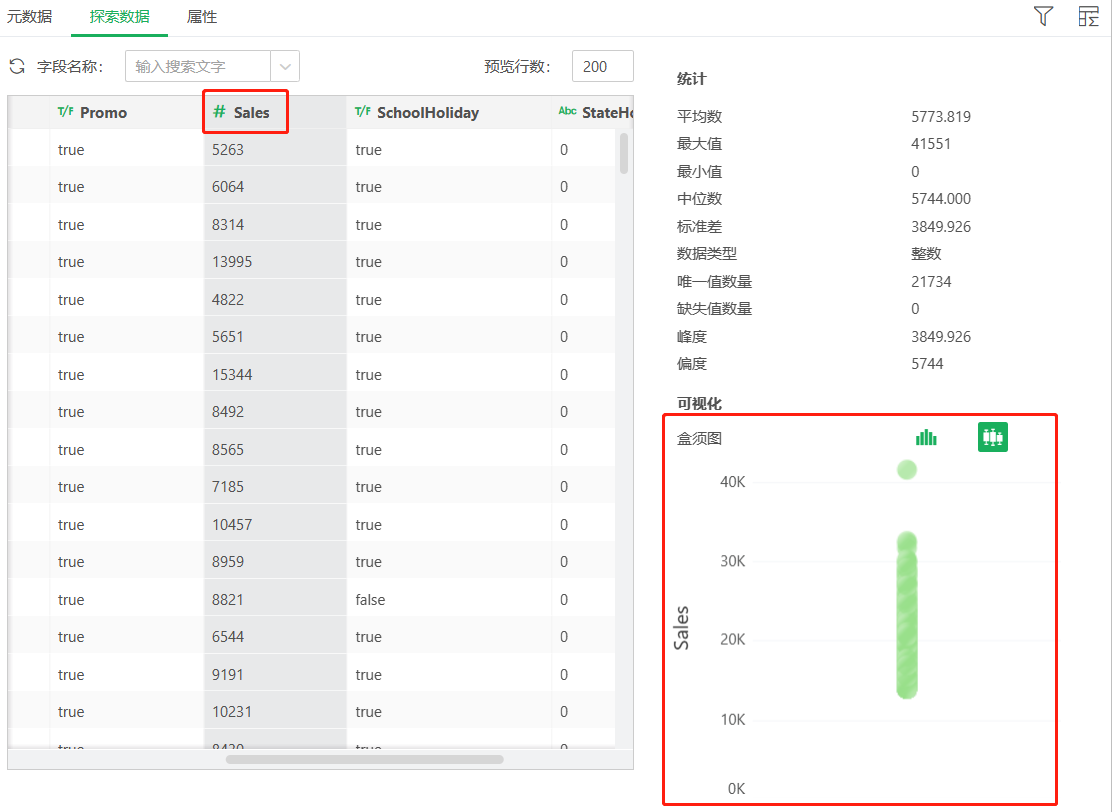
观察销售数据的Sales字段,从盒须图发现存在大于40K,明显偏离其他数据的值。
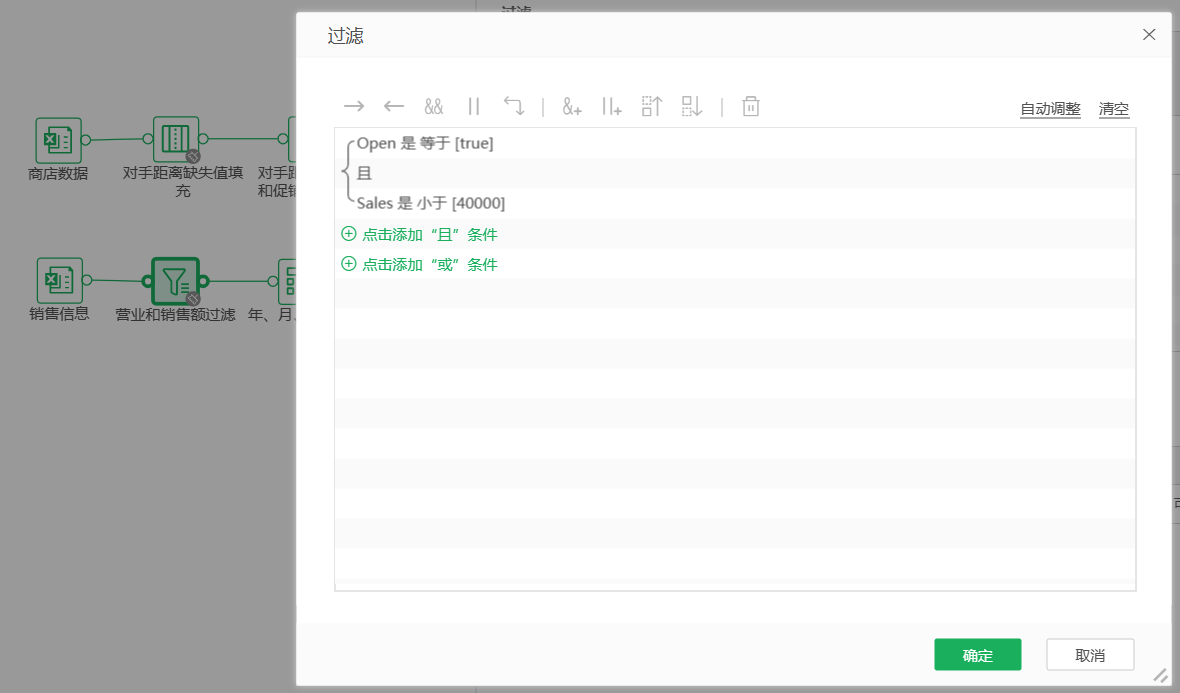
可以使用过滤销售额大于40000查看该条数据,发现并无促销(此过程略),判断为异常值,使用过滤将该条数据排除,另外不需要未营业时的商店销售数据,使用过滤将Open字段为false的数据过滤。
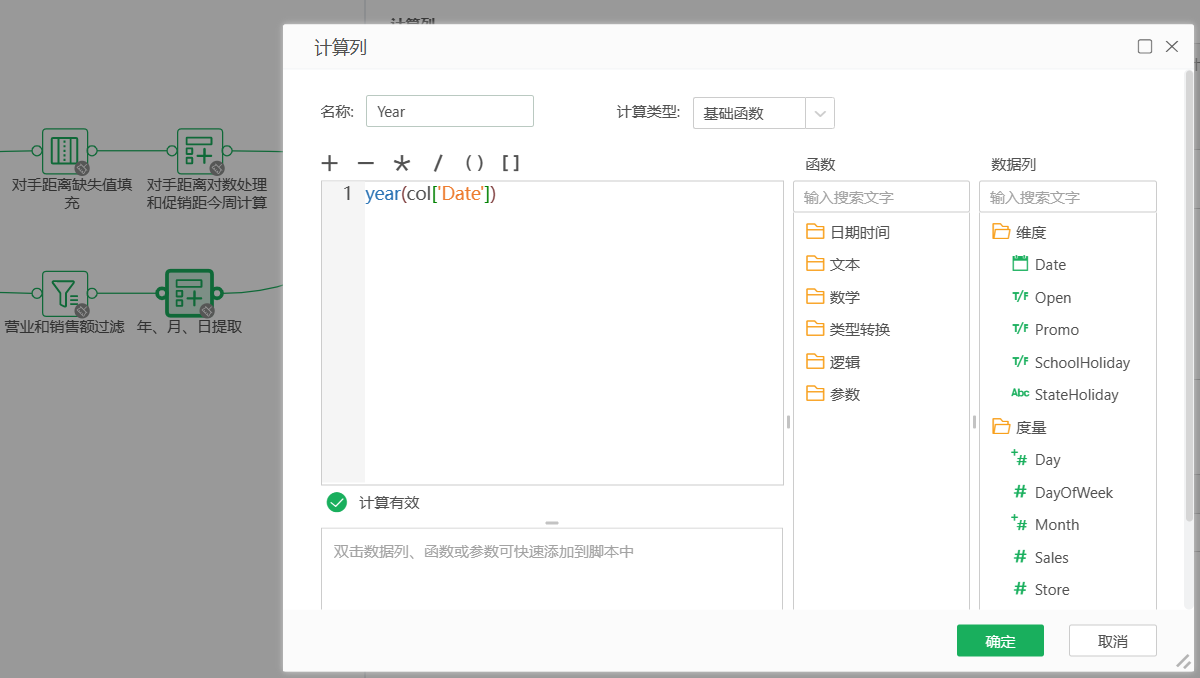
接下来从日期特征提取年、月、日特征,下图为提取年特征,提取月、日的过程略过。
至此,我们将销售信息和商店信息使用联接节点进行合并,首先选择两个节点的数据作为数据来源,联接方式选择左侧连接,选择完成后点击右侧加号。
