|
<< Click to Display Table of Contents >> Export |
|
|
<< Click to Display Table of Contents >> Export |
|
Export contains Export to Database,Save as a Data Set,Save as Training Model,Save as a PMML File,Save as Excel and Save as CSV.
❖Export to Database
Export to database nodes connect the data class node and the algorithm node. The setup and display area contains four pages: configuration items, Metadata, Filter data, and Explore data.
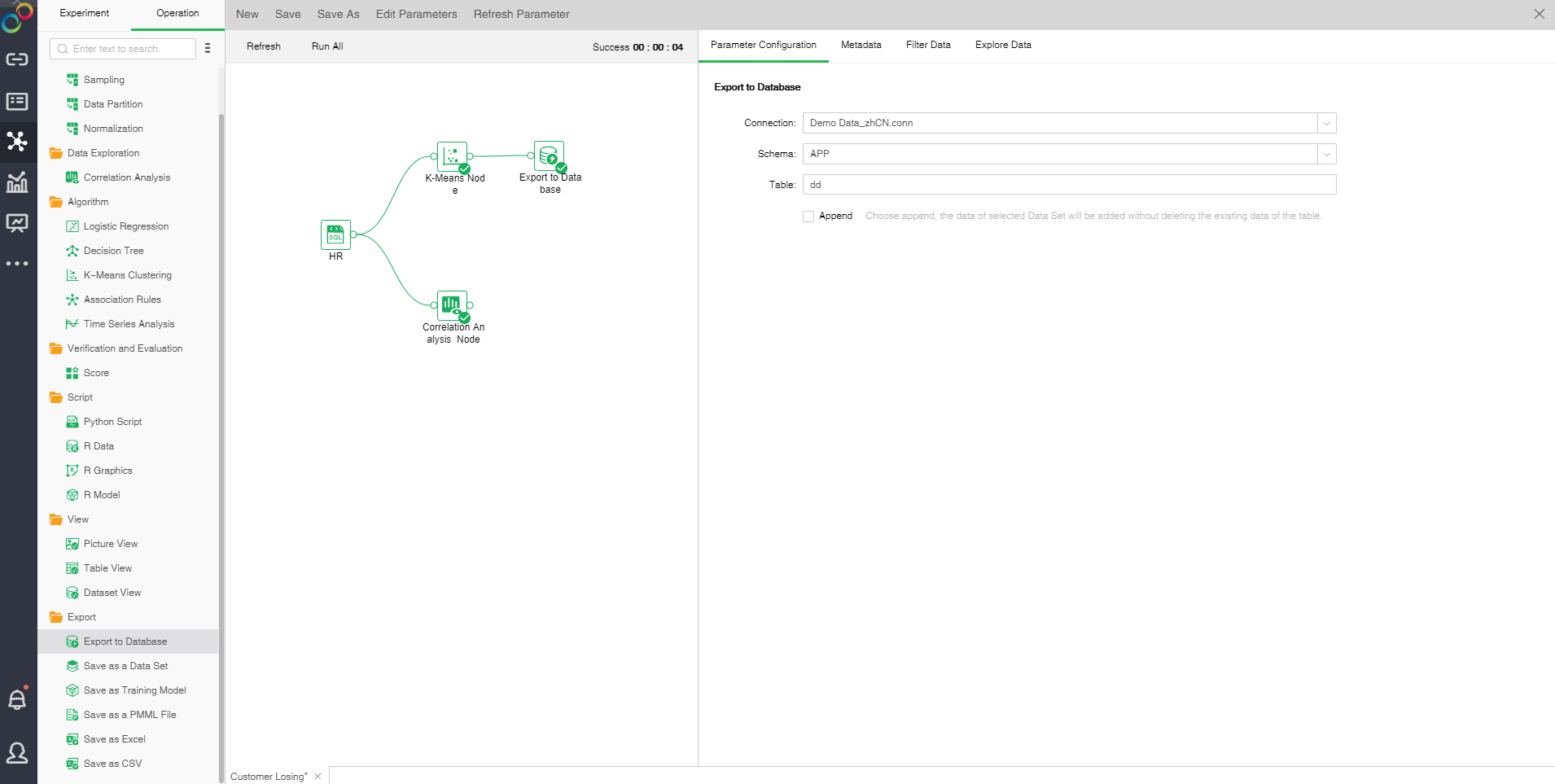
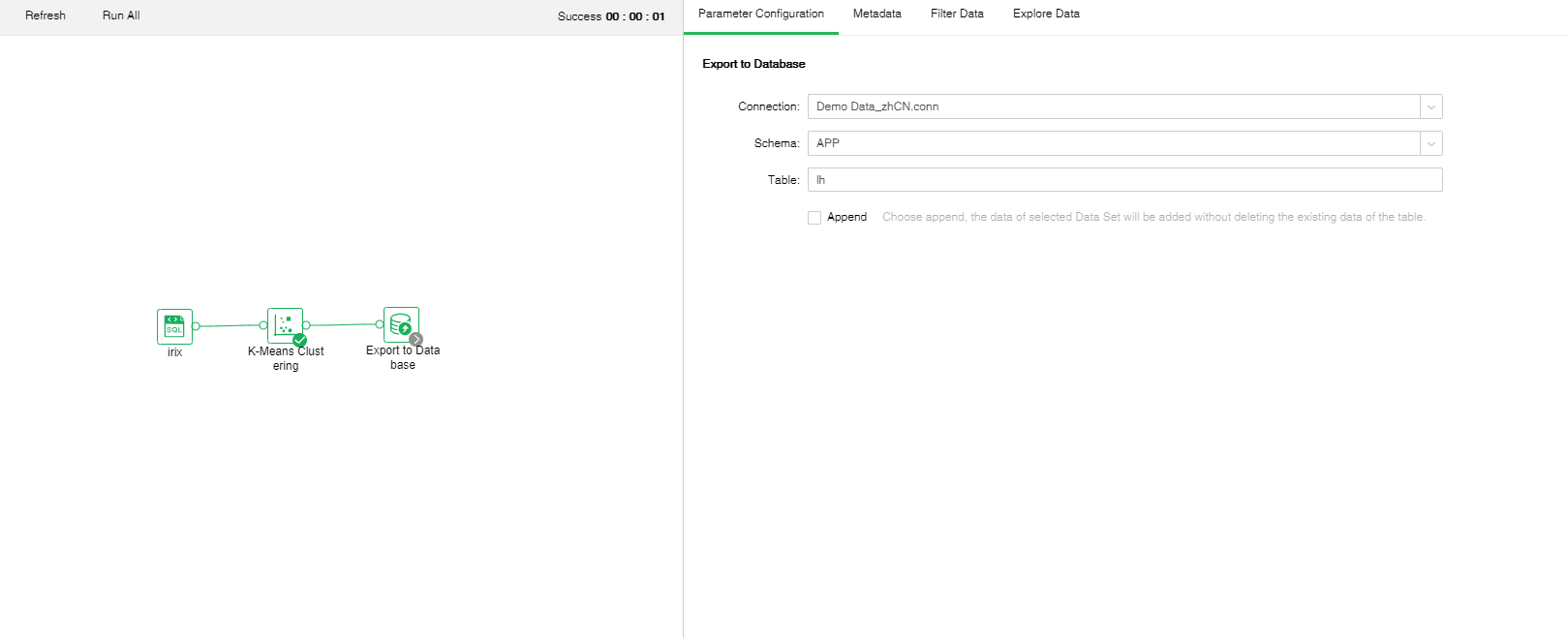
oThe configuration of Export to Database
Export to Database to select the saved Connection, check the Append, the data will be added to the table in the database without deleting the existing data in the table.
oMetadata
See Data for details
oFilter Data
See Data for details
oExplore Data
See Data for details
[Export into Database] Data of the "K-Means Clustering", "Time Series Analysis", "Score" and "R Data" nodes can be exported to a database. Import the node data into the table specified by the selected database.
Data of the "K-Means Clustering", "Time Series Analysis", "Score" and "R Data" nodes can be rapidly backfilled to the database. Please click it to view specific method for "Export into Database".
Take the case of "Case Examples/Customer Losing" for example. Right-click the "Score" and choose "Export into Database" to open the "Export into Database" dialog shown in the following figure.
1. [Model Node] Path and name of the node exported to the database. 2. [Connection] Select an existing data source as required. The following database types are supported at present: MySQL, Oracle, SQL Server, DB2, PostgreSQL, and Derby. 3. [Database] Default database of the selected data source. The following database types are supported at present: MySQL and SQL Server. 4. [Schema] Table structure mode of the selected data source. The following databases are supported: PostgreSQL, SQL Server, DB2, Oracle, and Derby. 5. [Table] Table name of the specified database. The data set result will be inserted into the table. 6. [Append] If you select "Append", the original data in the table still exist, and the data set result will be inserted directly into the table. When the user doesn't click Addition, the original data in the table will be deleted, and the result of the data set will be inserted directly into the table. |
❖Save as a Data Set
Save as a Data Set nodes connect the data class node and the algorithm node. The setup and display area contains four pages: configuration items, Metadata, Filter data, and Explore data.
Data support up to 100,000 is saved as an inline data set, and more than 100,000 is not allowed to be saved as an inline data set. The saved data set can be viewed in the Create Dataset module.
