|
<< Click to Display Table of Contents >> Data Partition |
|
|
<< Click to Display Table of Contents >> Data Partition |
|
Generally, when perform predictive analysis, the data will be divided into two parts. One part is training data, which is used to build the model. And the other part is test data which is used for model testing. ??Data Partition is to divide the data in data set to validation set and training set.
Drag a data set and a Data Partition node to the edit area. Connect the data set and Data Partition node.
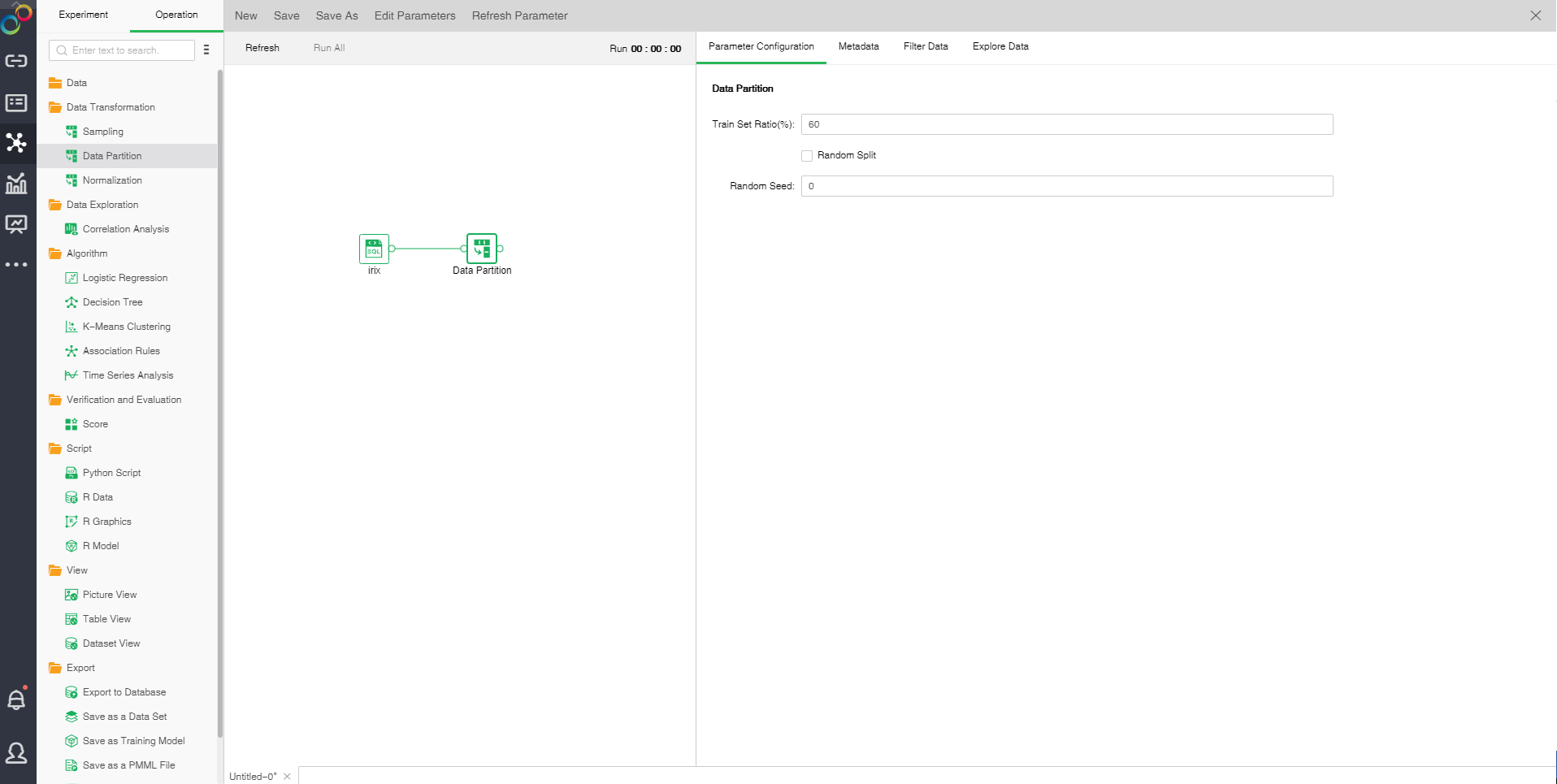
❖Data Partition configuration method
After adding the Data Partition node to the experiment, you can set the Data Partition through the "Parameter Configuration" page on the right side.
[Train Set Ratio (%)] proportion of train sets to total samples. The default value is 60.
[Random Split] When it is not selected, extract the training set in order. Randomly selected training sets when selected. It is default as not selected.
[Random Seed] Generate random number seed. The default value is 0.
After setting up the Data Partition, you can view the partitioned metadata, filter the data, and explore the data. For details, see the section Add Data .
❖Data partition node renaming
In the right-click menu of the data partition node, select "Rename" to rename the node..
❖Delete data partition node
In the right-click menu of the data partition node, select "Delete" or click the delete key on the keyboard to delete the input and output connections of nodes and nodes.
❖Refresh the data partition node
the right-click menu of the data partition node, select "Refresh" to update the synchronization data or parameter information.