1.概述
XGBoost多分类属于监督学习算法,主要解决多分类预测问题。
➢例如:XGBoost多分类可以用于商品分类。
输入:1个数据集。
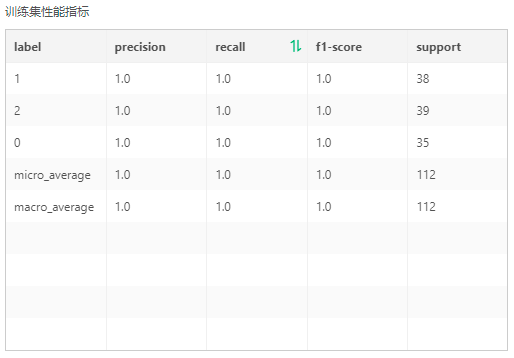
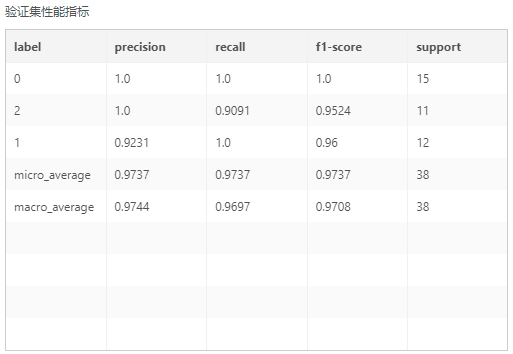
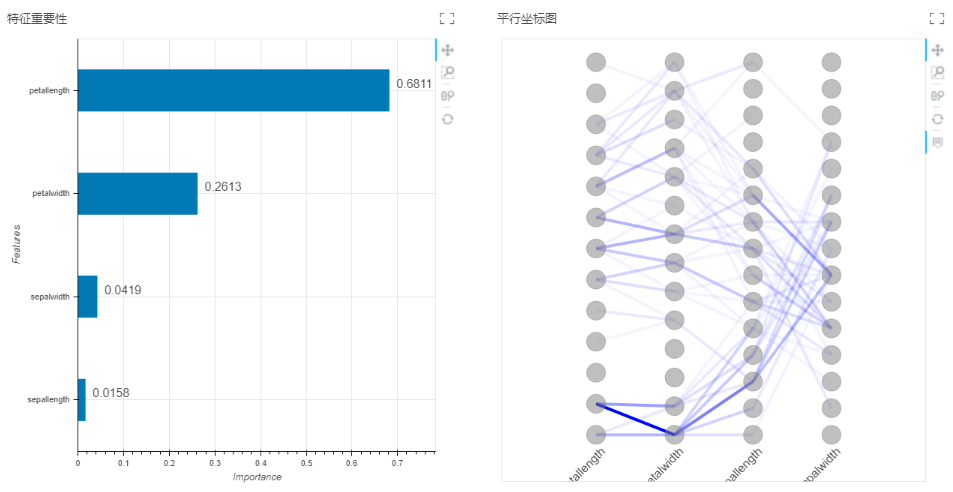
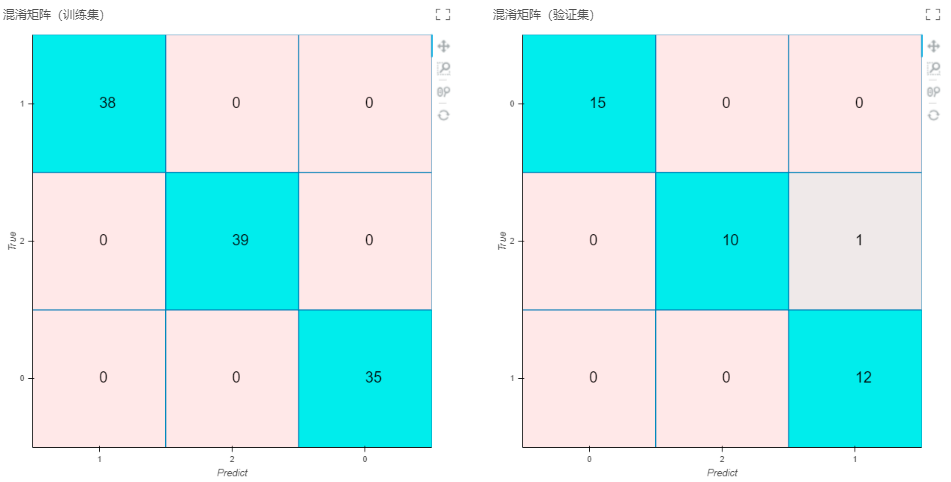
输出:模型、训练集性能指标(类别、准确率、召回率、F1-score、支持样本量)、验证集性能指标(准确率、召回率、F1-score、支持样本量)、混淆矩阵(验证集)、混淆矩阵(训练集)、平行坐标图、特征重要性。
2.配置方法
将XGBoost多分类节点添加到实验后,可通过右侧的“配置项目”页面,对XGBoost多分类节点进行设置。
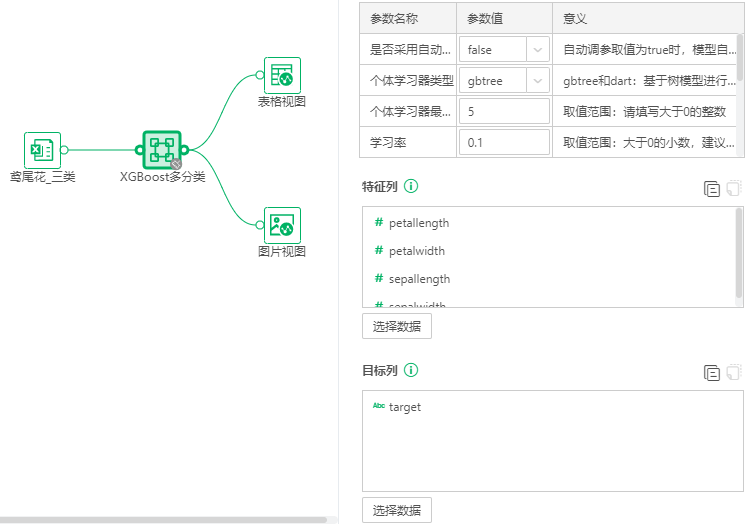
2.1参数列表
【自动调参】自动调参取值为true时,模型自动进行超参数优化,取值为false时,需要手动调参。
【个体学习器类型】gbtree和dart:基于树模型进行提升计算,gbliner:使用线性模型进行提升计算。
【个体学习器最大深度】控制个体学习器中数结构的深度,多样本多特征情况下需要限制最大深度,取值范围:请填写大于0的整数。
【学习率】取值范围:大于0的小数,建议填写小于0.5的小数。
【个体学习器数量】取值范围:大于0的整数。
【运算核心数】请填写大于等于-1的整数。-1代表使用所有核心。
