|
<< Click to Display Table of Contents >> Association Rules |
|
|
<< Click to Display Table of Contents >> Association Rules |
|
The typical application of Association Rules is the basket analysis. It helps the company to discover the association between different commodities and get to know the customer purchasing model.
Drag the data set node "Shopping basket" to the edit area. Add Association Rules nodes which are connected to data set.
Association rules contain two algorithms: one is distributed FG-Growth, the other is non distributed Apriori.
•Apriori:
The Apriori Algorithm is one of the most influential algorithms for mining frequent itemsets of Boolean association rules. Through the analysis and mining of data Association, the mining of these information has important reference value in the decision-making process. When using the Apriori Algorithm, the bound data set can not be a Data Mart Data Set.

❖The configuration of Association Rules model
After adding the Association Rules model to the experiment, you can set the model through the "Parameter Configuration" page on the right side.
[ Range for Support(%)] The percentage value range of the support level of the rule generated by the model. If not in this range, the rule will be discarded.
[Confidence (%)] The minimum percentage value of the confidence level of the rules generated by the model. If the confidence level of the rules generated by the model is less than this number, the rules will be discarded.
[Minimum Length] The minimum number of rules generated by the model. Less than this value will be discarded.
[Maximum Length] The maximum number of rules generated by the model. If the value is greater than this value, it will be discarded.
[Variable] Select the field that you want to use as an argument from the Select Columns dialog box.
❖Run the experimental model
When the user completes the configuration of the model, clicking on the Association Rule node and selecting "run" in the right menu, the model can run, and the running time is calculated at the top right of the edit area. You can also directly click the "run all" above the edit area to run the experimental model you set.
After the operation is successful, the output of the box will be output. Click the contraction icon to check the node state and display the node successfully, as shown in the following figure.

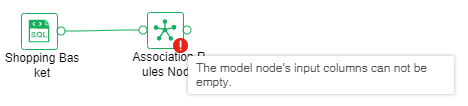
If the operation fails, the node will prompt failure, hover over the node to see the reason for the failure, as shown below.
❖Result
After the Association Rules model runs successfully, you can view the results of the experiment model through the "Result" page on the right side.
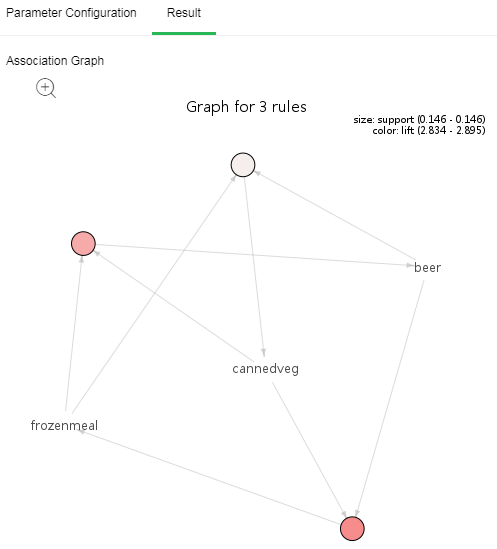
•Association Graph
The relationship diagram of each item, each circle represents a rule, the left item points to the circle, and the right item points to the circle; the size of the circle indicates the size of the support, the larger the circle, the greater the support degree, the circle color represents the lifting degree, and the color The deeper the degree of promotion, the greater.
Click the zoom in button to zoom in to see the image more clearly.
•Association Rules
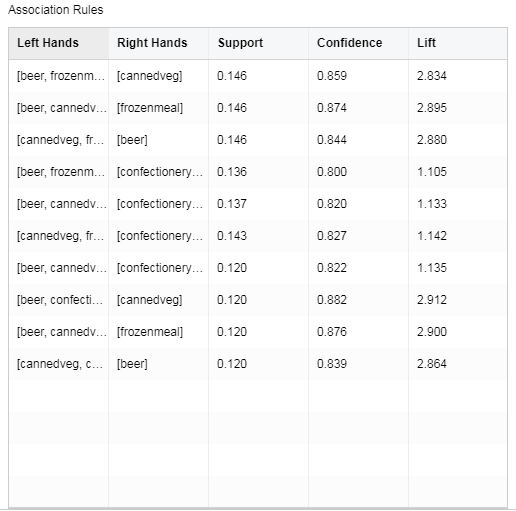
[Left Hands] The set of leading items of the rule.
