|
<< Click to Display Table of Contents >> Algorithm |
|
|
<< Click to Display Table of Contents >> Algorithm |
|
❖Algorithm
This algorithm refers to Y-AI's plug-in operators, including five types of operators: classification, association rules, regression, clustering, and time series. Among them, classification includes three classification algorithms: decision tree multi-classification, decision tree two classification and logistic regression; association rules have built-in FP-Growth algorithm, regression includes decision tree regression and linear regression two regression algorithms; clustering has built-in Kmeans aggregation Class algorithm; Holt-Winters algorithm is built in time series.
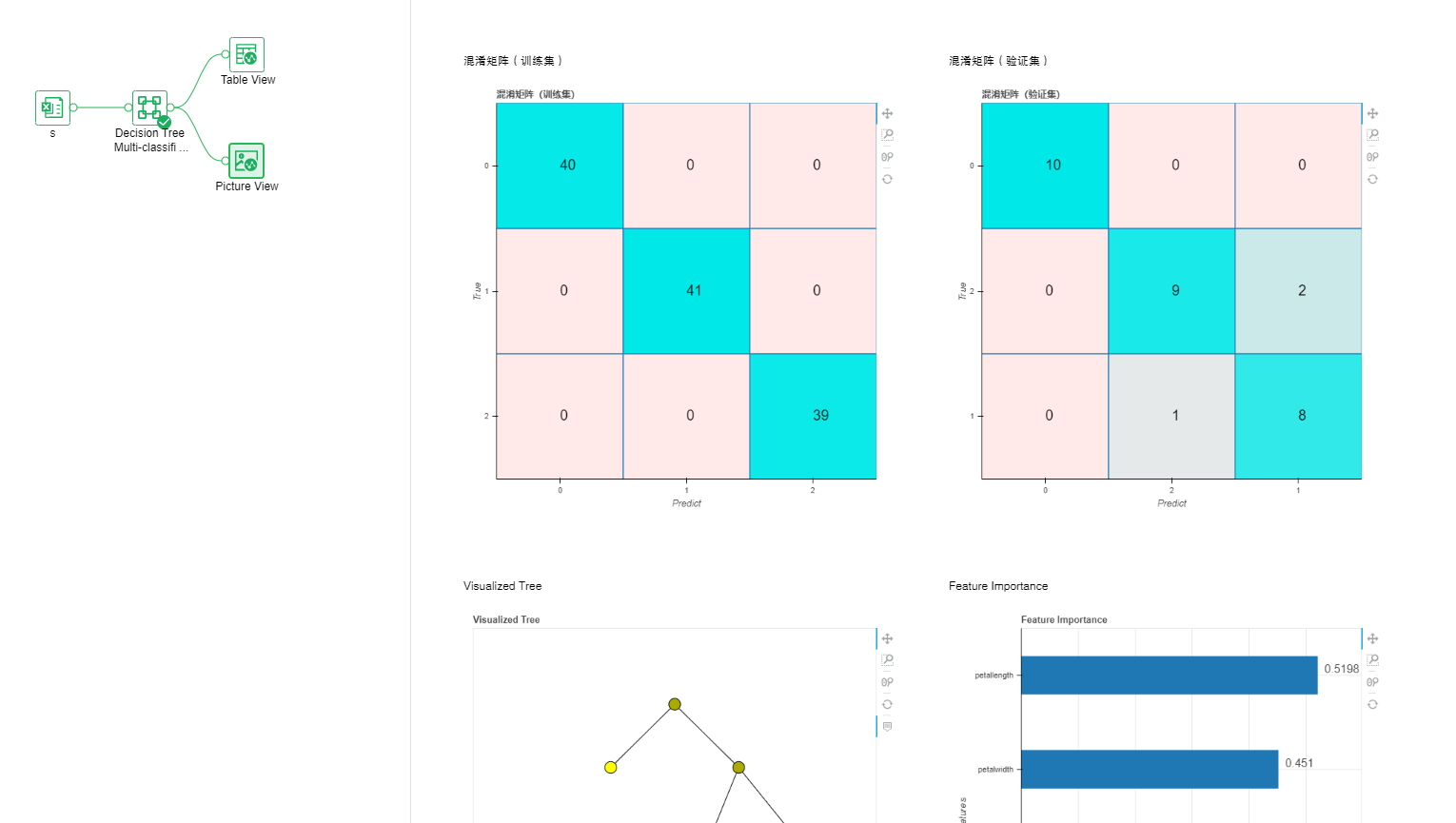
•Classification-Decision Tree Multi-classification
Decision tree classification, the use of decision tree algorithm for classification model training, suitable for more than two target columns.