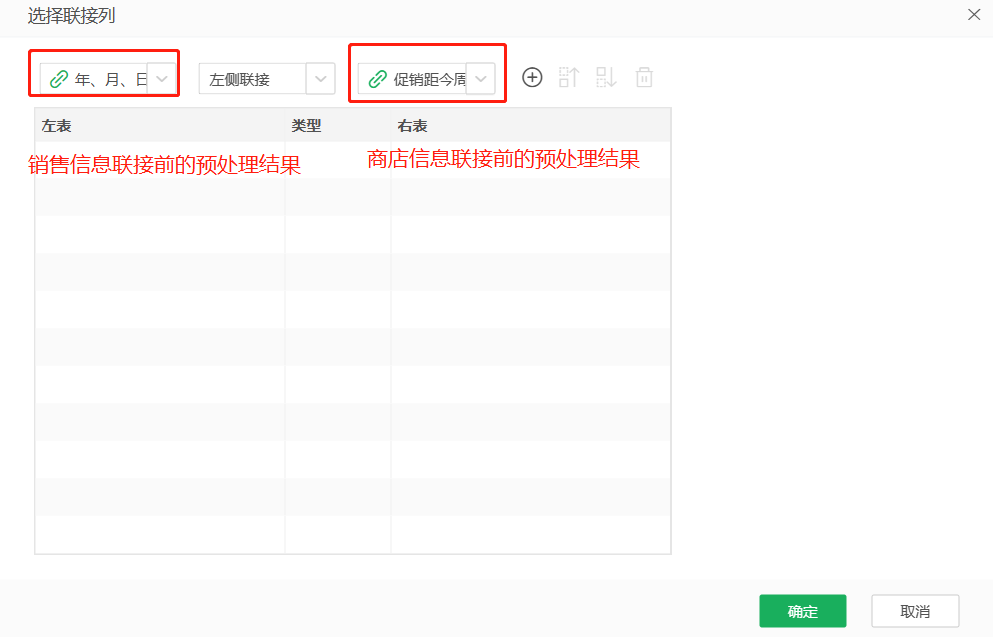
之后,添加联接列,也就是两个表的Store字段。
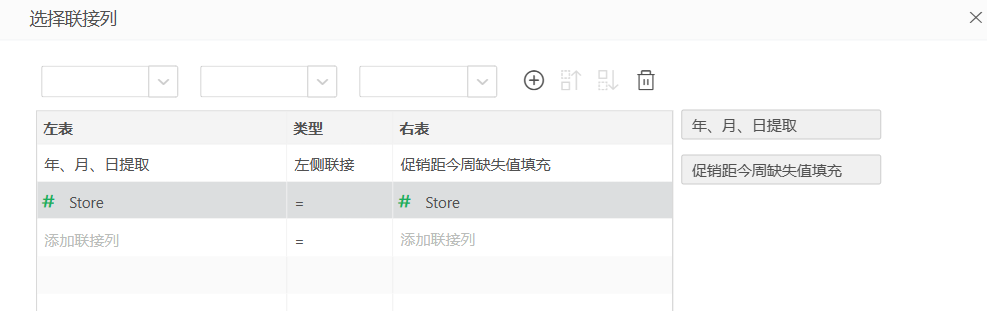
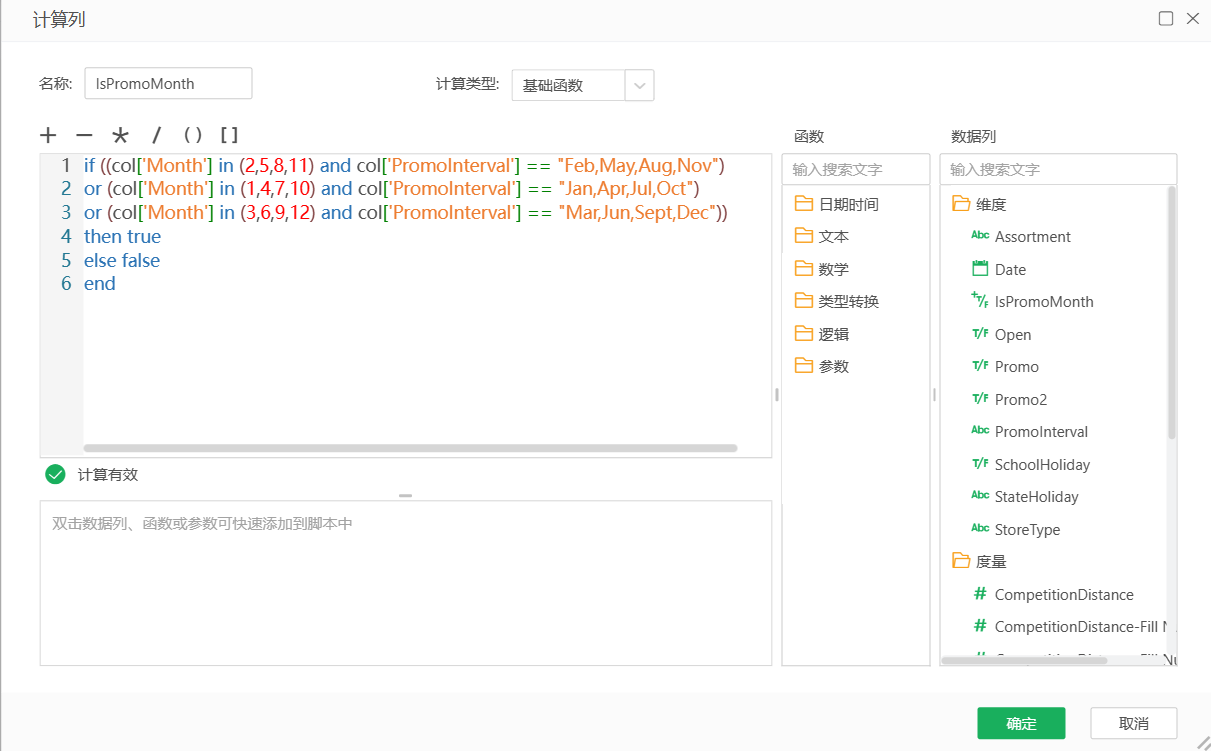
结合商店信息中的PromoInterval字段与销售信息中的Month字段,判断销售记录是否在促销期间发生,新字段命名为IsPromoMonth。
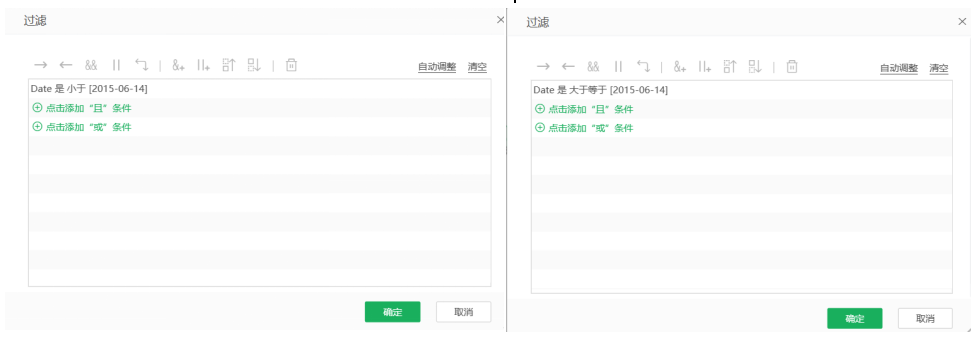
最后,使用过滤,将最后48天(2015年6月14日到7月31日)的数据划分为测试集,其他为训练集,左侧图片为训练集过滤,右侧图片为测试集过滤。