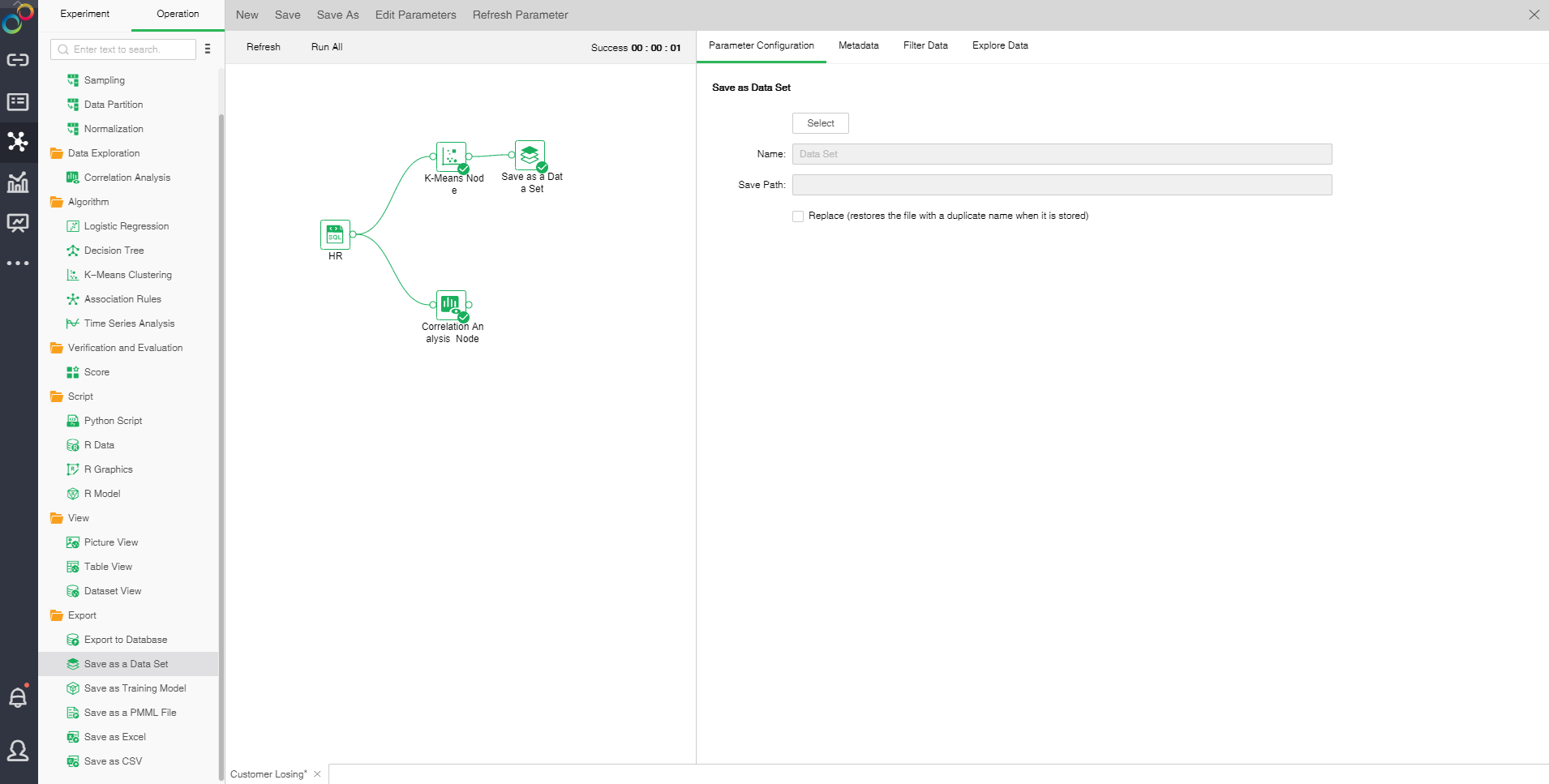
oThe configuration of Save as a Data Set
You can choose to save the path, modify the name, check the replacement, and detect that the duplicate file will be deleted when stored.
[Save as Data Set] Data of the "K-Means Clustering", "Time Series Analysis", "Score" and "R Data" nodes can be saved as a data set. Data of at most 100,000 lines can be saved as an embedded data set, and data of more than 100,000 lines cannot be saved as an embedded data set. The saved data set can be viewed in the create data set module. Click here to see an example of "Save as Data Set ."