Parameter list: Model training is carried out by setting various parameters of the decision tree classification algorithm to achieve the optimal classification effect.
Output list: model, performance index, confusion matrix, PMML file.
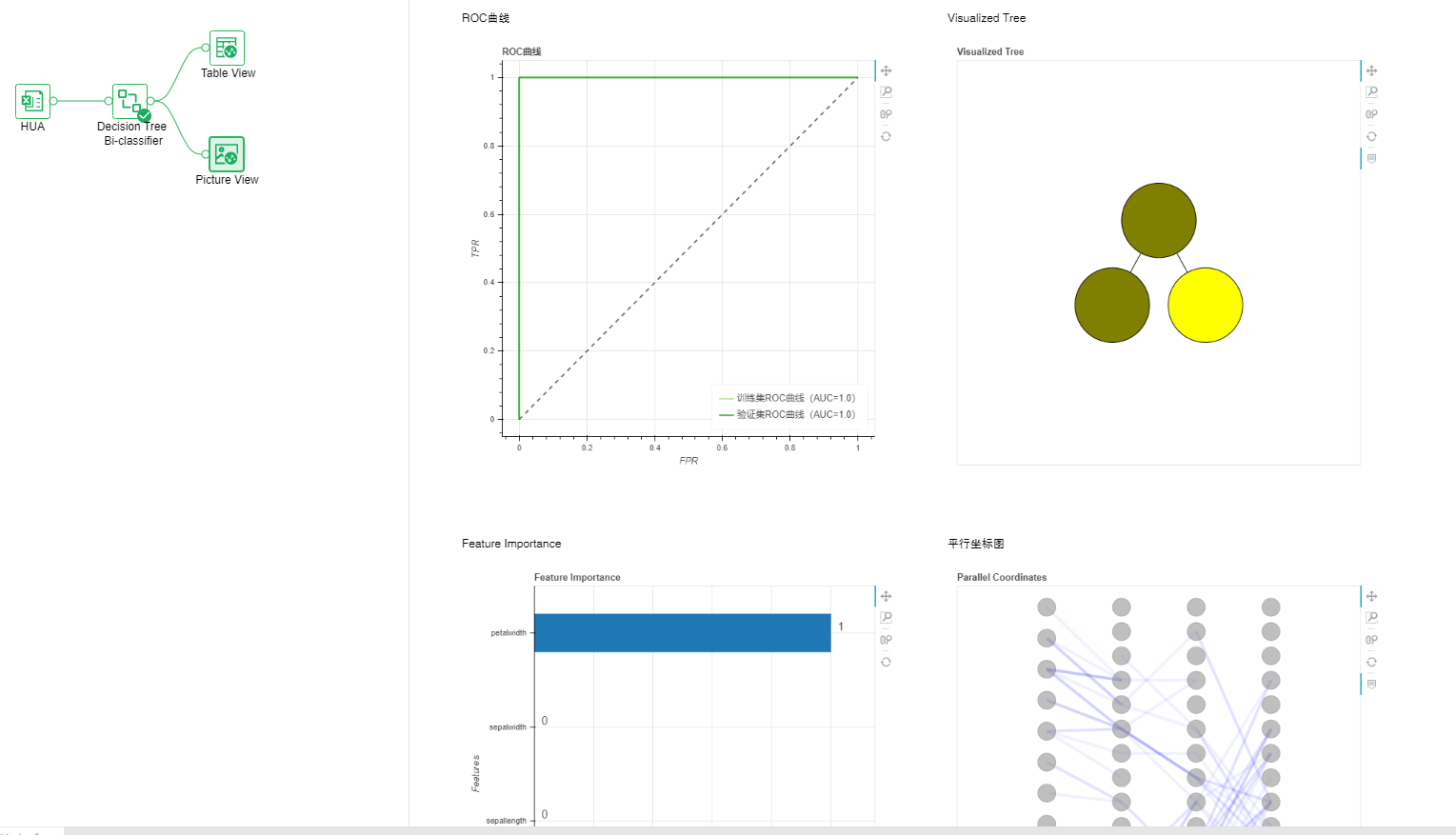
•Classification-Decision Tree Bi-Classification
Decision tree classification, the us- of decision tree algorithm for classification model training, suitable for the case where the target is listed as two.