数据预处理流程结束,目前整体流程图如下。
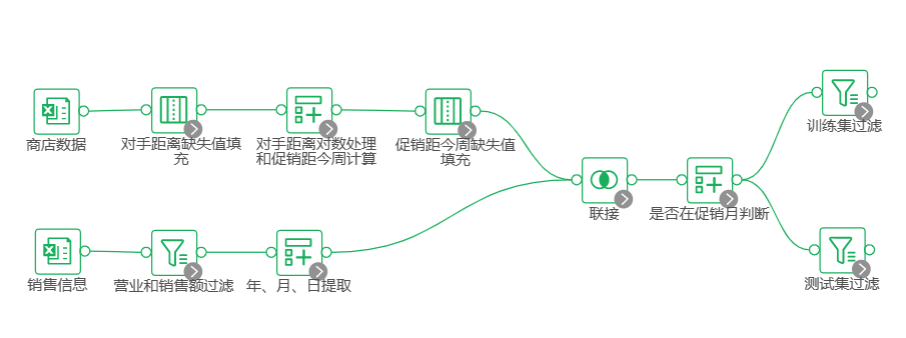
数据预处理并分割训练集测试集后,在训练集过滤节点后接LightGBM回归节点。本案例算法节点的参数配置相比默认参数,主要调整了个体学习器数量,从默认的100提升为1000。这是考虑到样本量和特征数较多,需更复杂的模型。其他参数信息请查阅参数列表中的意义栏。
在进行模型的特征列选择过程中,经过一些训练,筛除了没有明显影响的无长期促销字段,最终选择的字段如下。
字段名称 |
字段描述 |
数据类型 |
|---|---|---|
Promo2Weeks-Fill Null Value |