【节点分裂最小损失下降值】取值范围:大于0的小数,建议填写小于0.5的小数。
【叶子节点最小权重之和】权重小于设定值,停止分裂。取值范围:请填写大于0的整数。
【最大权重增量步】每棵树允许的最大提升度。取值范围:请填写大于0的整数。
【训练样本采样比例】个体学习器训练时的样本采样比例,取值范围:请填写0-1之间的小数。
【个体学习器特征采样比例】个体学习器训练时的特征采样比例,取值范围:请填写0-1之间的小数。
【逐层采样比例】树构建每层分裂时特征采样比例,取值范围:请填写0-1之间的小数。
【L1惩罚项系数】防止过拟合参数。取值范围:请填写大于等于0的小数。
【L2惩罚项系数】防止过拟合参数。取值范围:请填写大于等于0的小数。
【随机种子】固定随机种子用于保证模型训练的结果可复现。当设置为0时,禁用随机种子。参数取值范围:请填写大于等于0的整数。
2.2选择变量
特征列:选择模型的特征字段,特征列至少选择一列。
目标列:选择模型的目标字段,目标列至少选择一列。
选择数据页面操作见插件节点>选择数据。
3.查看结果
可通过连接多视图节点查看结果或连接表格视图来查看性能指标,连接图片视图来查看特征重要性图、混淆矩阵和平行坐标图。配合保存为训练模型节点使用,可以将待预测的特征输入模型,进行预测计算。
其中准确率、召回率、F1-score的取值范围为[0,1],当数值越接近1,说明模型表现越好。
特征重要性展现了每个特征对于模型的影响大小,并对它们进行降序排列。
平行坐标图中颜色的深浅代表了数据分布情况,颜色越深代表该区间上的数据分布越多。