Parameter list: Model training is carried out by setting various parameters of the decision tree classification algorithm to achieve the optimal classification effect.
Output list: models, model coefficients, performance indicators, ROC curves, PMML files.
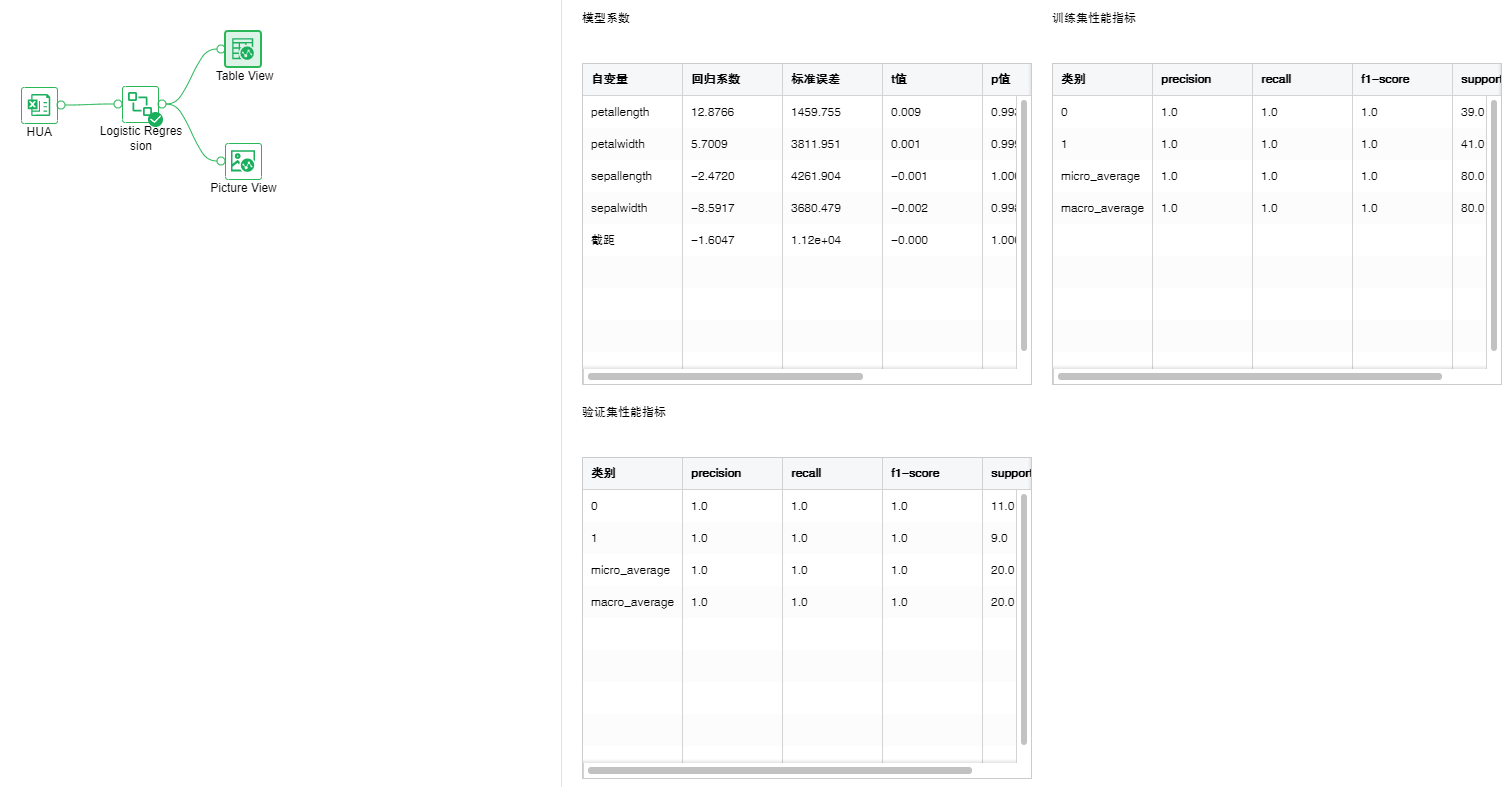
•Classification-Logistic Regression
Logistic regression is a supervised problem of machine learning algorithms, which mainly solves two classification problems.