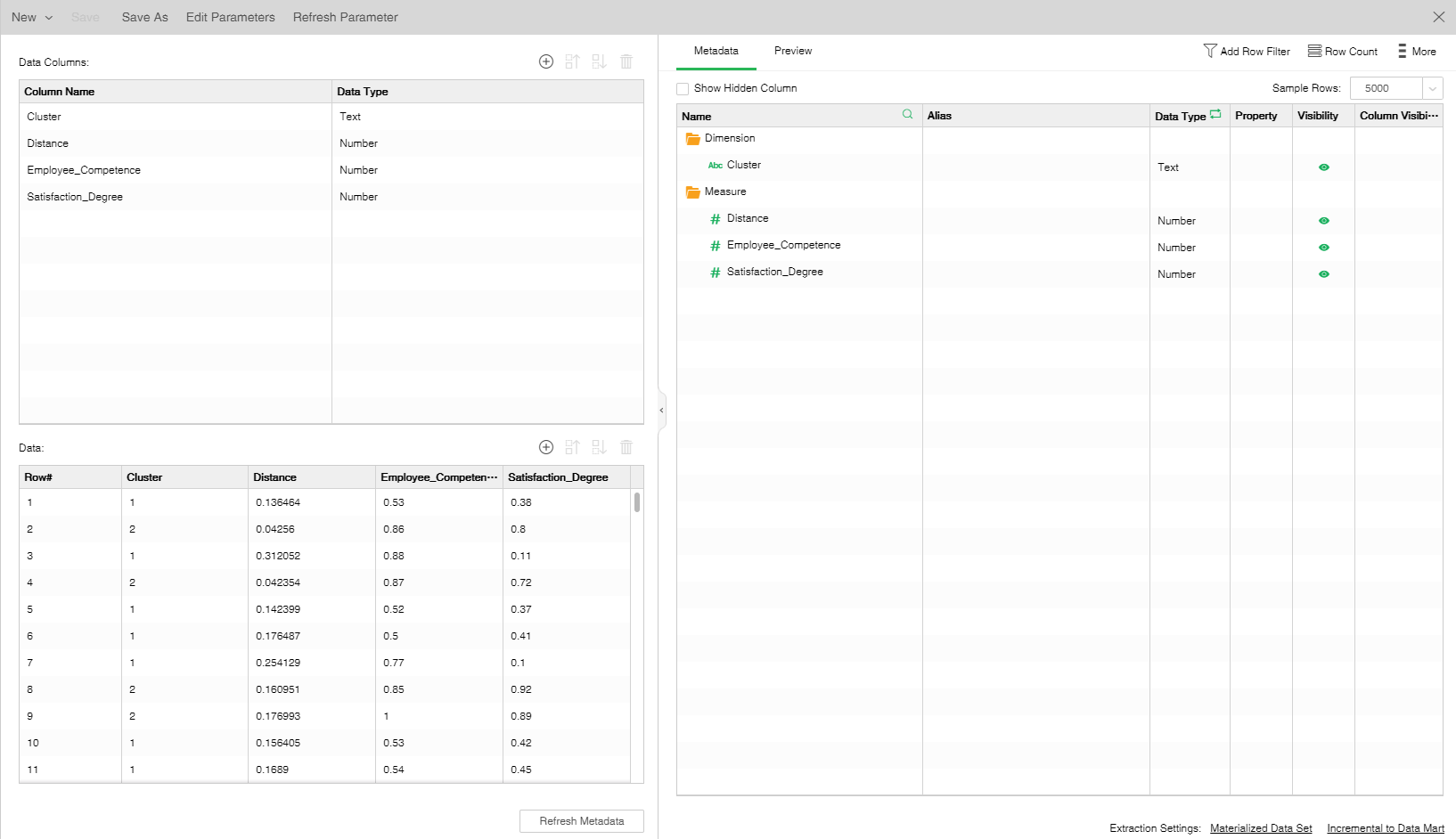
The following figure shows the metadata after the data of the "K-Means Clustering" node is saved as a data set.
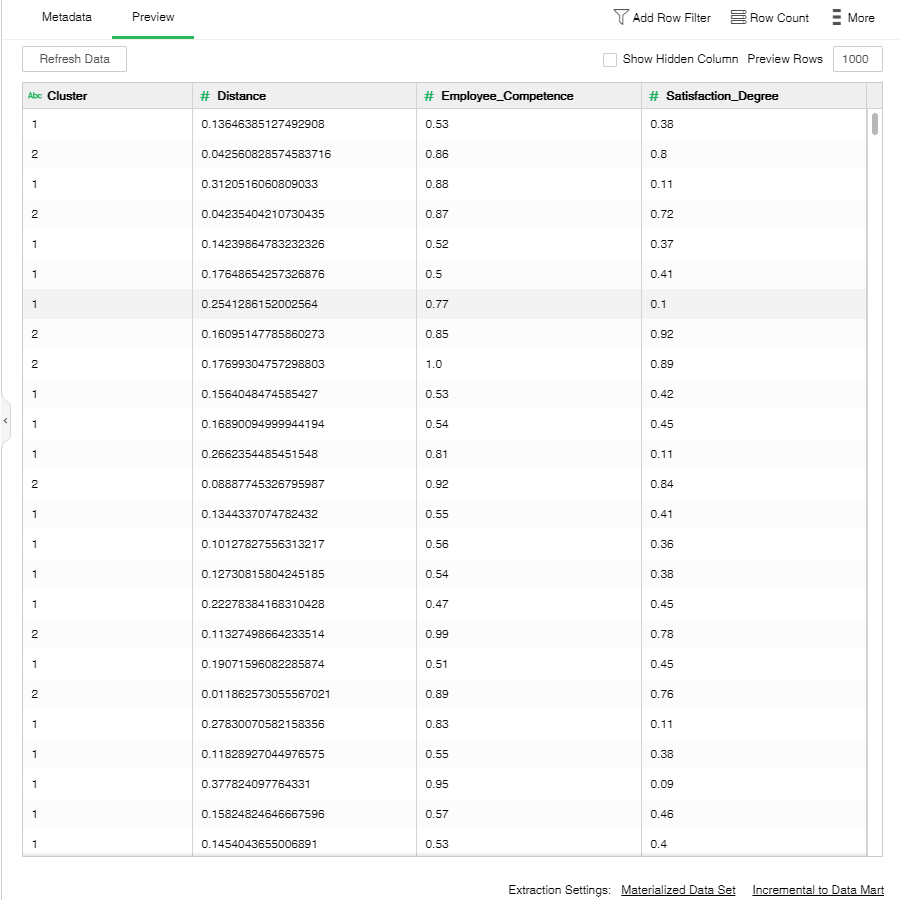
Preview data is as follows:
|
❖Save as Training Model
Save as Training Model nodes connect the algorithm node(logical regression, decision tree, K-Means clustering). The setup and display area contains : configuration items.
Data support up to 100,000 is saved as an inline data set, and more than 100,000 is not allowed to be saved as an inline data set. The saved data set can be viewed in the Create Dataset module.
