|
<< Click to Display Table of Contents >> Save as Training Model |
|
|
<< Click to Display Table of Contents >> Save as Training Model |
|
Save as Training Model nodes connect the algorithm node(logical regression, decision tree, K-Means clustering, Python Script, R model). The setup and display area contains : configuration items.
Data support up to 100,000 is saved as an inline data set, and more than 100,000 is not allowed to be saved as an inline data set. The saved data set can be viewed in the Create Dataset module.
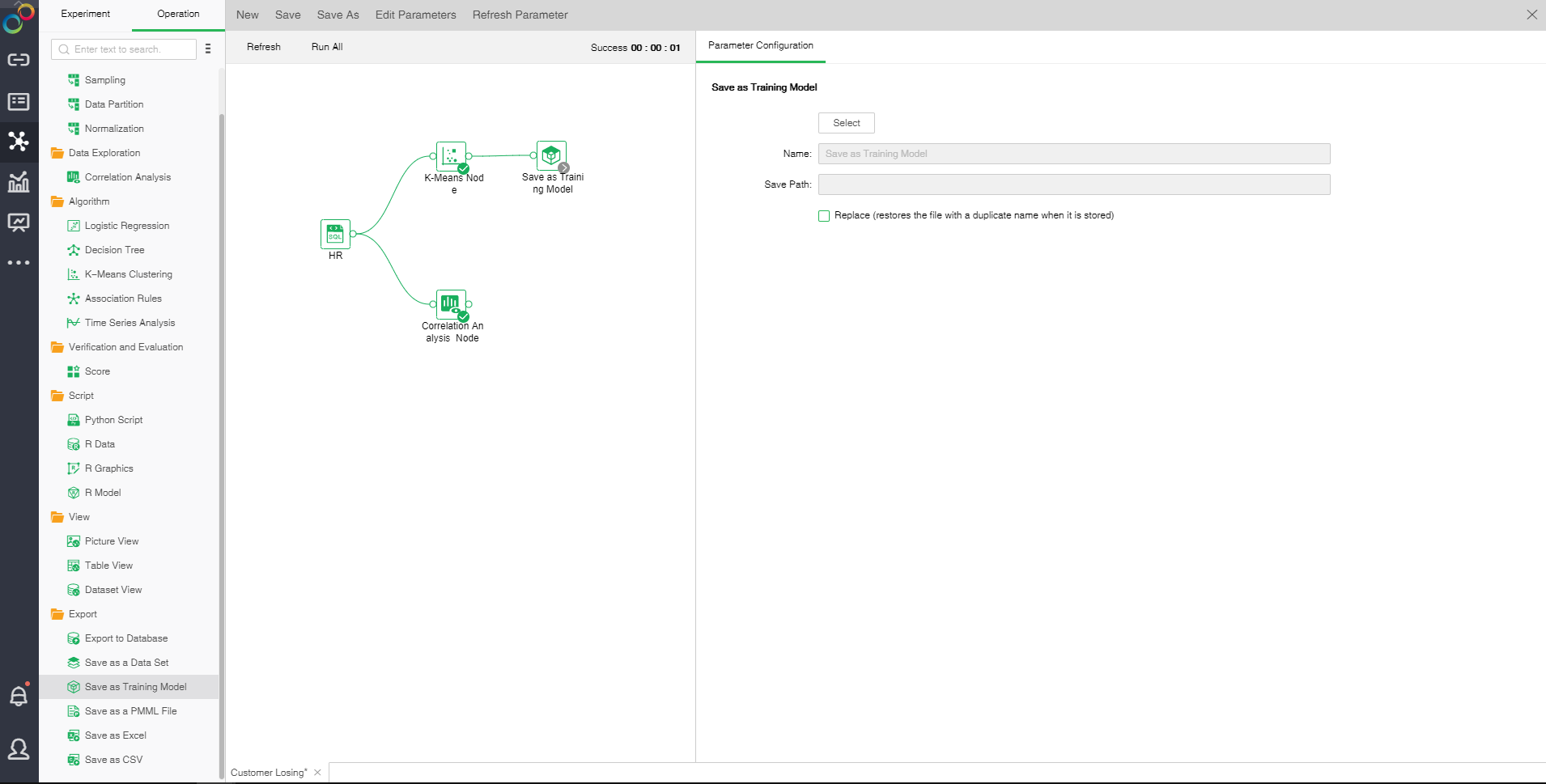
❖Configuration of Save as Training Model
Save as training model node to select the path to be saved, store it as a training model, check the replacement, and replace it with a duplicate file when it is stored.
❖Run Save as a Data Set
In the context menu of the export to the Save as Training Model node, select "Run" to run the node and the predecessor node.
❖Rename Save as Training Model
In the right-click menu of the Save as Training Model node, select "Rename" to rename the node.
❖Refresh Save as Training Model
In the right-click menu of the Save as Training Model node, select "Refresh" to update the synchronization data or parameter information.
❖Save as Composite Node
In the right-click menu of node, select "Save as composite node" to save the selected node as a combined node to realize multiplexing nodes. The parameters of the saved node are consistent with the original node.
❖Copy/Cut/Paste/Delete Export Node
The export node's right-click menu supports copy, cut, paste, and delete operations.
【Copy】 Copy export node
【Cut】Cut export node
【Paste】 After selecting copy, right-click on the canvas blank to paste and copy the export node.
【Delete】 Click the node right-click menu to click Delete, or click the keyboard delete button to delete, to delete the input and output connections of nodes and nodes.
K-Means clustering, Logistic regression, Decision tree, Python script and R model can be saved as training models. After running successfully, it can be saved as a training model. The training model is applied in the dashboard of the production report module. You can refer to the K-Means clustering case introduction in the in-depth analysis experiment and application chapter.