Parameter list: select the positive example label and optimizer needed for the algorithm.
Output list: model, ROC curve, performance index, PMML file.
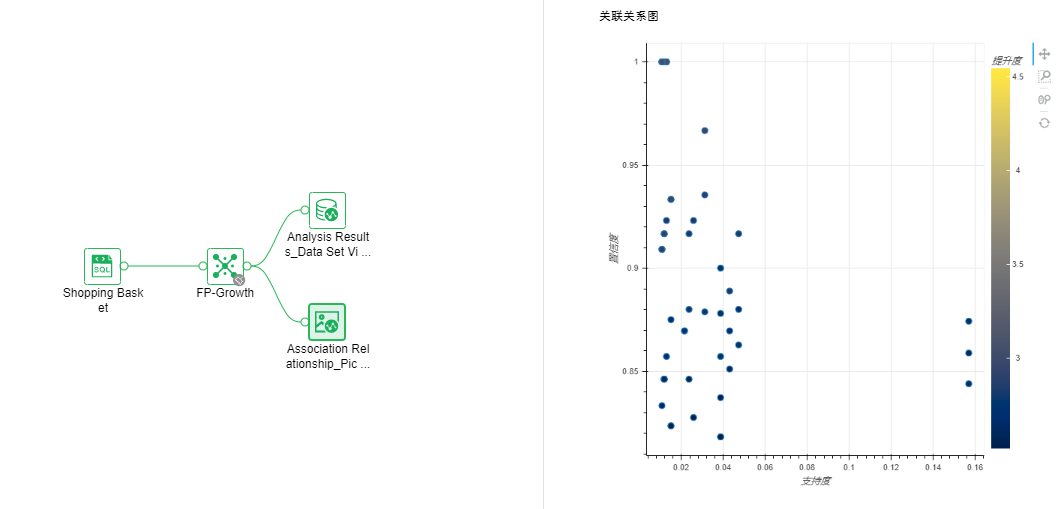
•Association Rules-FP-Growth
In transaction data, relational data or other information carriers, the process of finding frequent patterns, associations, correlations or causal structures existing in item sets or object sets mainly includes two stages: the first stage must be based on data Find all the high-frequency item groups in the collection, and then generate association rules from these high-frequency item groups in the second stage.
Parameter list: minimum support number and minimum confidence
Output list: association relationship mining results, association relationship diagram
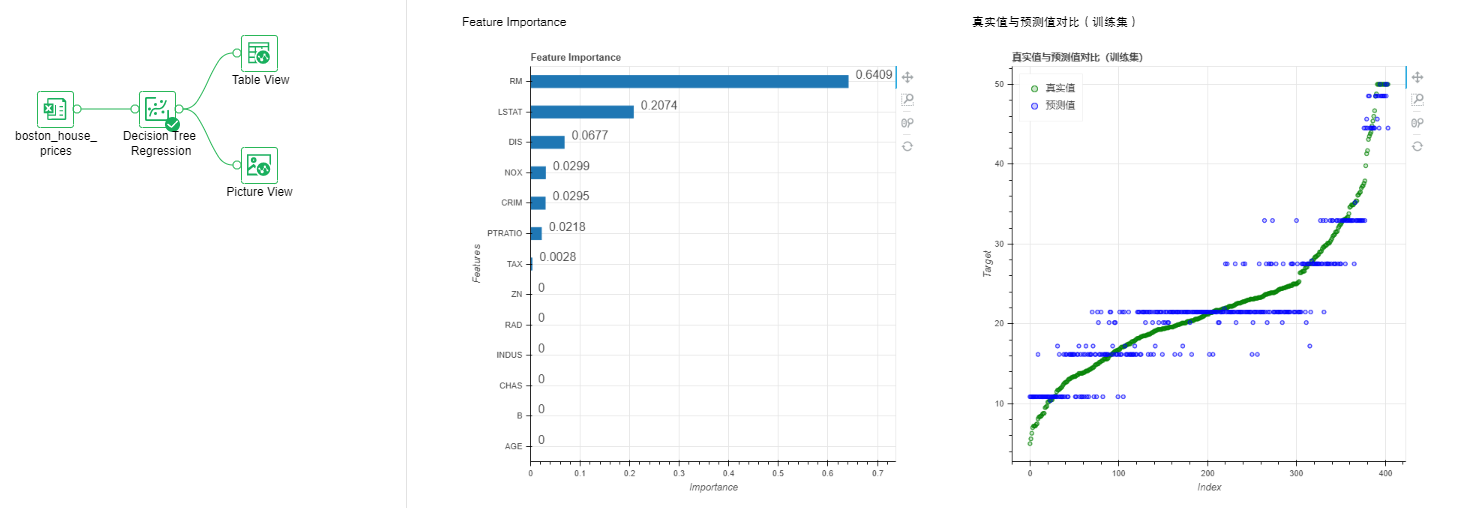
•Regression-Decision Tree Regression
Use decision tree algorithm for regression model training.