[Right Hands] The set of conclusion items of the rule.
[Support] The number of occurrences of the item set divided by the total number of records.
[Confidence] The number of occurrences of the item set {X,Y} at the same time accounts for the proportion of occurrences of the item set {X}.
[Lift] Independence of measure item set {X} and item set {Y}. The larger the value, the better the model.
•FG-Growth:
•The FP-Growth algorithm is built on Apriori, but the advanced data structure is used to reduce the number of scanning, which greatly speeds up the algorithm. The FP-Growth algorithm only needs to scan the database two times, and the Apriori algorithm will scan the dataset to determine whether the given pattern is frequent for each potential frequent item set, so the speed of the FP-Growth algorithm is faster than that of the Apriori algorithm. When using the FG-Growth algorithm, the bound data set needs to be the market data set, and the data bound to the column must be separated by a comma.
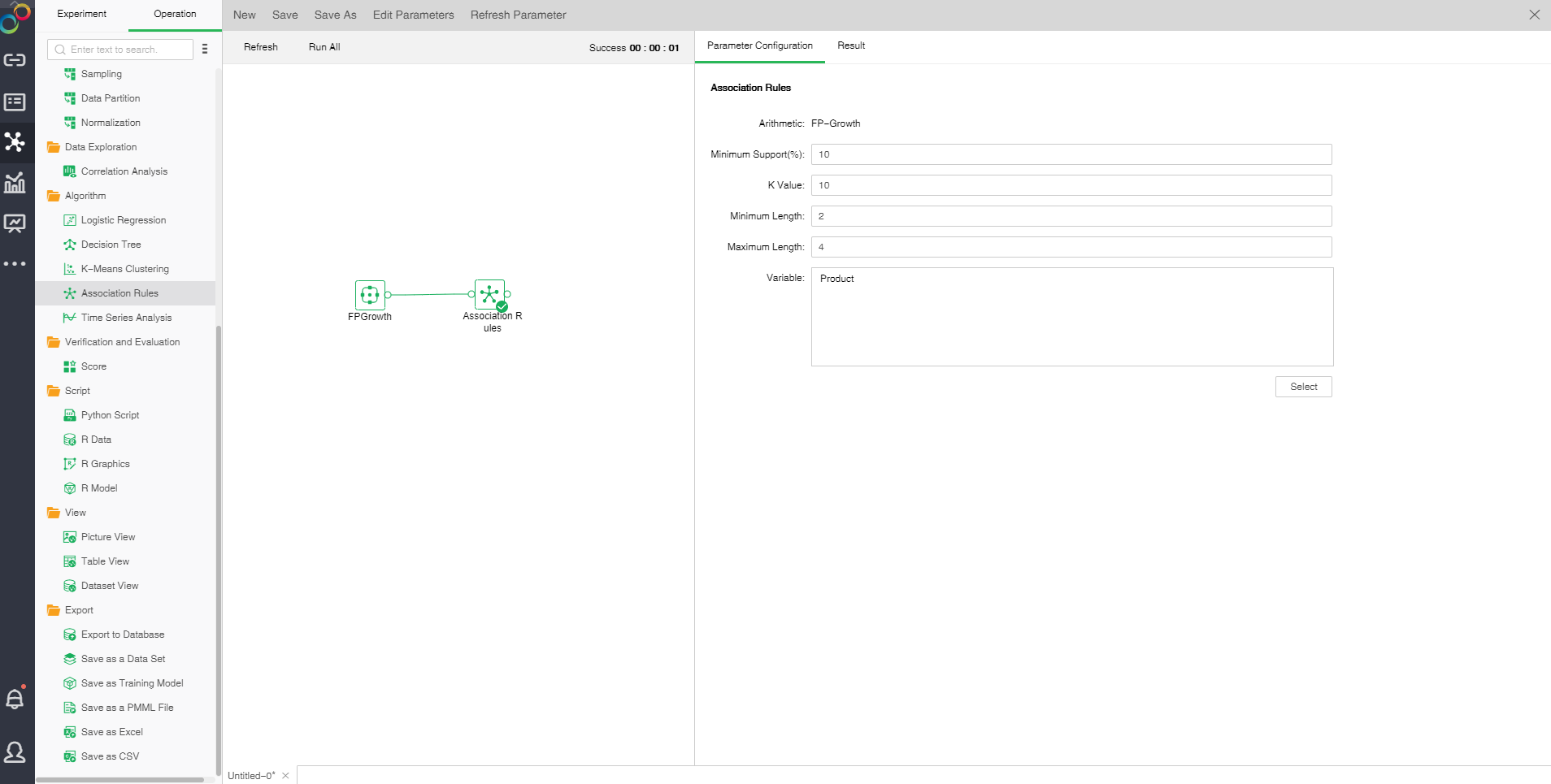
❖The configuration of Association Rules model
After adding the association rule model to the experiment, the model can be set up through the "configuration project" page on the right.