由Promo2SinceYear和Promo2SinceWeek信息汇总后,用0填补缺失值得来 |
数值型 |
CompetitionDistance- Fill Null Value-log |
CompetitionDistance用中位数填补缺失值后,取对数得来 |
|
Year |
销售记录年份,由Date字段提取而来 |
|
Month |
销售记录月份,由Date字段提取而来 |
|
Day |
销售记录日,由Date字段提取而来 |
|
DayOfWeek |
同原数据 |
|
PromoInterval |
同原数据 |
文本型 |
StateHoliday |
同原数据 |
|
Assortment |
同原数据 |
|
StoreType |
同原数据 |
|
IsPromoMonth |
由PromoInterval和Month信息汇总得来 |
布尔型 |
Promo |
同原数据 |
布尔型 |
SchoolHoliday |
同原数据 |
布尔型 |
目标列选择Sales,参数配置和字段选择完成。
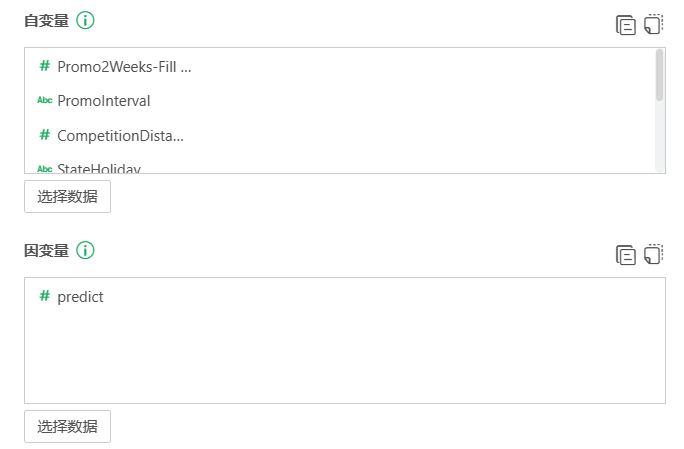
测试集过滤和LightGBM回归节点后接模型应用节点,此流程是为了将训练完成的模型用于测试集。模型应用节点的自变量选择和模型的特征列一致(可以直接点击特征列旁边的复制按钮,再点击自变量旁边的粘贴按钮)。因变量选择时,需要新建变量,命名为predict。
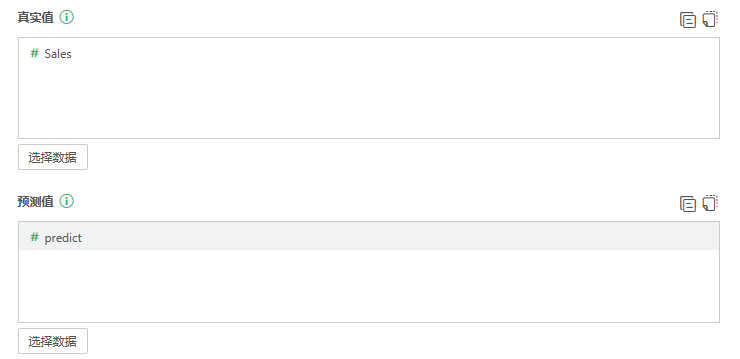
模型应用后接回归性能评估,用各种指标比较真实值和预测值的差距。