Parameter list: decision tree algorithm parameters
Output list: model, comparison of true value and predicted value, performance index, PMML file.
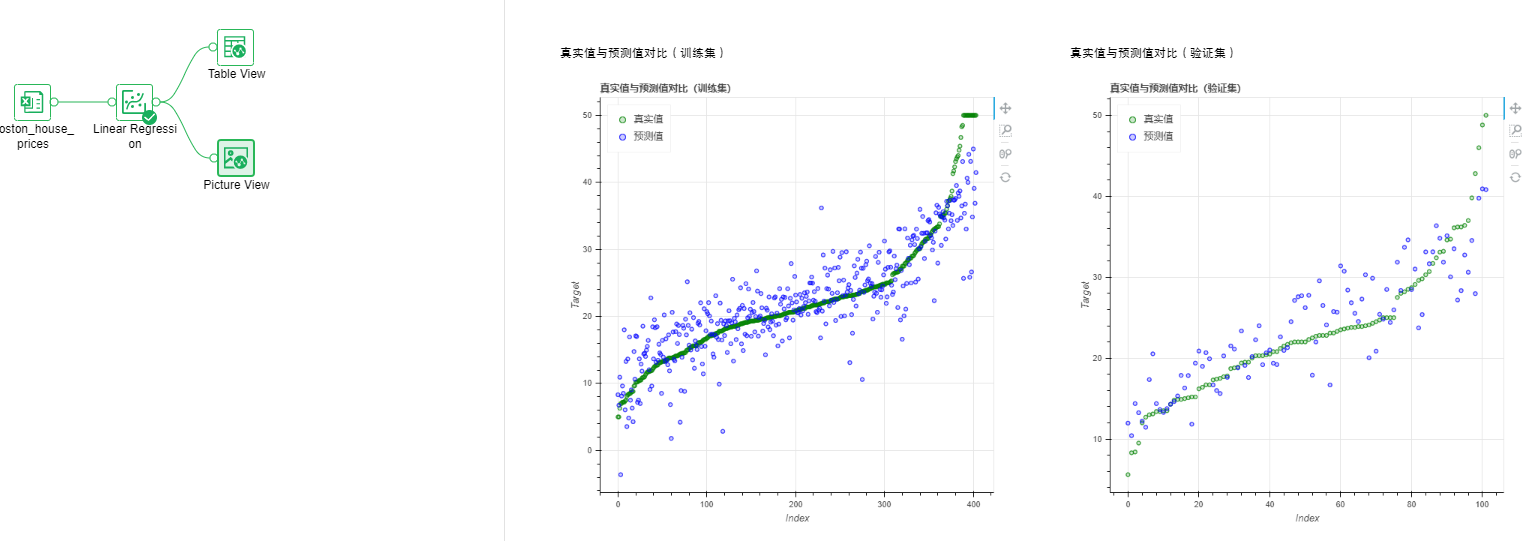
•Regression-Linear Regression
Linear regression equation is one of statistical analysis methods that uses regression analysis in mathematical statistics to determine the quantitative relationship between two or more variables.
Parameter list: proportion of training set
Output list: model, comparison of real and predicted values, performance indicators, model coefficients, PMML files.