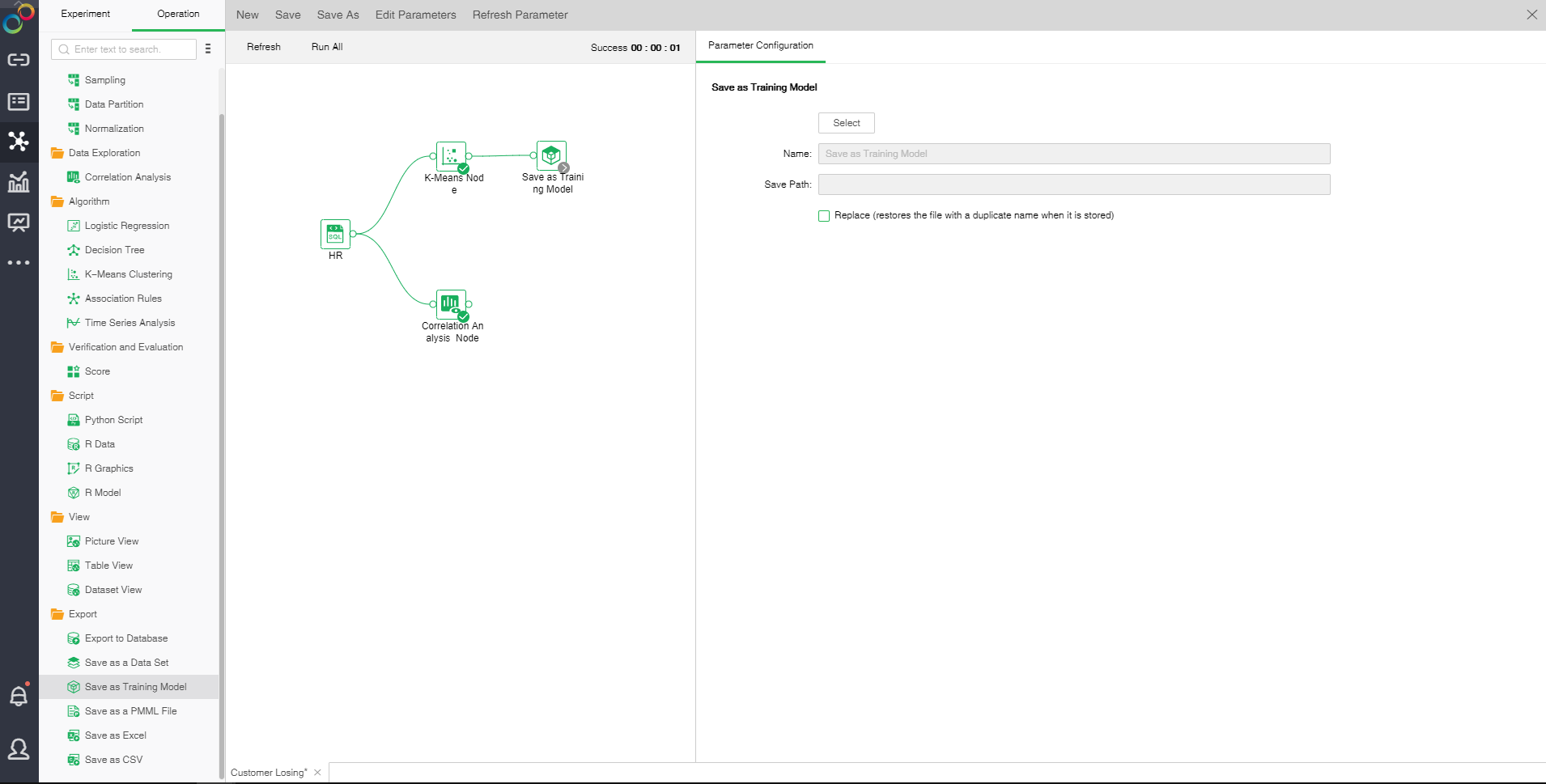
oThe configuration of Save as training model
Save as training model node to select the path to be saved, store it as a training model, check the replacement, and replace it with a duplicate file when it is stored.
[Save as Trained Model] Data of the "K-Means Clustering", "Logistic Regression" and "Decision Tree" nodes can be saved as a training model. After run successfully, it can be saved as training model. The training model is applied in the dashboard on the "Create Dashboard" page. See K-Means Clustering of "Experiment and Application of Advanced Analytic" for details.
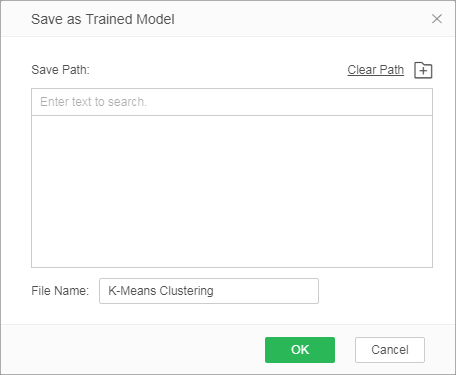
1.Save the "K-Means Clustering" node as a trained model after successful operation
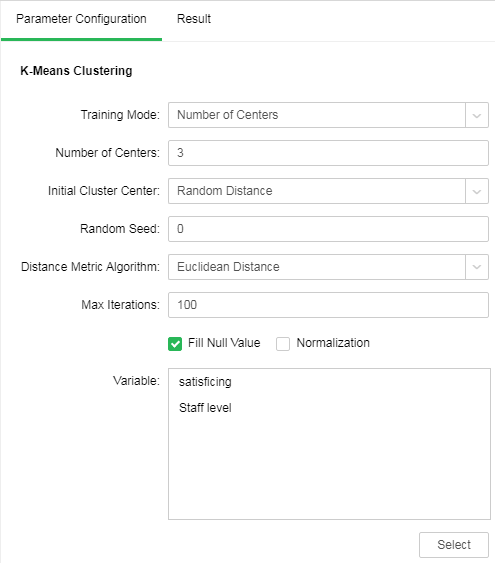
Take the case of "Case Examples/Employee Turnover" for example. Select the "K-Means Clustering" node. The following figure shows the configuration items of the node.
