|
<< Click to Display Table of Contents >> Sampling |
|
|
<< Click to Display Table of Contents >> Sampling |
|
Sampling is a common method for analysis of data object subset. In statistics, sampling is used for data realization investigation and final data analysis. Sampling is also useful in data mining. However, in statistics and data mining, the motivations for sampling are different. Sampling is used in statistics process since the entire data set is too expensive and time consuming. And sampling is also used in data mining since the data treatment is too expensive and time consuming. In some cases, the sampling algorithm can compress the data so that it is possible to use better but more expensive data mining algorithms.
Drag a data set and a sample node to the edit area. Connect the data set and the sampling node.
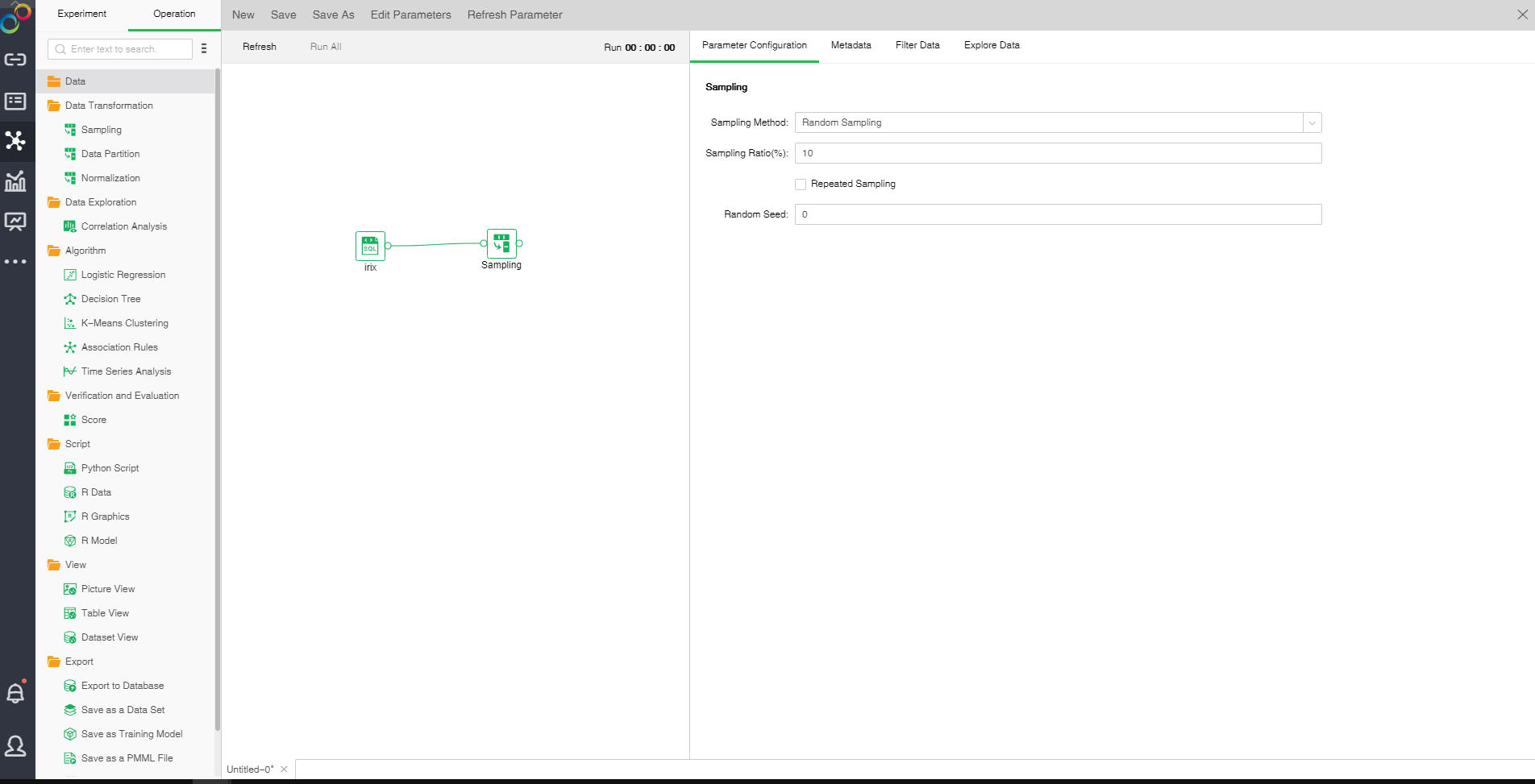
❖Sampling configuration method
After adding the sampling node to the experiment, you can set the sampling of the data through the "Parameter Configuration" page on the right side.
There are three sampling modes: Random Sampling, Sequential Sampling and Stratified Sampling.
•Random Sampling
Random Sampling follows random principle. Namely ensure that every object in the population has a known and non-zero probability being selected as the object of the study. Extract sample number of rows of sampling rate from data set node to ensure the representativeness of the sample.
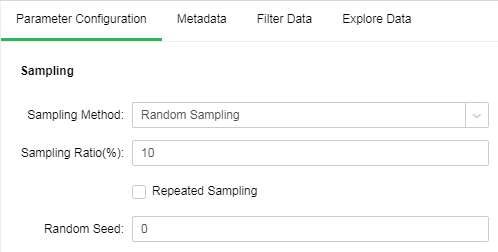
[Sampling Ratio(%)] Sampling rate extracted.
[Repeated Sampling] When it is not selected, each selected item will be immediately deleted from all the objects that make up the statistical population. When it is selected, the objects will not be deleted from the population when it is selected. In case of repeated sampling, the same object may be extracted for multiple times. It is default as not selected.
[Random Seed] Generate random number seed. The default value is 0.
•Sequential Sampling
Sequential Sampling takes the first N rows of data set as the result set.
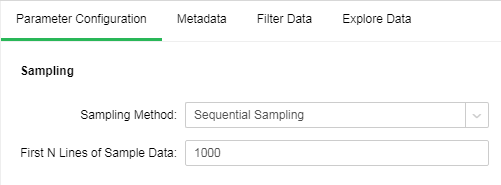
[First N Lines of Sample Data] the number of rows to be sampled in Sequential Sampling The default value is 1000.
•Stratified Sampling
Stratified Sampling starts sampling from predefined groups (namely different values of the selected column). Each group is sampled at the sampling rate.
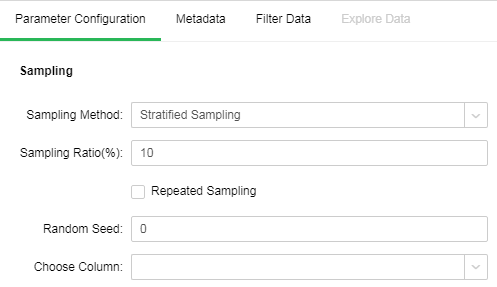
[Choose Column] Layered column. Extract sample rows according to sampling rate by take different values of group.
Other parameters please refer to the Random Sampling.
After setting the sampling method, you can view the sampled metadata, filter the data, and explore the sampled data. For details, see the section Add Data .
❖Sample node rename
In the sampling node's right-click menu, select "Rename" to rename the node.
❖Delete the sampling node
In the sampling node's right-click menu, select "Delete" or click the keyboard delete key to delete, you can delete the node and node input and output connections.
❖Refresh the sampling node
In the sampling node's right-click menu, select "Refresh" to update the synchronization data or parameter information.