[Minimun Support(%)]Minimum support is used to measure the frequency of a set in the original data. If the rules are not in this range, the rules will be abandoned.
[K Value]the number of rows displayed by the model generated by the model.
[Minimum Length]number controls minimum length of frequent itemsets, less than this value will be discarded.
【Maximum Length】controls the maximum length of frequent itemsets, greater than this value will be discarded.??/text>
【Variable】select fields from the selection column dialog box as independent variables.
❖Run the experimental model
When the user completes the configuration of the model, we can choose to connect "Save as Trained Model" node and run , the model can run, and the running time is calculated at the top right of the edit area. You can also directly click the "run all" above the edit area to run the experimental model you set.
After the operation is successful, the output of the box will be output. Click the contraction icon to check the node state and display the node successfully, as shown in the following figure.
If the operation fails, the node will prompt failure. The mouse can suspend the node to see the cause of failure, as shown in the following figure.

❖Result
After the successful operation of the Association Rule model, the result of the experimental model can be viewed through the "result display" page on the right side.
•Association Rule
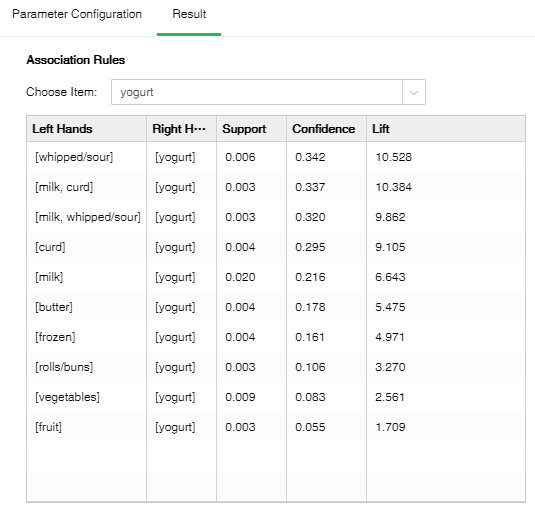
[Choose item] one of the item names contained in the fields in the database.
[Left Hands] The set of leading items of the rule.
[Right Hands] The set of conclusion items of the rule.
[Support] The number of occurrences of the item set divided by the total number of records.
[Confidence] The number of occurrences of the item set {X,Y} at the same time accounts for the proportion of occurrences of the item set {X}.
[Lift] Independence of measure item set {X} and item set {Y}. The larger the value, the better the model.
❖Save as a data set
Data less than 100,000 can be saved as embedded data sets, and over 100,000 are not allowed to be saved as embedded data sets. Saved data sets can be viewed in the Create Data Sets module.
❖Export to database
Imports the node data into the table specified by the selected database.
❖Export PMML
When the model node has been trained , the corresponding PMML file will be generated. Users can choose to connect "Save as a PMML File" node then run it, and export the generated PMML file to the local area, and then use it for other platforms.
Note: Only K-Means clustering model of Apriori algorithm supports exporting PMML.
❖Association Rules node renaming
In the right-click menu of the Association Rules node, select "Rename" to rename the node.
❖Delete the Association Rules node
In the right-click menu of the Association Rules node, select "delete" or click the delete key on the keyboard to delete the node and the node's input and output connections.
❖Refresh the Association Rules node
In the right-click menu of the Association Rules node, select "Refresh" to update the synchronization data or parameter information.