Click the right button to save as a training model. In the dialog pop-up saved as a training model, the user can select the path. The name can be the node name by default or the name can be modified. After click Enter, save the model to the training model folder of resource tree.
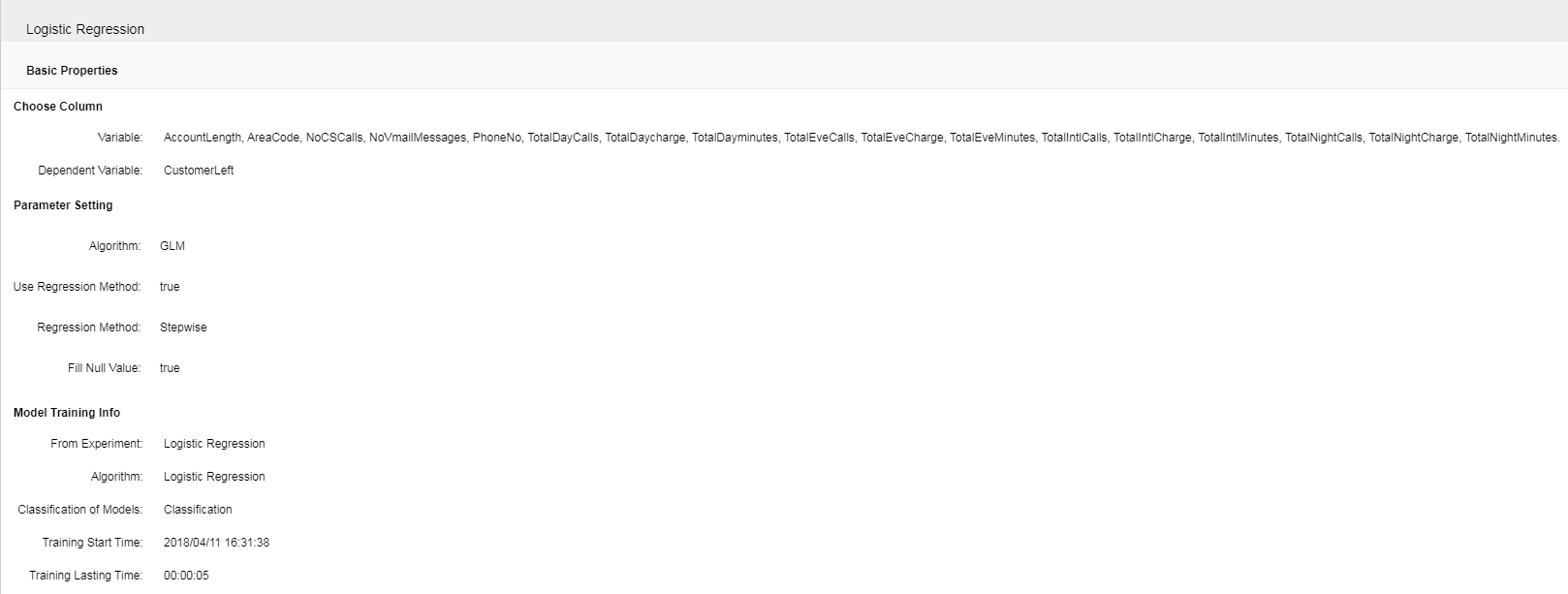
Open the saved training model "“K-Means Clustering". The display information includes three parts: Title, basic attributes and model training summary. The title is the name of training model; basic attributes are the values of all attributes in configuration items; the model training summary section shows the source, algorithm, category and time factor of the experimental node. The details are as follows:
|
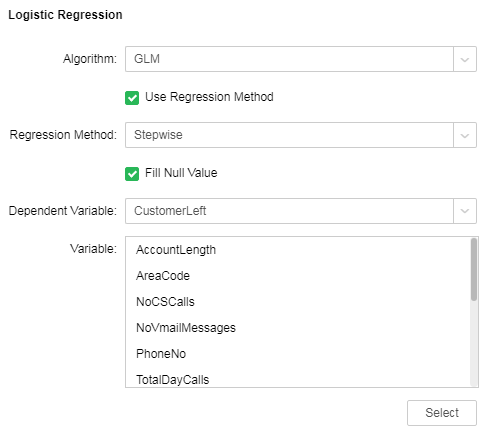
2. Save the "Logistic Regression" node as a training model after successful operation
Take the case of "Case Examples/Customer Losing" for example. Select the "Logistics Regression" node. The following figure shows the configuration items of the node.