LightGBM回归节点后可接图片视图和表格视图,模型应用后可接数据集视图,回归性能评估后可接图片视图和表格视图,最终模型训练与评估部分整体流程如下图。
5.结果说明
当前项目的工作流,LightGBM回归算子将输出模型性能指标、时序分析预测结果图和数据集视图。
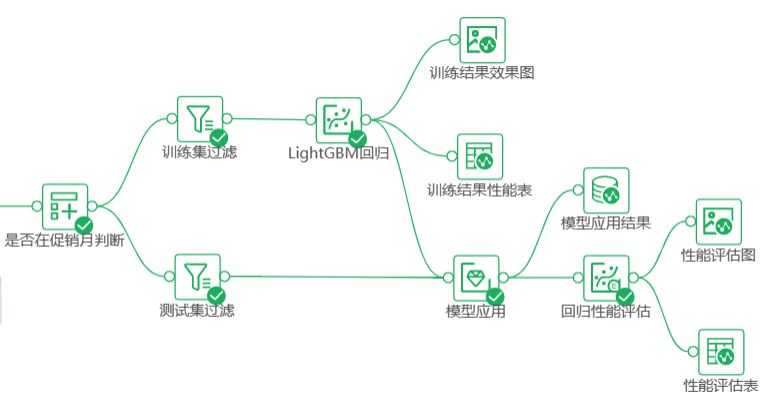
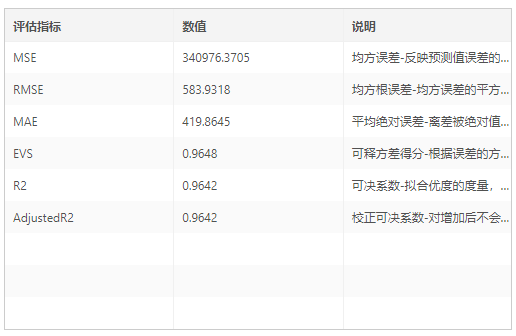
1.模型性能指标:训练集上的性能指标:MSE、RMSE、MAE、EVS、R2、Adjusted R2。其中MSE、RMSE、MAE是各种计算方式下的预测损失值,值越小越好;EVS是方差得分,值越接近1越好;R2和Adjusted R2都是评价不同量纲下模型效果好坏的指标,值越接近1越好。