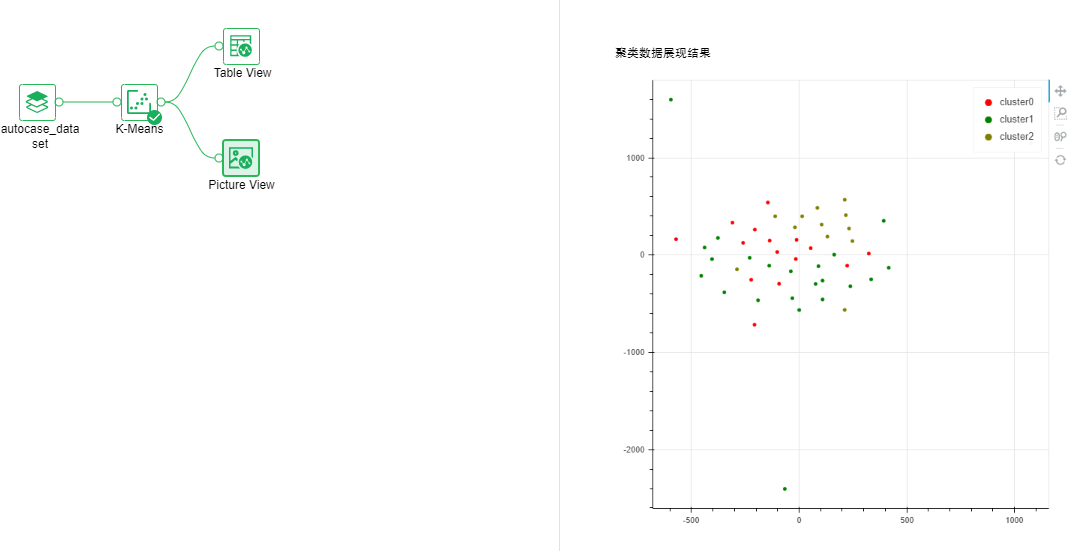
•Clustering-Kmeans Clustering
This operator can be used to classify unlabeled data and belongs to unsupervised learning.
Parameter list: proportion of training set
Output list: model, cluster centroid and performance indicators, cluster data display results.
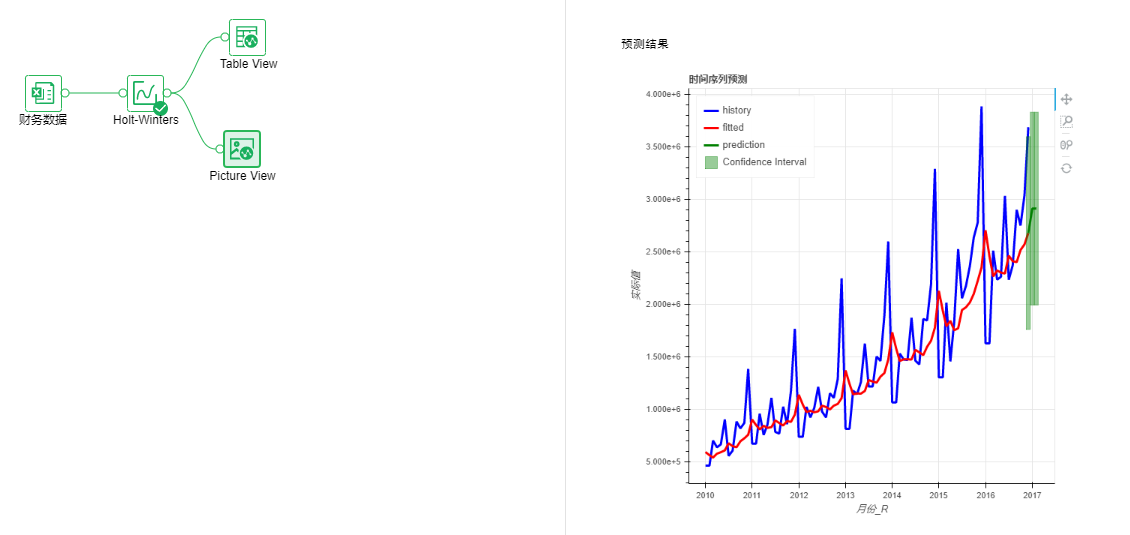
•Time Series-Holt-Winters
It is used to analyze a numerical variable that changes over time, and predict future variables based on historical data.
Parameter list: period, unit, etc. required by the timing analysis algorithm.
Output list: forecast results, forecast data, performance indicators.