Save it as a training model. Open the saved training model. The information is displayed as follows:
|
|
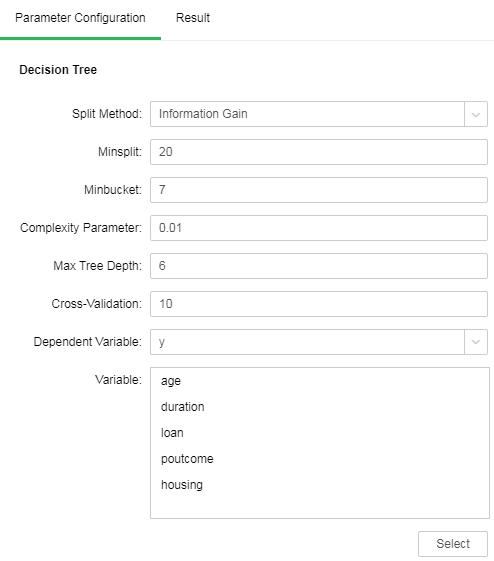
3.Save the "Decision Tree" node as a training model after successful operation
Take the case of "Case Examples/Telemarketing" for example. Select the "Decision Tree" node. The following figure shows the configuration items of the node.
Save it as a training model. Open the saved training model. The information is displayed as follows:
|
❖Save as a PMML File
Save as Training Model nodes connect the algorithm node and Script nodes(Python Script,R Model). The setup and display area contains : configuration items.
Data support up to 100,000 is saved as an inline data set, and more than 100,000 is not allowed to be saved as an inline data set. The saved data set can be viewed in the Create Dataset module.
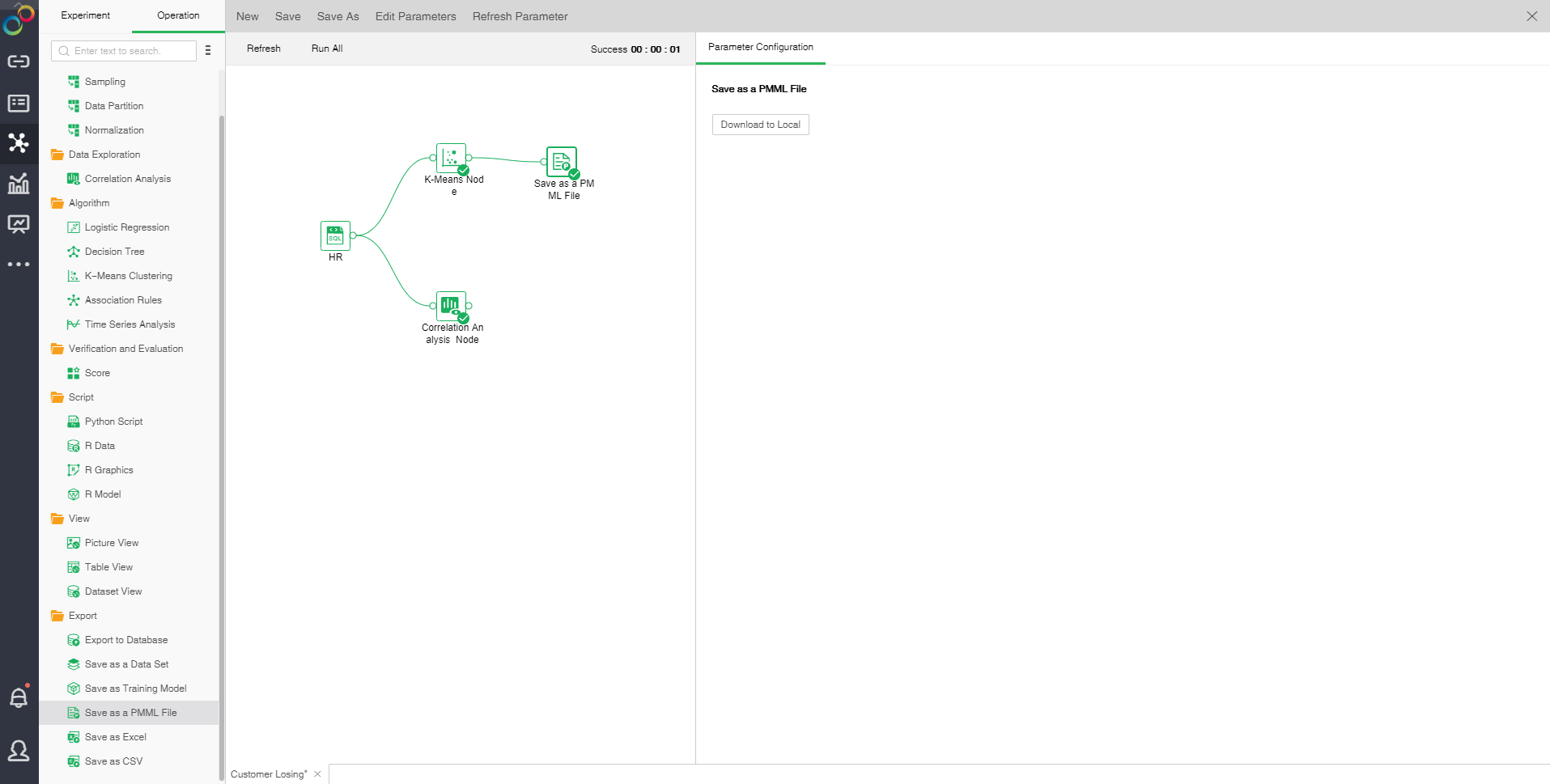
oThe configuration of Save as a PMML File
Save as a PMML File ,it will be downloaded to the server cache folder and can be downloaded locally in the configuration project.