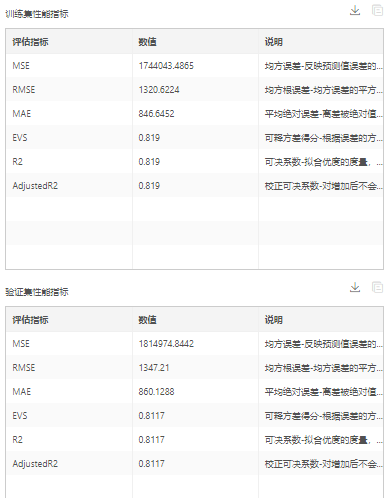
2.算法迭代收敛曲线:观察模型在训练迭代中,在训练集和验证集上的L2变化,如果训验证集L2在训练末期没有明显回升,则判断没有过拟合。如果训练集L2在训练末期已经没有了下降趋势,则判断没有欠拟合。
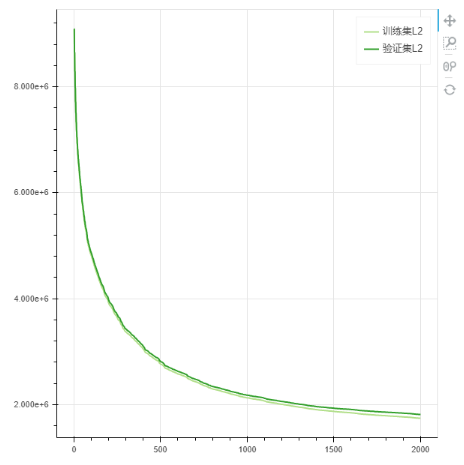
3.特征重要性:特征对预测结果影响的一种量化,并进行了排序。
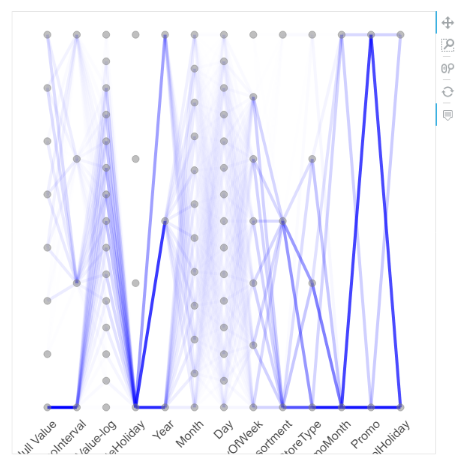
4.平行坐标图:对多特征数据分布的一种可视化。
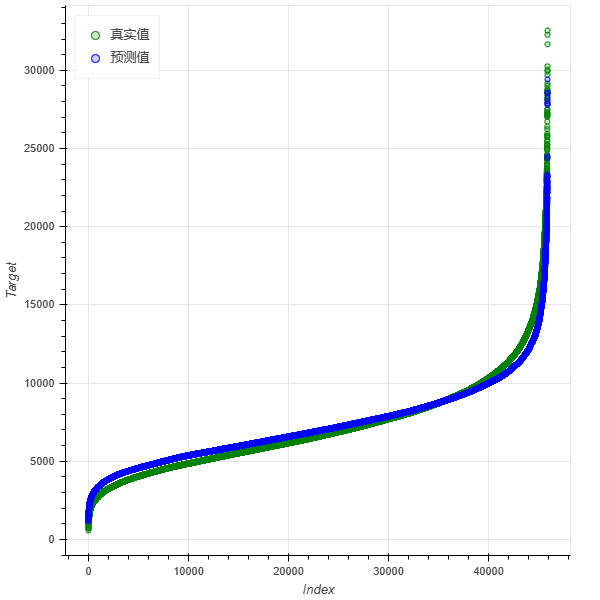