❖Save as Excel
Save as Excel nodes connect the data class node,the Script node and the algorithm node. The setup and display area contains four pages: configuration items, Metadata, Filter data, and Explore data.
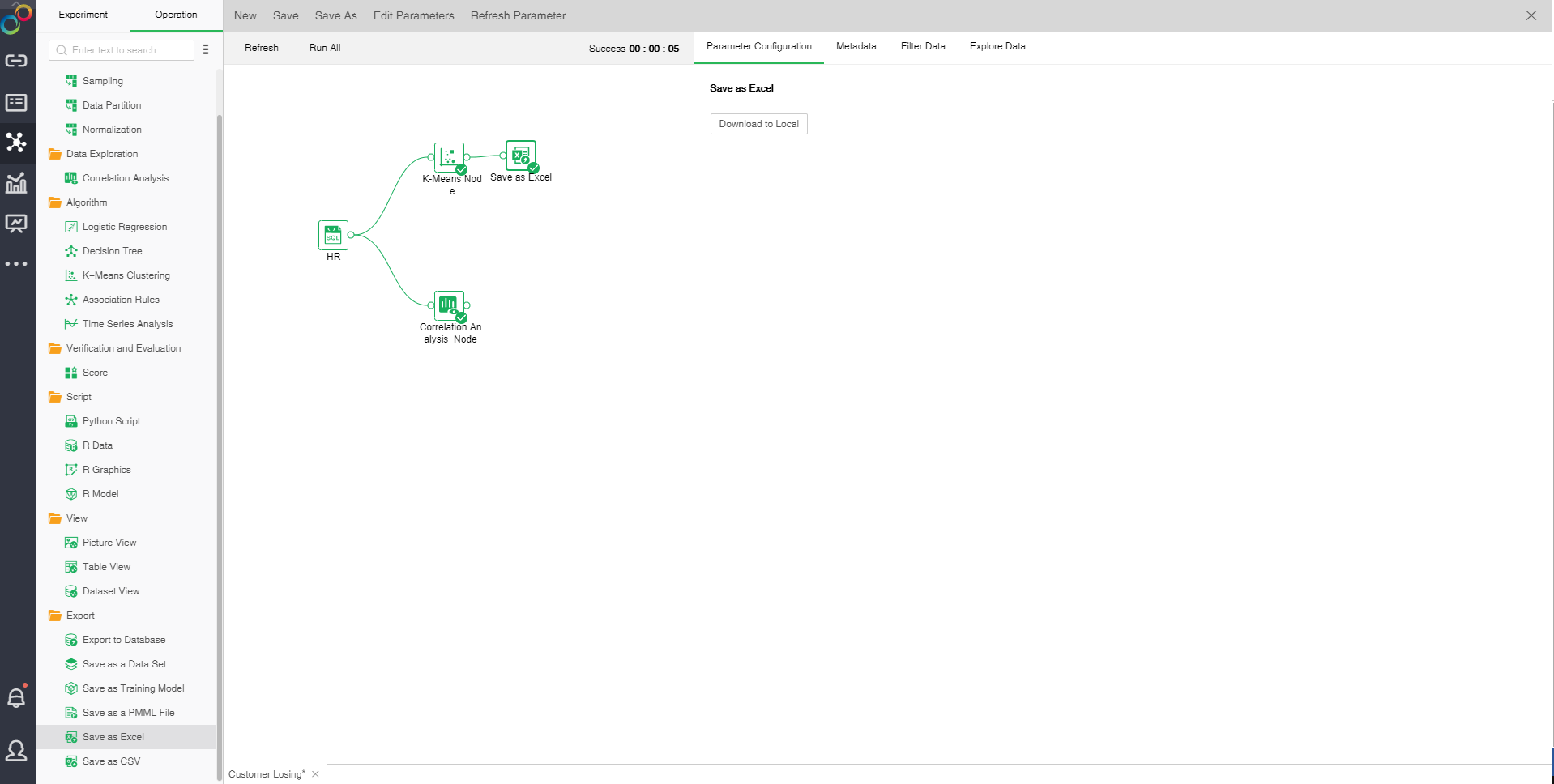
oThe configuration of Save as Excel
Save as Excel ,it will be downloaded to the server cache folder and can be downloaded locally in the configuration project.
oMetadata
See Data for details
oFilter Data
See Data for details
oExplore Data
See Data for details
❖Save as CSV
Save as CSV nodes connect the data class node,the Script node and the algorithm node. The setup and display area contains four pages: configuration items, Metadata, Filter data, and Explore data.
oThe configuration of Save as CSV
Save as CSV ,it will be downloaded to the server cache folder and can be downloaded locally in the configuration project.
oMetadata
See Data for details
oFilter Data
See Data for details
oExplore Data
See Data for details