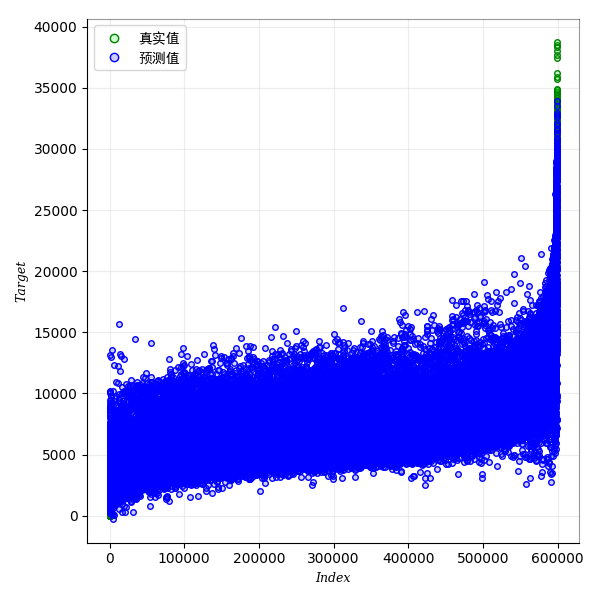
5.真实值与预测值对比(训练集):模型迭代完后,最终在训练集上进行预测的结果和真实值对比的图。
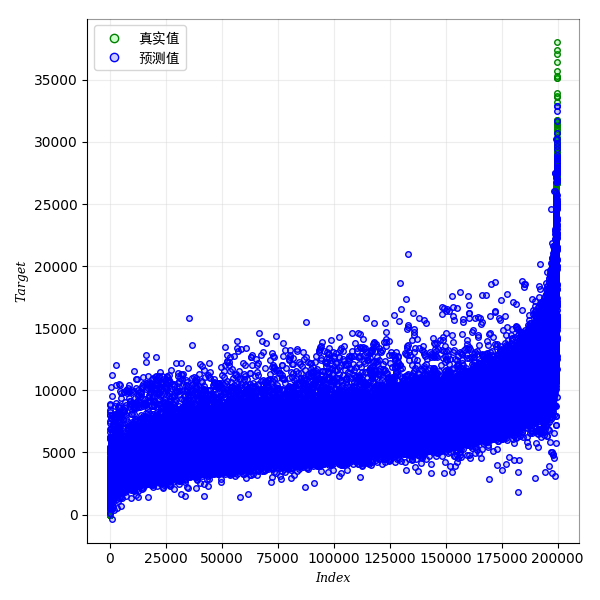
6.真实值与预测值对比(验证集):模型迭代完后,最终在验证集上进行预测的结果和真实值对比的图。
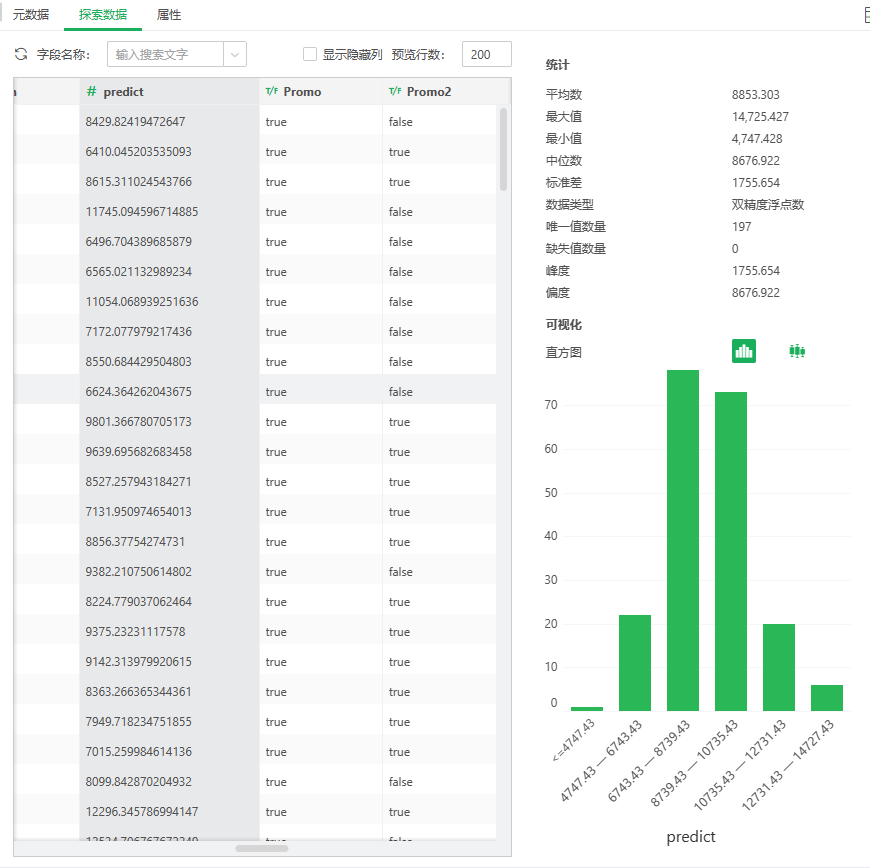
7.模型应用结果:模型在测试集上进行预测得到的结果数据集。
8.测试集性能评估表:模型在测试集上的性能指标,指标含义和训练集验证集上相同,但衡量了模型应用于新数据时的表现。
9.真实值与预测值对比:模型在测试集上预测的销售额和测试集中样本的实际销售额进行对比的图。